I did Twitter Sentiment analysis on the subject of Tottori's Tourism and then visually plotted the results
Sentiment analysis is a very popular method of doing market research by performing data mining of opinion, then doing natural language processing and presenting or studying the results for any particular purpose, for example: Understanding the senitment of population towards a policy, product or thoughts and opinions
For this analysis I have done the following things to do analysis on Twitter's perception on Tottori Prefecture ツイッターのユーザの鳥取観光についてどう思っているのかをセンチメント分析の方法で行います。
This is the main things done in this analysis
- Data mining around a 1000 tweets from Twitter regarding the keyword: 鳥取観光
- Using Google Translate packages in python to translate all the mined tweets
- Use Natural Language processing packages such 'Roberta' by hugging face to perform Sentiment analysis
- Visualise the result on a graph
So let's get started!
- Mining Tweets For the first step, we need some libraries installed to Mine tweets

Next we mine tweets from Twitter (I have used a method where we don't need to use an API! :D)
I used the keyword '鳥取観光' to mine the 1000 tweets from all over Twitter in the span of One year from Feb 20, 2022 to Feb 20, 2023
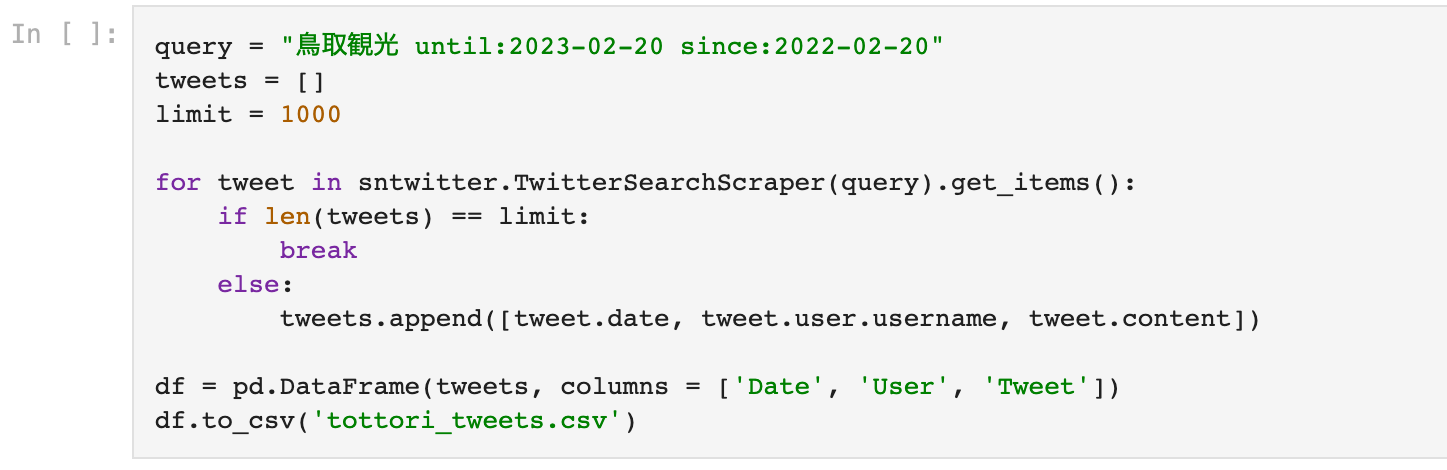 The file will be saved in your directory
The file will be saved in your directory
Now that we have our data, it is time to install Google Translate on python!
 It will take like a minute to install.
🥵Attention! For some reason the package does not work in VSCode and always gives some error, try using Google CoLab!
It will take like a minute to install.
🥵Attention! For some reason the package does not work in VSCode and always gives some error, try using Google CoLab!
Lets try doing a sample translation to see if it works.
 It works!
It works!
Now, for verification, lets check our twitter mined dataset
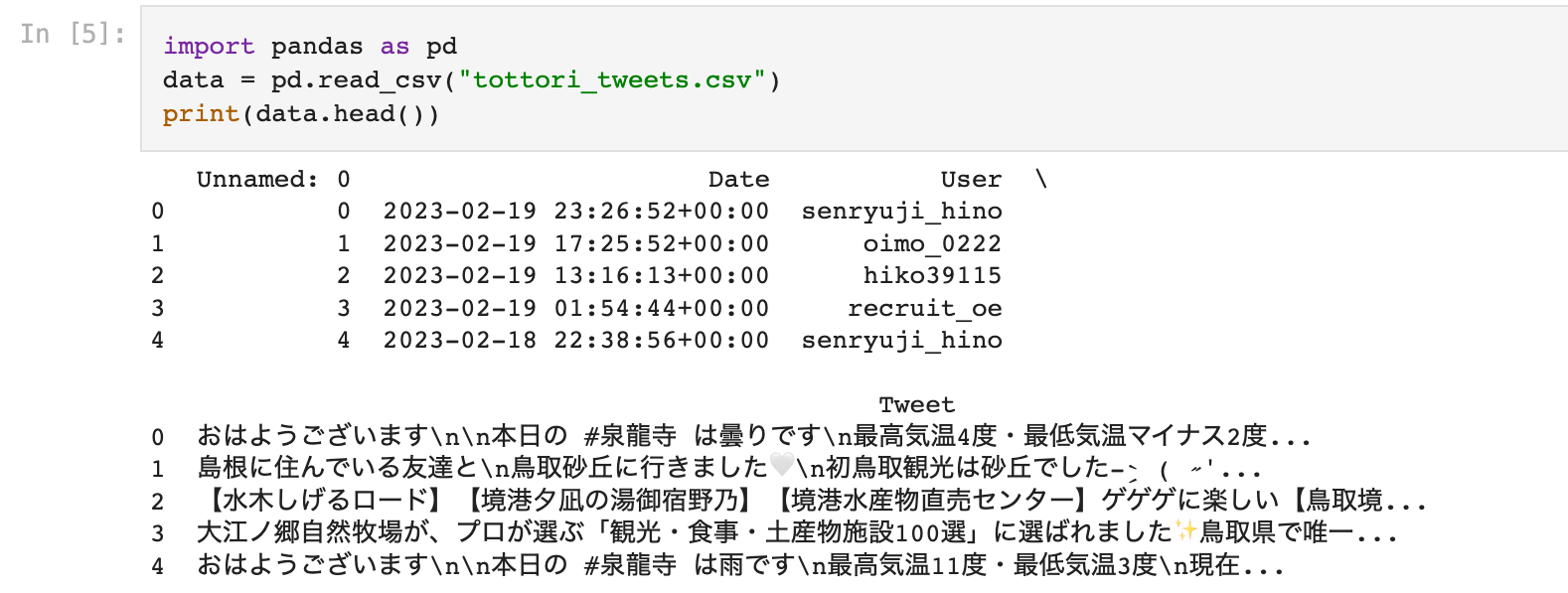
Looks good to me, however, as you can see, the tweets are in Japanese and the Natural Language processing packages cannot process Japanese yet, so we will translate all the tweets to English!
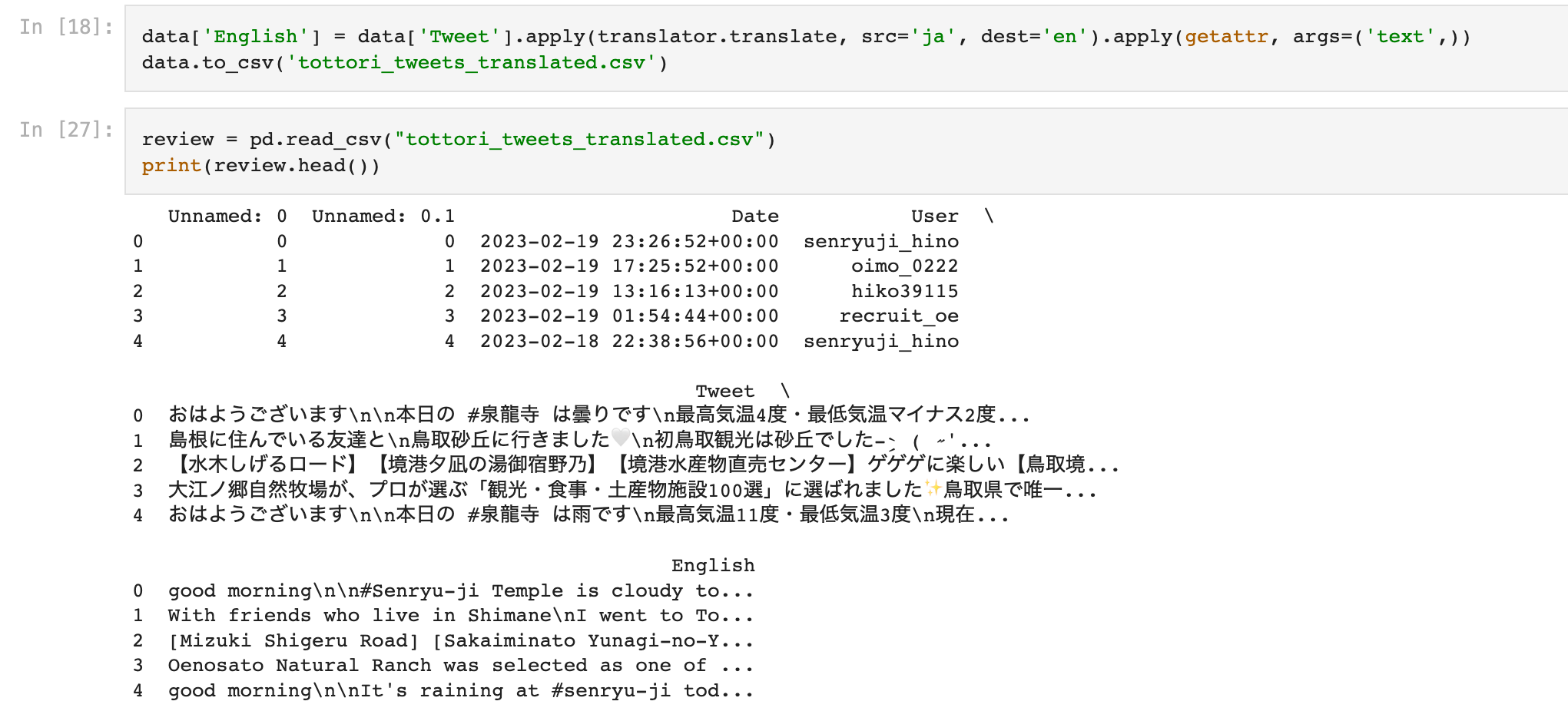
We have successfully translated all the tweets from Japanese to english and also created a new CSV file with all the translated data in the english column. ☀️It is important to note that, since we do not translate directly and use machine translation, it might lose some level of accuracy!
Now lets install some libraries for Sentiment analysis, I like NLTK and TRANSFORMERS
 and
pip install transformers
and
pip install transformers
Now lets install some essential libraries for our analysis

Now its time for the difficult part, we will try to do sentiment analysis on the whole dataset and see how it goes:

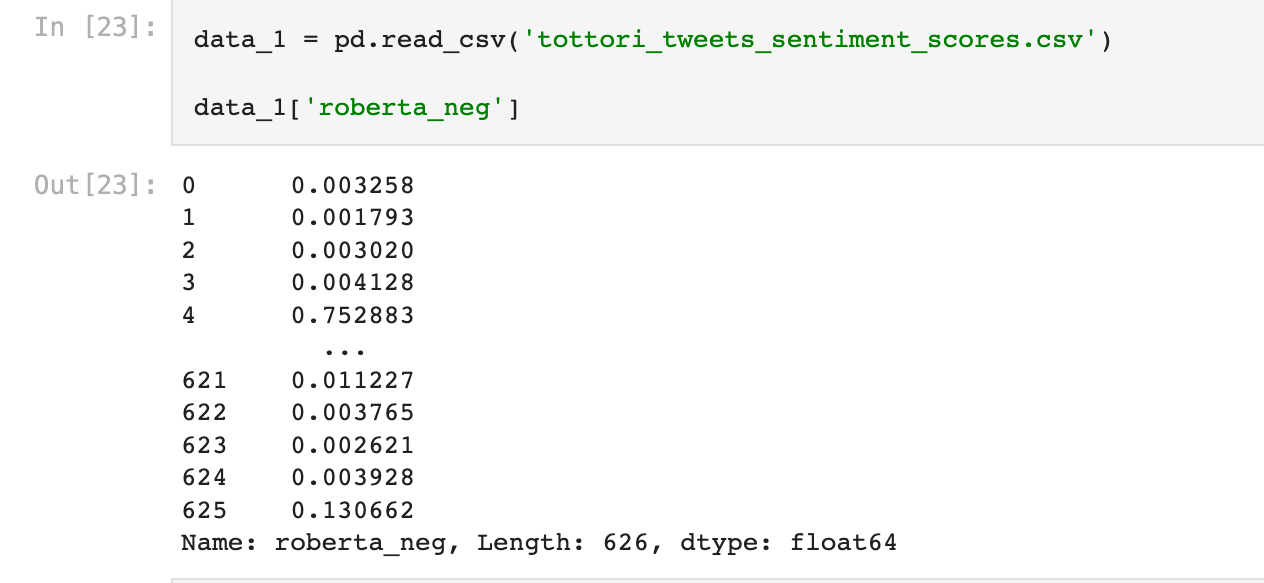
The final dataset with sentiment scores will look like this
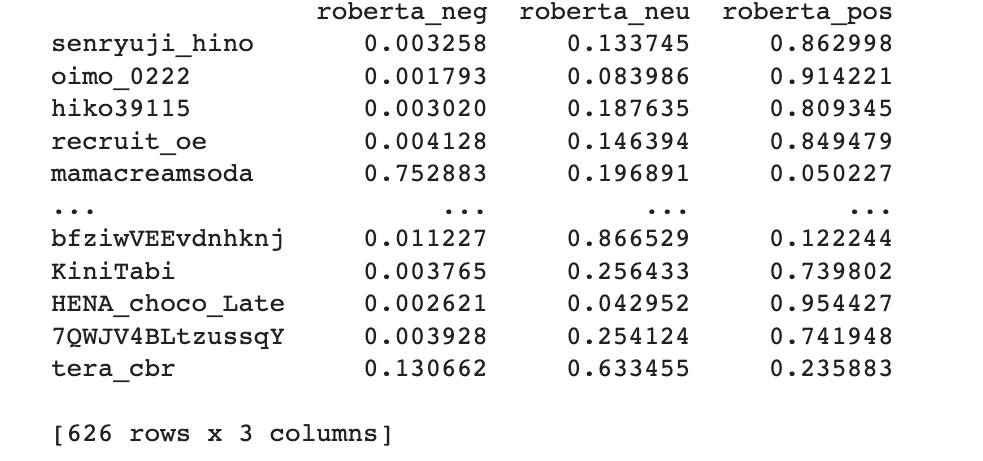
As you can see we have 626 results now but we had 1000 tweets. It is so because, the code omitted all the duplicates and only kept the unique ones. This will help us get a more accurate average for the analysis
Checking if the dataset is alright
Now we will average all the scores and check the overall probability score

THE PEOPLE OF TWITTER ARE MOSTLY POSITIVE ABOUT TOURISM IN TOTTORI! ほっとしました〜!
Now for the final Step lets visualise our results!
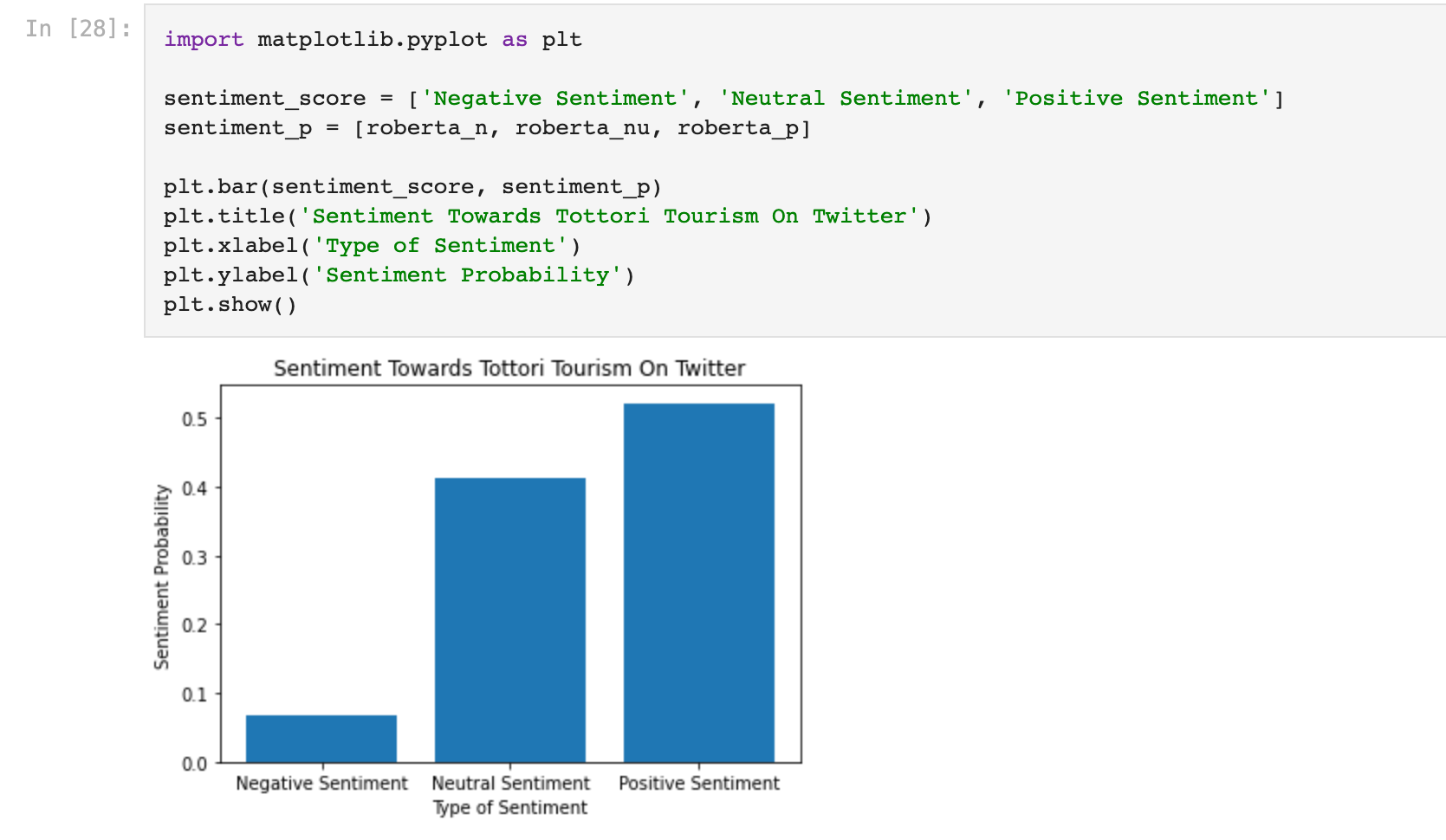
It looks pretty nice to me! Thank you for reading! Lemme know of any feedback, it is always appreciated