You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Authors - Mohan Kingom, Bharath Kumar Bolla, Sabeesh E
Scope of the Paper
Identifying defective casting products using Deep learning needs to be faster and more robust as this is critical in a factory setting where 1000s of products are passed through the conveyor belt. Here we have revisited techniques that shall aid speeding a deep learning model and make them lighter for deployment on low computing devices. Custom and Transfer learning models have been used and evaluated using accuracy, F1 scores and latency of prediction on a CPU.
Reducing model size using custom architectures
Will data augmentation help in this scenario?
Channel Pruning - Tapering Network
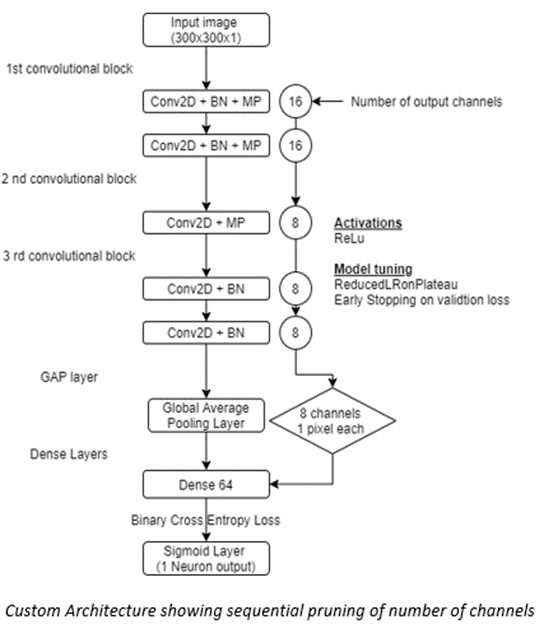
The concept of channel pruning has been implemented here where in there is a sequential reduction in the number of channels. Though this is contrary to conventional deeplearning architectures, the authors have leveraged on the fact that sufficient features are learnt during the initial convolutions as they are passed through "multiple similar convolution" layers and then the networks is gradually condensed as they approach the softmax layer. A trade off exists between the loss of information / accuracy and the "depth of tapering'. The more the network is tapered there is more loss of information. Hence an ideal depth is to be identified at which there is no significant loss of information. This varies with every architecture and dataset the neural networks are trained on.
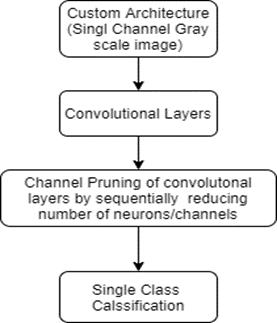
Custom Architectures
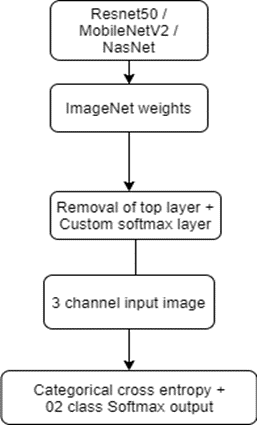
Transfer learning architectures
Architectures
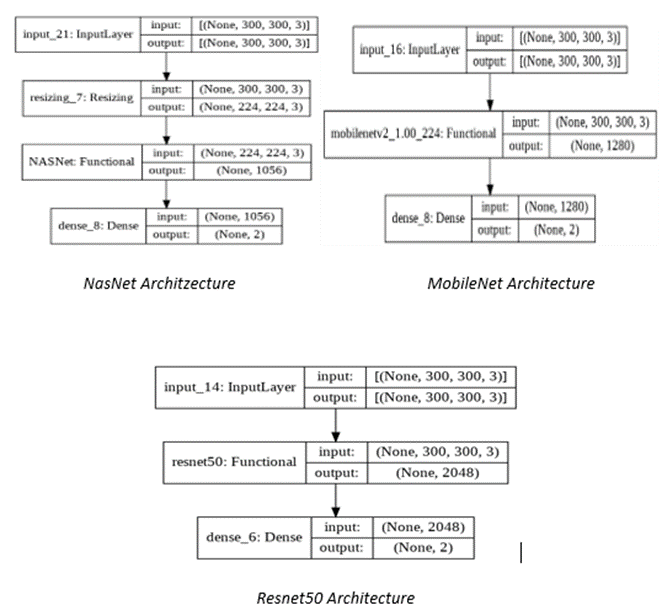
The model architecture is shown below.
Custom Architectures
Transfer learning architectures
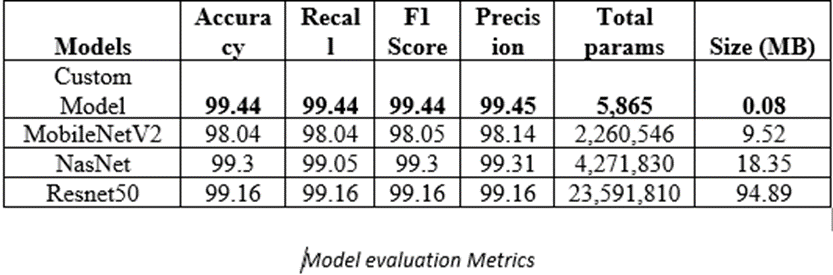
Custom models have the highest accuracy with the lowest inference times. This is in spite of the "tapering" network the model has been trained using, hence confirming our hypothesis that "Channel pruning may yet be an effective way to reach peak accuracies if pruned judiciously"
Effect on Accuracy
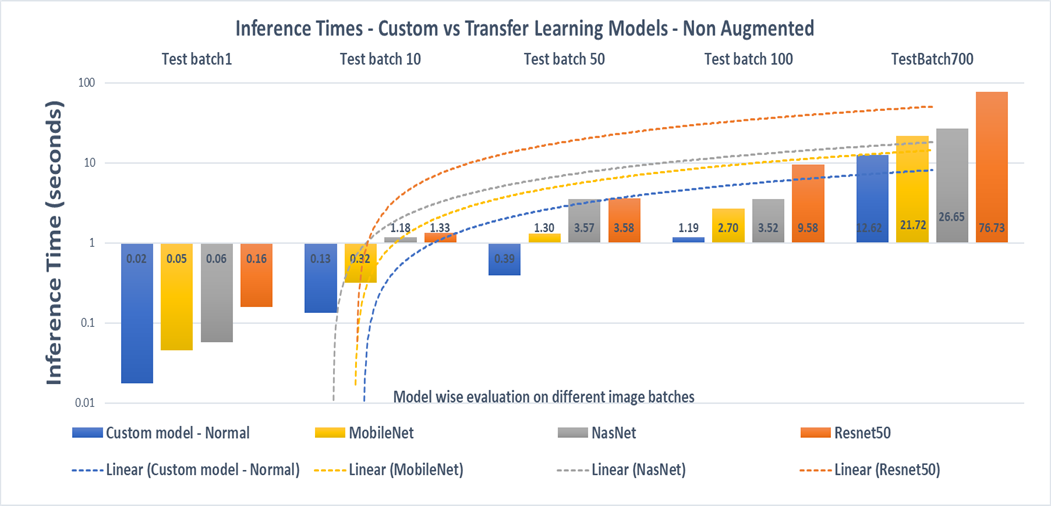
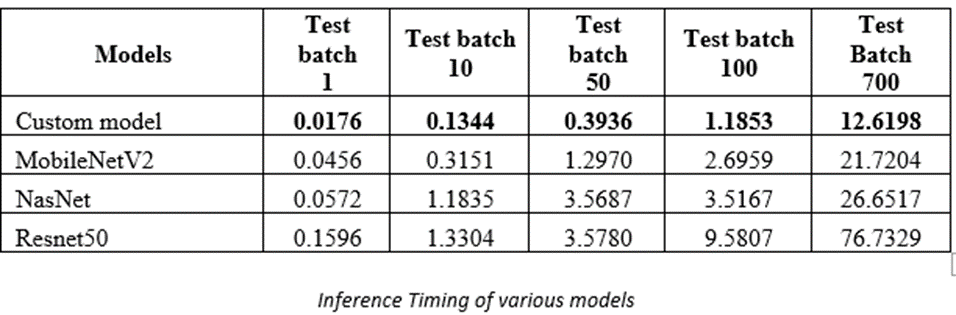
Inference Times
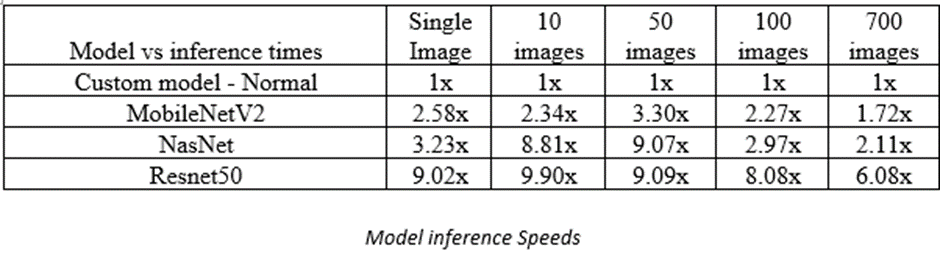
From the images below it is seen that Resnet performs 9 times slower than the custom architecture followed by Nasnet and MobileNet. This can be attributed to the number of training parameters in the neural network.
inf time on varying test size
inf time on varying test size - ratio
Model Size / F1 score analysis
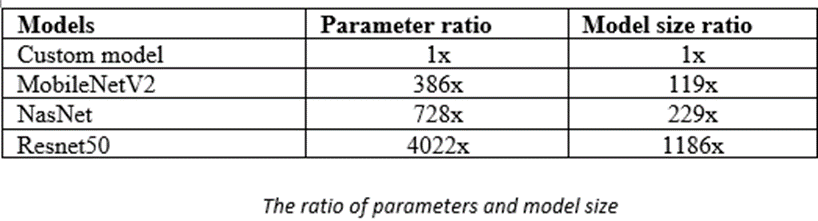
The same is evident from the model size and parameter ratio, as seen below where transfer learning architectures have nearly 4000x times more parameters and 1000x times bigger than a custom model.
Model Size
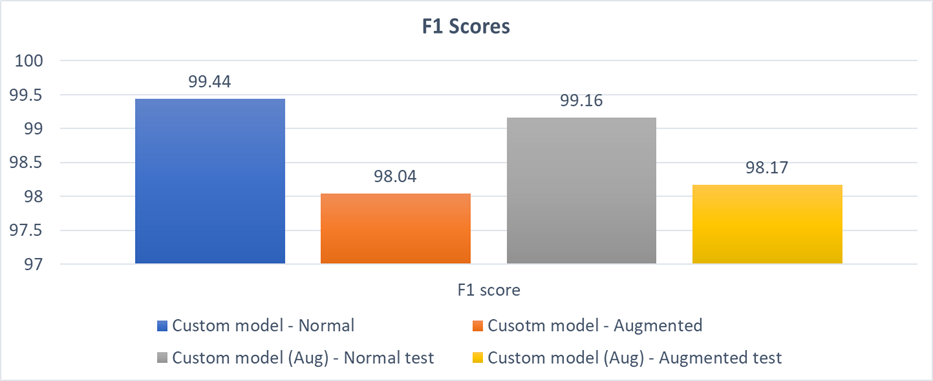
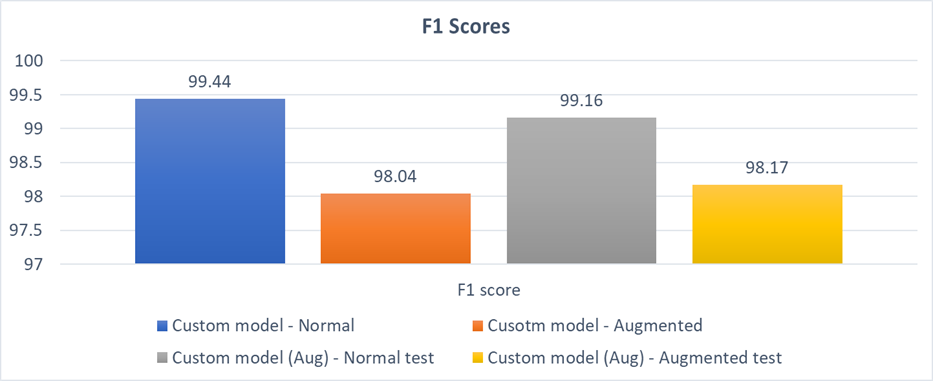
F1 scores
The Augmentation Paradox
Also it is seen that , augmentation plays a deterious effect both on the normal and the augmented test dataset in terms of F1 scores. This can be attributed to the fact that, as in our case "specificty is more important", any alterations in the input image will result in mis-classifications as a "NORMAL PIECE WOULD APPEAR DEFECTIVE DUE TO THE EFFECT OF AUGMENTATIONS AND WILL ULTIMATELY RESULT IN THE MODEL MISCLASSIFIYING IT AS DEFECTIVE".
Effect of Augmentations
Augmentation paradox
Even if we re using the augmentations the points to be taken care of is
we should know how much to augment
and this has to be decided based on the EDA of the dataset
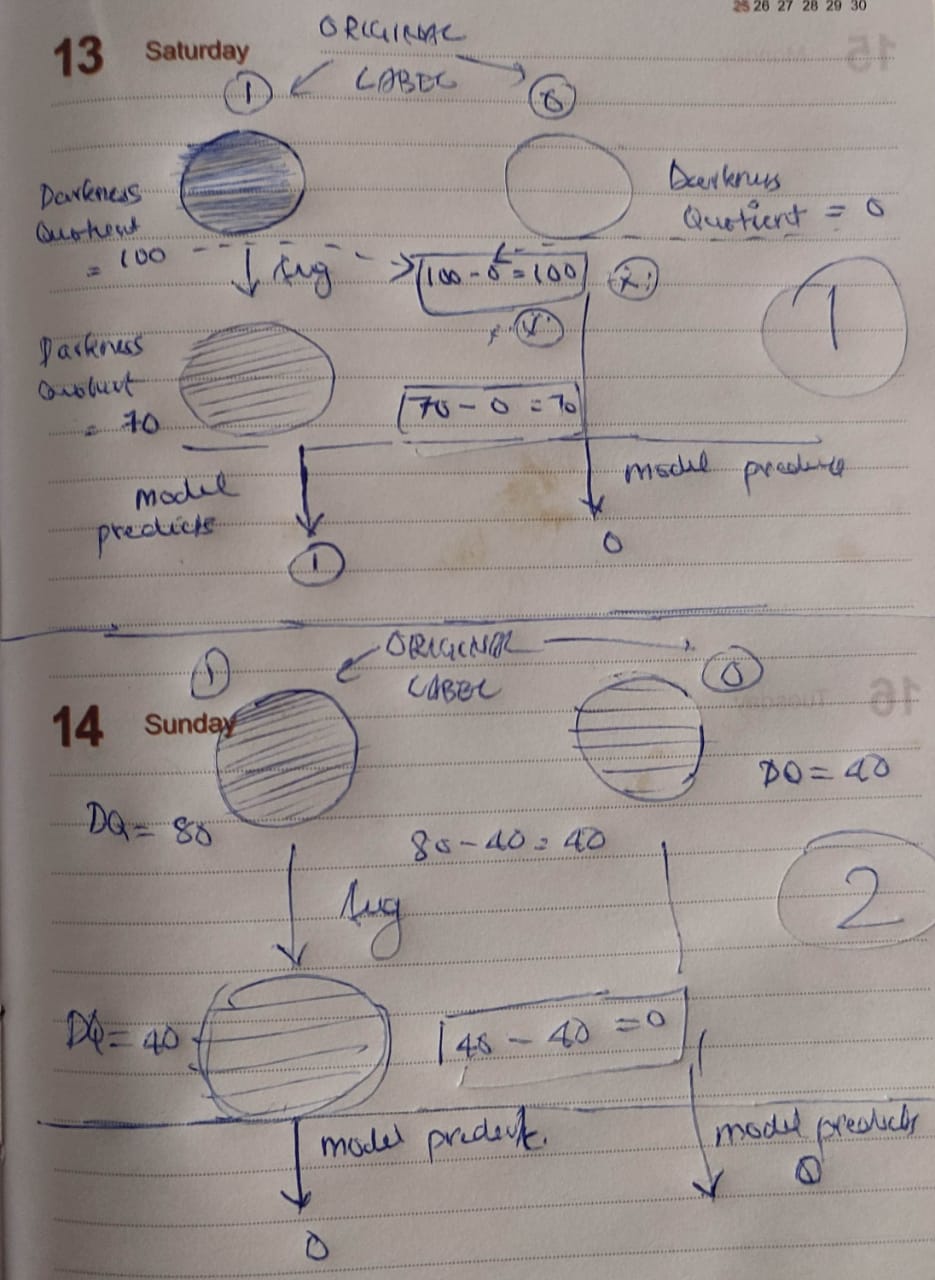
If the difference between the 1 and 0 is huge Then the augmentation has a positive effect, as seen in case 1.
If the difference between the 1and 0 is minimal as In the case 2 then augmenting will randomize the model and decrease accuracy as in our paper.
A proper EDA of the dataset is hence required to analyse the difference in pixels between the normal and abnormal and see "which" and more importantly "how much" Also which class dominates matter.
As in the second case if 0 class dominates. Then model predicts 0 as 0 and 1 too as 0
If the class 1 dominates then the model predicts 1 as 1 and 0 also as 1