You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
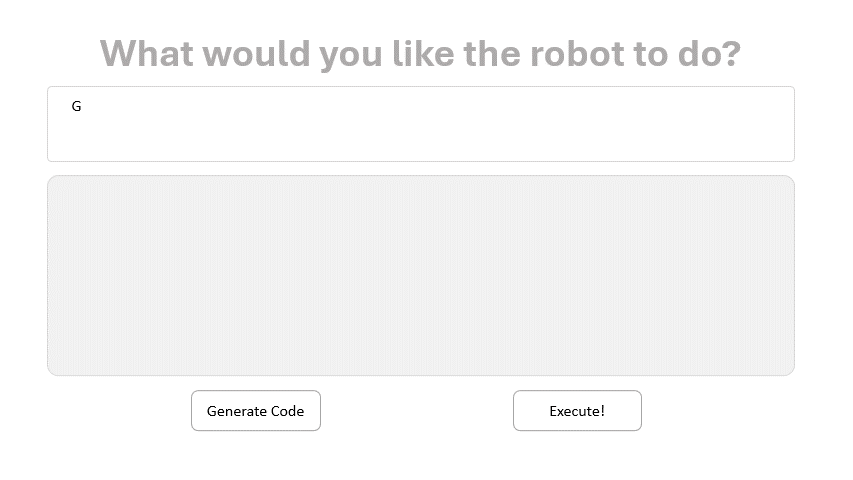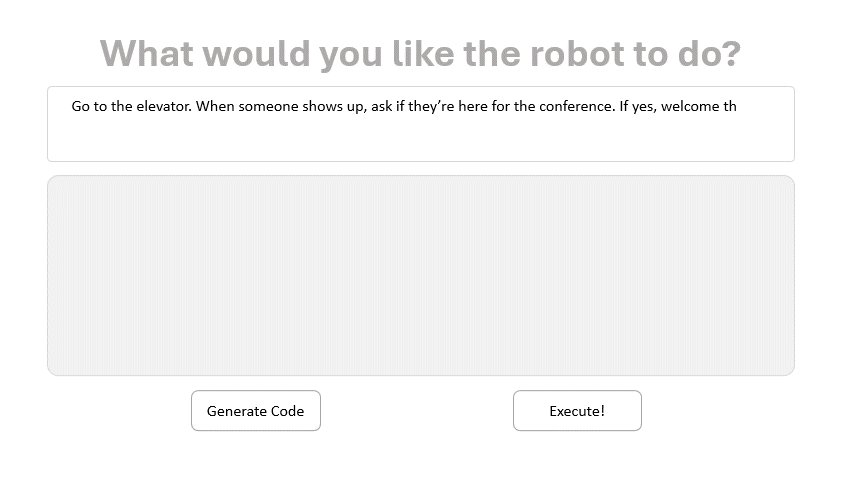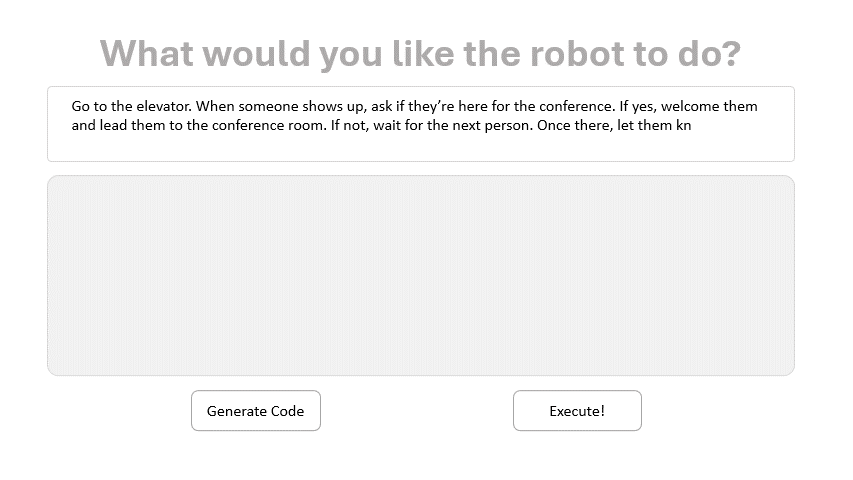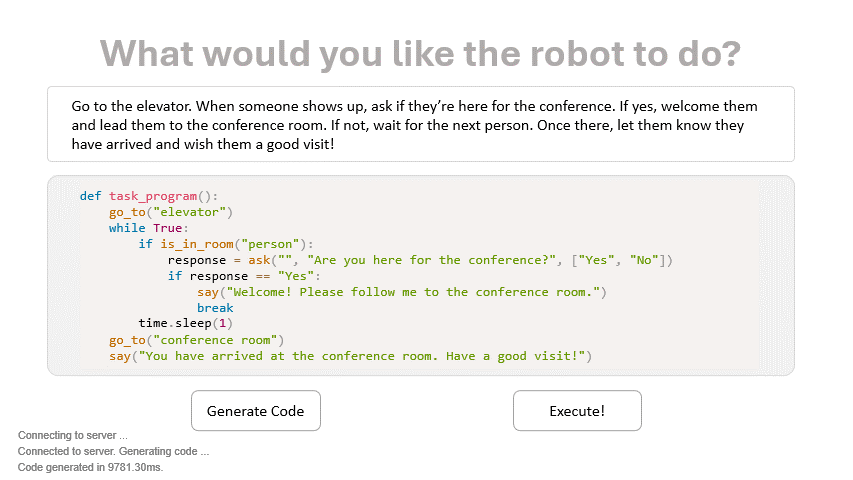
CodeBotler is a system that converts natural language task descriptions into robot-agnostic programs that can be executed by general-purpose service mobile robots.
4
4
5
-

6
-
7
-
CodeBotler is a system that converts natural language task descriptions into robot-agnostic programs that can be executed by general-purpose service mobile robots. It includes a benchmark (RoboEval) designed for evaluating Large Language Models (LLMs) in the context of code generation for mobile robot service tasks.
8
-
9
-
This project consists of two key components:
10
-
*[CodeBotler](#codebotler-deploy-quick-start-guide): This system features a web interface designed for generating general-purpose service mobile robot programs, along with a ROS2 (Robot Operating System) Action client for deploying these programs on a robot. It offers the flexibility to explore the code generation capabilities of CodeBotler in two ways: as a standalone system without a robot, as illustrated in the figure above, or by actual deployment on a real robot.
11
-
12
-
13
-
*[RoboEval](#roboeval-benchmark-quick-start-guide): This benchmark for code generation features a suite of 16 user task descriptions, each with 5 paraphrases of the prompt. It includes a symbolic simulator and a temporal trace evaluator, specifically designed to assess Large Language Models (LLMs) in their ability to generate code for service mobile robot tasks.
16
6
17
7
## Requirements
18
8
19
9
We provide a conda environment to run our code. To create and activate the environment:
20
10
```shell
21
-
conda create -n codebotler python=3.10 pip
11
+
conda create -n codebotler python=3.12.8 pip
22
12
conda activate codebotler
23
13
pip install -r requirements.txt
24
14
```
@@ -27,85 +17,28 @@ After installing the conda environment, please go to [pytorch's official website
27
17
**ROS2 Requirements**
28
18
* For robot deployment, you will need ROS2 installed on your system. CodeBotler uses ROS2 actions for robot communication.
29
19
* Install ROS2 following the [official ROS2 installation guide](https://docs.ros.org/en/humble/Installation.html).
30
-
* The robot interface components will automatically install the required ROS2 Python packages (`rclpy`).
20
+
* The robot interface components will automatically install the required ROS2 Python packages (`rclpy`).
31
21
32
22
**Language Model Options**
33
23
* To use an OpenAI model, you will need an [OpenAI key](https://platform.openai.com/account/api-keys), either saved in a file named `.openai_api_key`, or in the `OPENAI_API_KEY` environment variable.
34
24
* To use a PaLM model, you will need a [Google Generative API key](https://developers.generativeai.google/tutorials/setup), either saved in a file named `.palm_api_key`, or in the `PALM_API_KEY` environment variable.
35
25
* You can use any pretrained model compatible with the [HuggingFace AutoModel](https://huggingface.co/transformers/v3.5.1/model_doc/auto.html#automodelforcausallm) interface, including open-source models from the [HuggingFace repository](https://huggingface.co/models) such as [Starcoder](https://huggingface.co/bigcode/starcoder). Note that some models, including Starcoder, require you to agree to the HuggingFace terms of use, and you must be logged in using `huggingface-cli login`.
36
26
* You can also use a [HuggingFace Inference Endpoint](https://huggingface.co/docs/inference-endpoints/index).
37
27
28
+
## Quick Start Guide
38
29
39
-
## CodeBotler Deployment Quick-Start Guide
40
-
41
-
To run the web interface for CodeBotler-Deploy using the default options (using OpenAI's
42
-
`gpt-4` model), run:
30
+
To run the web interface for CodeBotler using the default options (using OpenAI's `gpt-4` model), run:
43
31
```shell
44
32
python3 codebotler.py
45
33
```
46
-
This will start the server on `localhost:8080`. You can then open the interface
47
-
by navigating to http://localhost:8080/ in your browser.
34
+
This will start the server on `localhost:8080`. You can then open the interface by navigating to http://localhost:8080/ in your browser.
48
35
49
-
List of arguments:
36
+
### Arguments
50
37
*`--ip`: The IP address to host the server on (default is `localhost`).
51
38
*`--port`: The port to host the server on (default is `8080`).
52
39
*`--ws-port`: The port to host the websocket server on (default is `8190`).
53
-
*`--model-type`: The type of model to use. It is either `openai-chat` (default) and `openai` for [OpenAI](https://platform.openai.com),
54
-
`palm` for [PaLM](https://developers.generativeai.google/), or `automodel`
*`--model-name`: The name of the model to use. Recommended options are
58
-
`gpt-4` for GPT-4 (default), `text-daVinci-003` for GPT-3.5, `models/text-bison-001` for PaLM, and
59
-
`bigcode/starcoder` for AutoModel.
40
+
*`--model-type`: The type of model to use. It is either `openai-chat` (default) and `openai` for [OpenAI](https://platform.openai.com), `palm` for [PaLM](https://developers.generativeai.google/), or `automodel` for [AutoModel](https://huggingface.co/transformers/model_doc/auto.html#automodel).
41
+
*`--model-name`: The name of the model to use. Recommended options are `gpt-4` for GPT-4 (default), `text-daVinci-003` for GPT-3.5, `models/text-bison-001` for PaLM, and `bigcode/starcoder` for AutoModel.
60
42
*`--robot`: Flag to indicate if the robot is available (default is `False`).
61
43
62
-
Instructions for deploying on real robots are included in [robot_interface/README.md](robot_interface/README.md).
63
-
64
-
## RoboEval Benchmark Quick-Start Guide
65
-
66
-
The instructions below demonstrate how to run the benchmark using the open-source [StarCoder](https://huggingface.co/bigcode/starcoder) model.
67
-
68
-
1. Run code generation for the benchmark tasks using the following command:
This will generate the programs forthe benchmark tasks and save them as a Python filein
74
-
an output directory `completions/starcoder`. It assumes default values
75
-
for temperature (0.2), top-p (0.9), and num-completions (20), to generate 20
76
-
programs for each task --- this will suffice for pass@1 evaluation.
77
-
78
-
If you would rather not re-run inference, we have included saved output from every model in the `completions/` directory as a zip file. You can simply run.
79
-
```shell
80
-
cd completions
81
-
unzip -d <MODEL_NAME><MODEL_NAME>.zip
82
-
```
83
-
For example, you can run:
84
-
85
-
```shell
86
-
cd completions
87
-
unzip -d gpt4 gpt4.zip
88
-
```
89
-
2. Evaluate the generated programs using the following command:
0 commit comments