Governed, self-hosted text-to-SQL — for teams that can't ship their data to someone else's cloud.
![]()
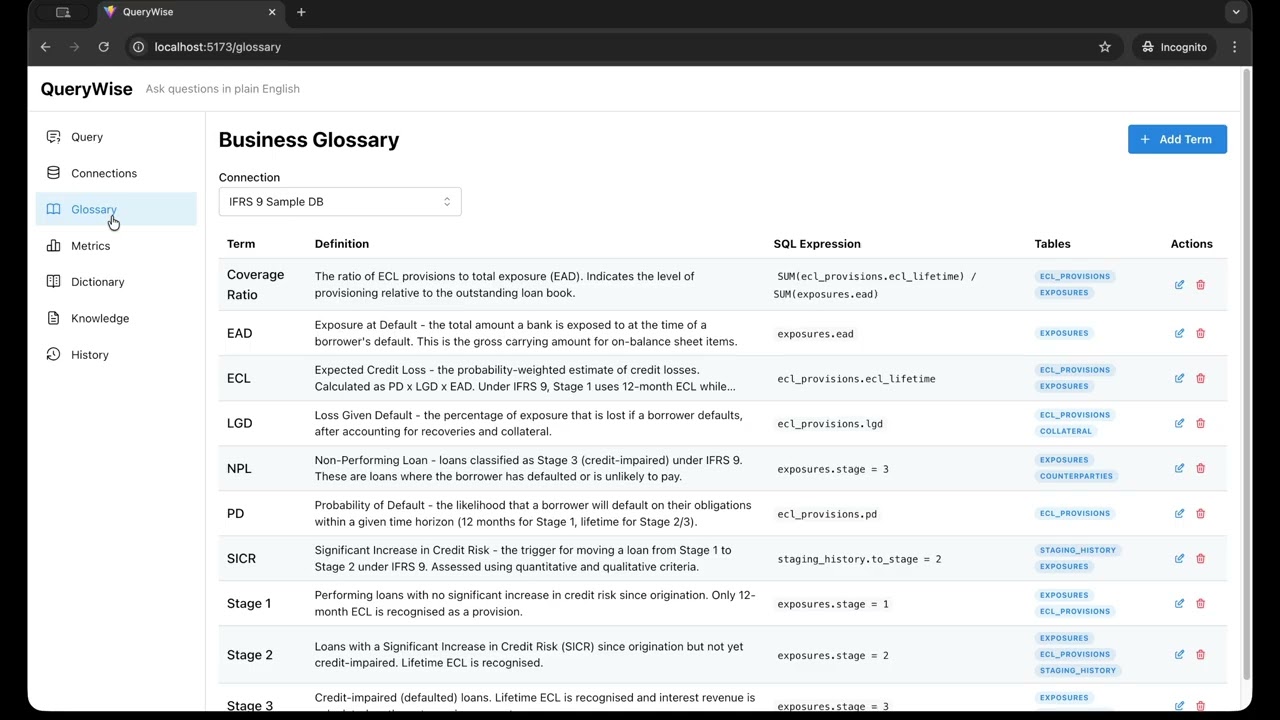
LLMs write bad SQL when they only see your schema — they don't know that "coverage ratio" means SUM(ecl_lifetime) / SUM(ead), or that stage = 2 means SICR. QueryWise fixes that with a semantic metadata layer (business glossary, certified metrics, data dictionary, imported documentation) that grounds every generated query in your business's actual definitions. It runs entirely in your infrastructure — your VPC, your LLM keys, or fully air-gapped with Ollama — and wraps the whole loop in the governance regulated teams need: certification workflows, versioning, lineage, audit trails, and column-level data policies.
Ask a question, review the SQL, get an explained answer — then pin it as a saved query, chart it, and compose dashboards your whole team can use.

🎯 Accuracy comes from the semantic layer, not the model. Every question runs through hybrid retrieval — pgvector embedding similarity, keyword matching, and foreign-key graph traversal — to assemble exactly the context the LLM needs: relevant tables, glossary terms, metric formulas, column value mappings, similar past queries, and excerpts from your imported documentation. The generated SQL uses your definitions, and you review it before it runs.
🛡️ Governance is built in, not bolted on. Metrics, glossary terms, and saved queries move through a draft → in_review → certified → deprecated lifecycle with role gates (editors submit, admins certify), full version history, and field-level diffs. sqlglot-powered lineage shows what every query touches and what breaks if a table changes. Data policies enforce row filters and column masking before results reach the user — or the LLM. Every execution is audit-logged.
🔒 Your data never leaves your infrastructure. Self-host with Docker, Helm, or Terraform (AWS/GCP/Azure). Bring your own LLM: Anthropic, OpenAI, Azure OpenAI inside your VPC — or run fully local with Ollama, no API keys, no egress. Queries execute in read-only transactions behind a SQL blocklist, with encrypted credentials, timeouts, and row limits.
🔌 It meets your team where they work. A web app for analysts (query, dashboards, catalog search), a REST API for builders, and an MCP server that puts the same governed pipeline inside Claude, Cursor, Copilot, and Codex — 24 tools sharing one semantic layer.
All you need is Docker and either an LLM API key or Ollama.
git clone https://github.com/kosminus/querywise.git
cd querywise
cp .env.example .env # add your API key, or configure Ollama — see docs/configuration.md
docker compose up| Service | URL |
|---|---|
| Frontend | http://localhost:5173 |
| Backend API | http://localhost:8000 |
| API Docs (Swagger) | http://localhost:8000/docs |
Then:
- Open http://localhost:5173 — a sample IFRS 9 banking database is auto-configured on first startup, with its semantic layer pre-seeded (10 glossary terms, 8 metrics, 43 dictionary entries, a policy document).
- Go to Query and ask: "What is the total ECL by stage?"
- Review the generated SQL, execute, and get a plain-English answer with highlights and suggested follow-ups.
You can try the entire product — semantic layer, governance, dashboards — before connecting a single database of your own. To connect your real PostgreSQL, BigQuery, or Databricks, see docs/configuration.md.
"What is the total ECL by stage?"
│
▼
1. CONTEXT BUILDING hybrid retrieval over the semantic layer:
embeddings (50%) + keywords (30%) + FK graph (20%)
→ top tables, glossary, metrics, dictionary,
knowledge excerpts, similar sample queries
▼
2. ROUTING classify simple/moderate/complex → set model + token budget
▼
3. SQL GENERATION Composer agent writes SQL grounded in your definitions
▼
4. VALIDATION blocklist + schema check; Error-Handler agent repairs
invalid SQL (max 3 attempts) — unsafe SQL never executes
▼
5. EXECUTION read-only transaction, statement timeout, row limit,
data-policy row filters + column masking
▼
6. INTERPRETATION Interpreter agent: summary, highlights, follow-ups
▼
7. HISTORY + AUDIT full execution log, audit event, cost attribution
Four specialized agents (Composer, Validator, Interpreter, Error Handler) run against any configured provider. The retrieval weights and the agent loop live in backend/app/semantic/ — the core of the product.
QueryWise is an MCP server. Two commands and your coding agent can query your warehouse through the governed pipeline:
claude mcp add --transport http querywise http://localhost:8000/mcp
# or: codex mcp add querywise --url http://localhost:8000/mcpThen just ask: "Add a metric gross_revenue with expression SUM(exposure_amount)" or "What is the total ECL by stage?". All 24 tools (generate SQL, run queries, manage the semantic layer, search history) share the same store and authorization as the web UI. Setup for Claude Desktop, Cursor, Windsurf, Copilot, and stdio transport: docs/mcp.md.
Ask & answer
- Natural language → SQL → results → plain-English explanation with highlights and follow-ups
- Review and edit generated SQL (Monaco editor) before execution
- Conversational Assistant that drafts glossary terms, metrics, and dictionary entries from chat
- Query history with favorites, retry counts, and token usage
Semantic layer
- Business glossary, metric definitions, data dictionary (value mappings), sample queries
- Knowledge import — pull in Confluence pages, wikis, and HTML docs as retrievable context
- Hybrid retrieval: pgvector embeddings + keyword match + foreign-key expansion
- Auto-introspection of tables, columns, types, and relationships
Durable artifacts
- Saved queries with typed parameters (
{{region}}) — run, version, clone, export (CSV/JSON/XLSX) - Charts (line/bar/area/pie/scatter) and draggable dashboard grids with cross-tile filters
- Result snapshots cached in Postgres so re-runs don't re-hit the warehouse
Governance & trust
- Certification lifecycle with role gates, version history, and changelogs
- Data catalog: hybrid search across tables, metrics, glossary, and knowledge with certified-first ranking
- Column/table lineage and impact analysis (sqlglot)
- Append-only audit log, data policies (row filters, column masking), per-query cost attribution
- Users, teams, workspaces, and roles (viewer / editor / admin); API keys; magic-link or password login
Platform
- LLM-agnostic: Anthropic, OpenAI, Azure OpenAI, Ollama — switch with two env vars
- Connector plugin system: PostgreSQL, BigQuery, Databricks built in; extensible to more
- Rate limiting, async job queue (in-process or Redis/arq), OpenTelemetry tracing, structured logging, health probes
The same build-once images run everywhere, configured entirely by environment:
| Target | Where | Best for |
|---|---|---|
| Docker Compose (prod) | docker-compose.prod.yml |
Small / on-prem, single host |
| Helm chart | deploy/helm/querywise/ |
EKS / GKE / AKS |
| Terraform | deploy/terraform/{aws,gcp,azure}/ |
Managed Postgres+pgvector, Redis, secrets — in your own VPC |
| CI/CD | .github/workflows/release.yml |
Build → push images → Helm deploy (staging → prod) |
| Ops | deploy/ops/ |
Encrypted backup/restore, DR runbook, config reference |
Highlights: hardened multi-stage non-root images, a one-shot Alembic migration that runs before new pods roll (replicas never race), backend autoscaling + PodDisruptionBudgets, secrets via the external-secrets seam, and a same-origin SPA behind an nginx edge. Start at deploy/README.md.
- Read-only execution — PostgreSQL queries run inside read-only transactions; BigQuery and Databricks enforce read-only via the SQL blocklist
- SQL blocklist — blocks DDL, DML, admin commands, injection patterns (
pg_sleep,dblink, stacked queries), and warehouse-specific writes (EXPORT DATA,COPY INTO,OPTIMIZE,VACUUM) - Data policies — per-role row filters and column masking applied before results reach the user or the interpreting LLM
- Encrypted credentials — connection strings encrypted at rest (Fernet); never returned by the API
- Limits everywhere — statement timeouts, row caps, and per-minute rate limits, all configurable per connection
QueryWise ships with an IFRS 9 banking schema (Expected Credit Loss provisioning) so the demo is realistic, not SELECT * FROM users: counterparties, facilities, exposures, ECL provisions, collateral, and a stage-transition audit trail — six tables with the glossary (EAD, PD, LGD, SICR…), metrics (Coverage Ratio, NPL Ratio…), and dictionary mappings already seeded. It doubles as a template for what a well-curated semantic layer looks like.
| Guide | Contents |
|---|---|
| docs/configuration.md | Environment variables, LLM/Ollama setup, connecting PostgreSQL / BigQuery / Databricks |
| docs/mcp.md | MCP setup for Claude Code, Claude Desktop, Cursor, Windsurf, Copilot, Codex |
| docs/api-reference.md | REST API endpoints (also live at /docs via Swagger) |
| docs/development.md | Local dev without Docker, project structure, adding connectors and LLM providers |
| deploy/README.md | Production deployment: compose, Helm, Terraform, CI/CD, ops |