{kind=link}
NetSentinelX is an advanced Network Intrusion Detection System (NIDS) that leverages machine learning models such as XGBoost, Random Forest, SVM, and others to detect normal and anomalous network traffic. This project is trained on the NSL-KDD dataset and explores both supervised and unsupervised approaches for effective anomaly detection.
This project uses the NSL-KDD dataset, a popular benchmark dataset for network intrusion detection research.
-
Source: The dataset is publicly available on Kaggle at NSL-KDD Dataset.
-
Description: The NSL-KDD dataset is an improved version of the original KDD Cup 1999 dataset. It contains a diverse set of network connection records, each labeled as either normal or as an attack of a specific type. This dataset is widely used for evaluating intrusion detection systems (IDS).
-
Dataset Components:
- Training and Testing sets: Separate CSV files for training and testing, ensuring evaluation on unseen data.
- Features: Each record contains 41 features representing various aspects of network traffic and connection behavior,
including protocol type, service, flag, source bytes, destination bytes, and more.
- Labels: Each record is labeled either as “normal” or a specific attack category (such as DoS, Probe, R2L, U2R).
- Preprocessing Notes:
- Categorical features such as protocol_type, service, and flag are encoded using label encoding.
- Numerical features have missing values handled by imputation.
- Features are scaled using Min-Max scaling for better model performance.
- the labels are binarized for anomaly detection: normal → 0 (Normal), All other attack types → 1 (Anomaly).
- Why NSL-KDD? The NSL-KDD dataset addresses some of the issues present in the original KDD dataset, such as redundant records and imbalanced classes, making it more suitable for machine learning experiments.
- Data preprocessing with categorical encoding, scaling, and missing value handling.
- Multiple ML models: XGBoost, Random Forest, SVM, KNN, Elliptic Envelope.
- Binary classification: normal vs anomaly detection.
- Model evaluation with classification reports and confusion matrices.
- Feature importance visualization.
- Comparative analysis of models performance.
NetSentinelX/
│
├── data/ # Dataset files (raw and processed)
├── notebooks # Jupyter notebooks with code and analysis
├── reports # Classification reports and plots
├── requirements.txt # Dependencies
├── README.md # Project overview and instructions
└── LICENSE # License file
- Clone the repo:
git clone https://github.com/yuvrajtiwary-bitmesraece/NetSentinelX.git
cd NetSentinelX
- Create a virtual environment (recommended):
python3 -m venv venv
source venv/bin/activate # For Windows: venv\Scripts\activate
- Install dependencies:
pip install -r requirements.txt
- Prepare the data: Place the NSL-KDD dataset files inside data/ folder.
- Run preprocessing script or notebook to clean and encode data.
- Train models by running training scripts/notebooks.
- Evaluate and visualize results using evaluation scripts/notebooks.
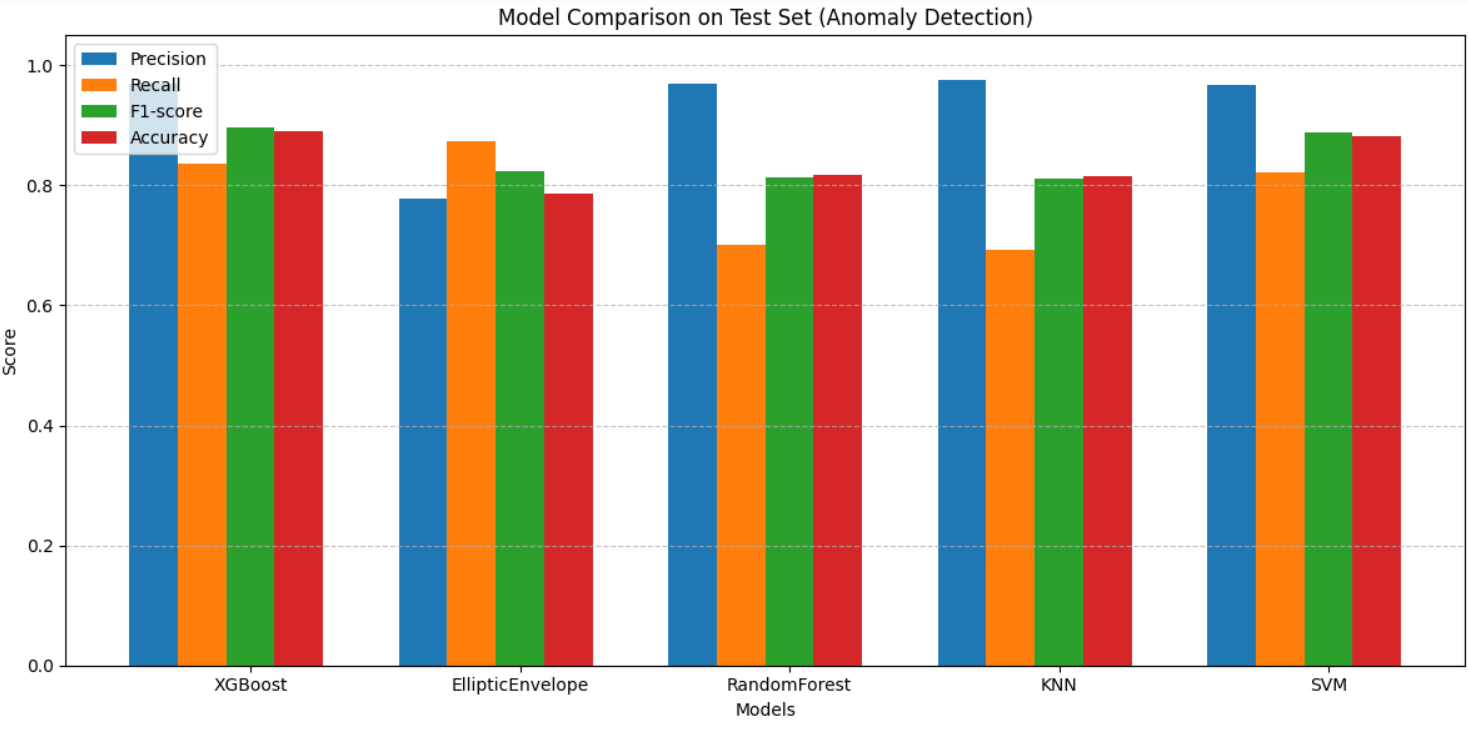
Model performances on test set (Anomaly detection):
- XGBoost: High precision, recall, and F1-score.
- Random Forest: Balanced accuracy and robustness.
- SVM, KNN: Competitive but less performant.
- Elliptic Envelope: Unsupervised baseline.
Below is the final comparison of classification reports provided by different models
Grateful for your time and attention — it truly means a lot!