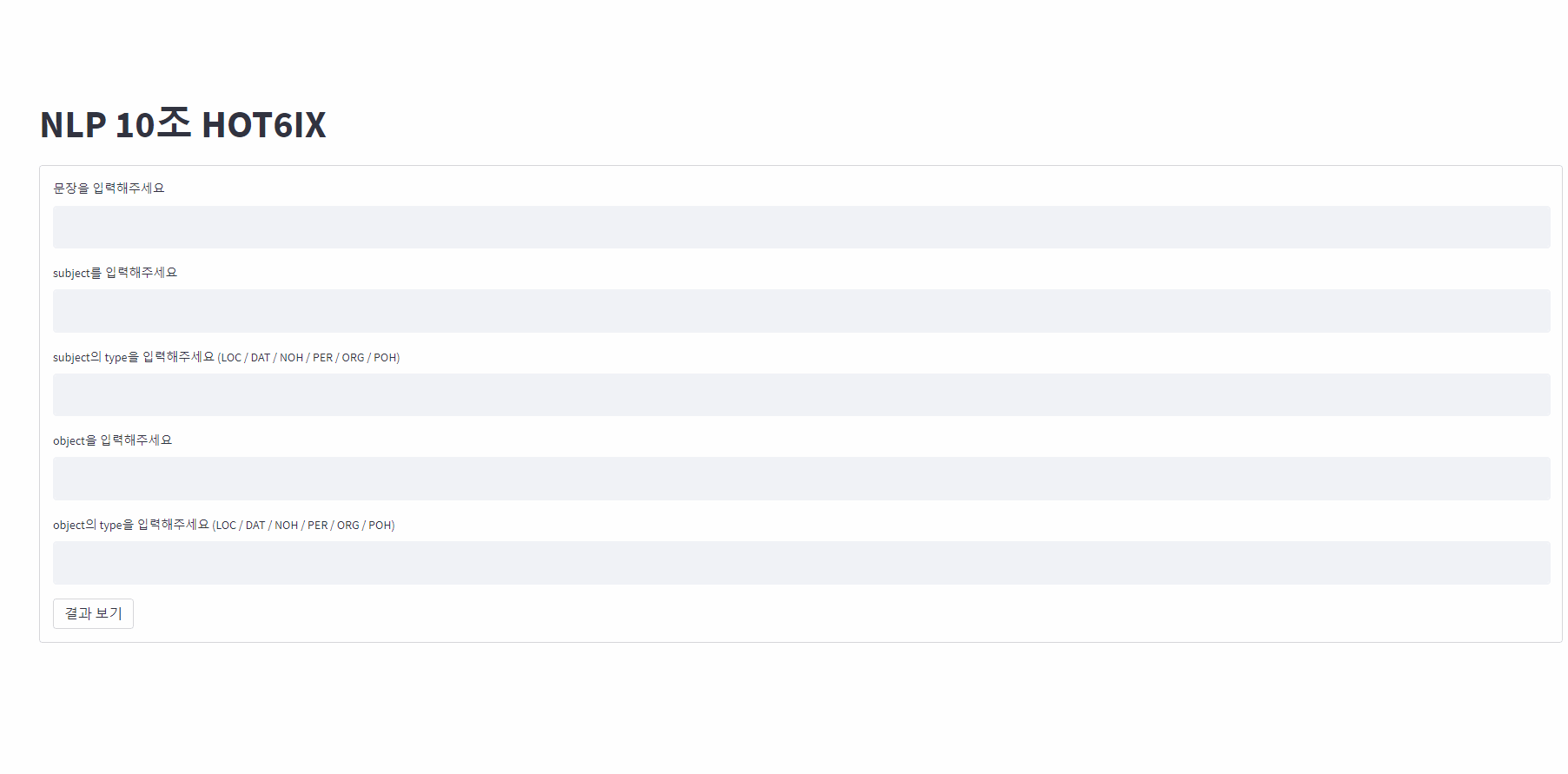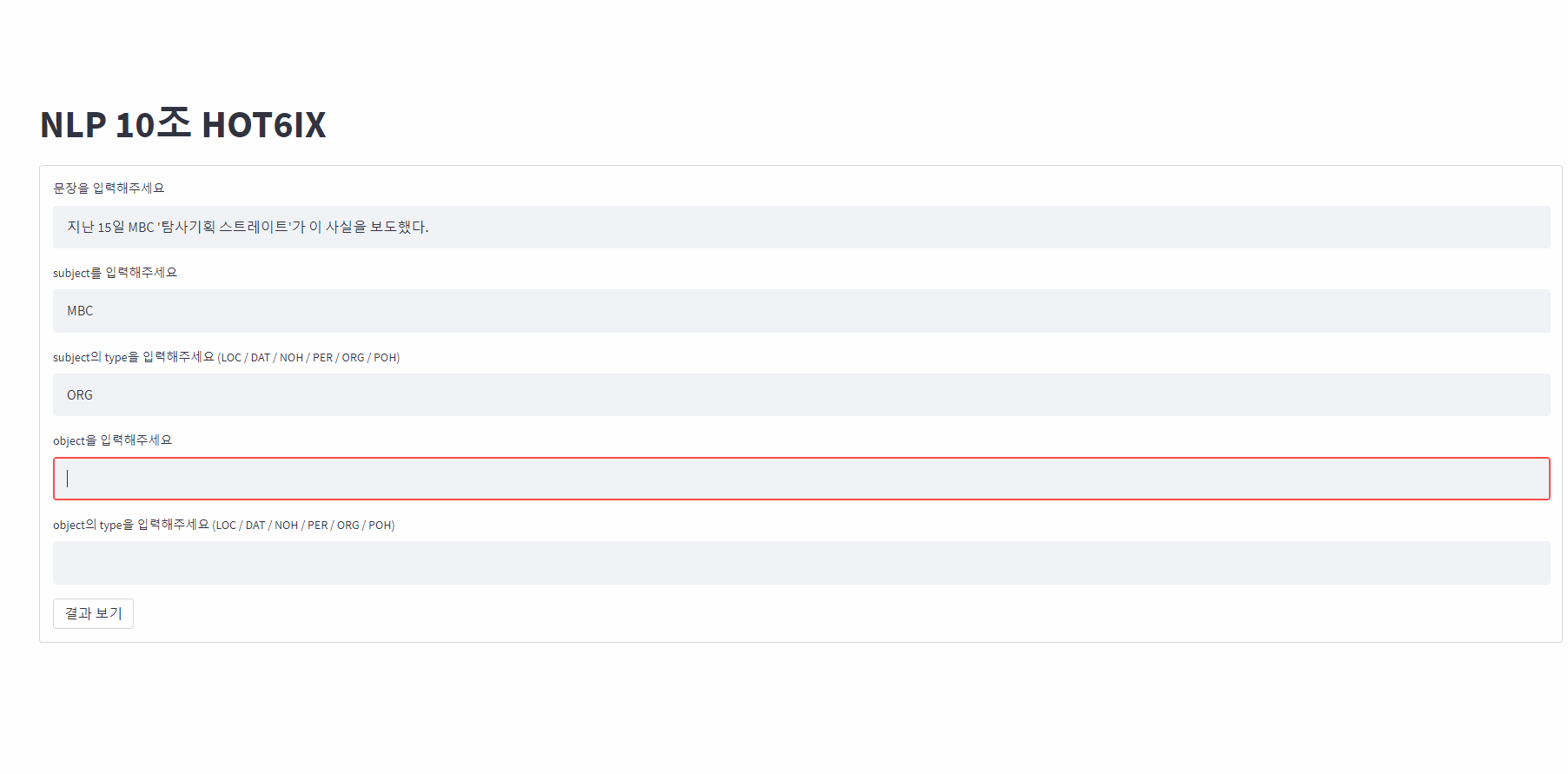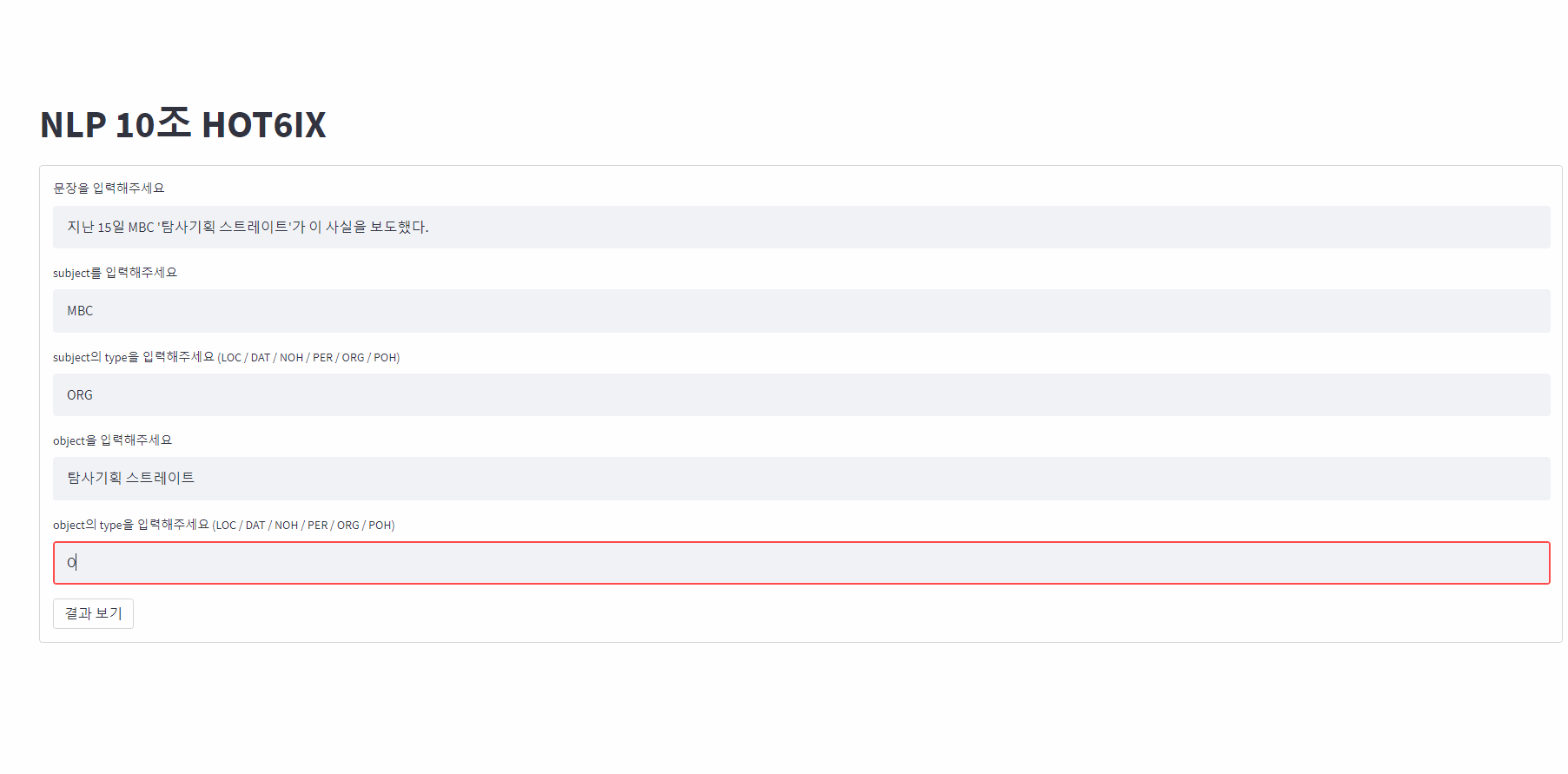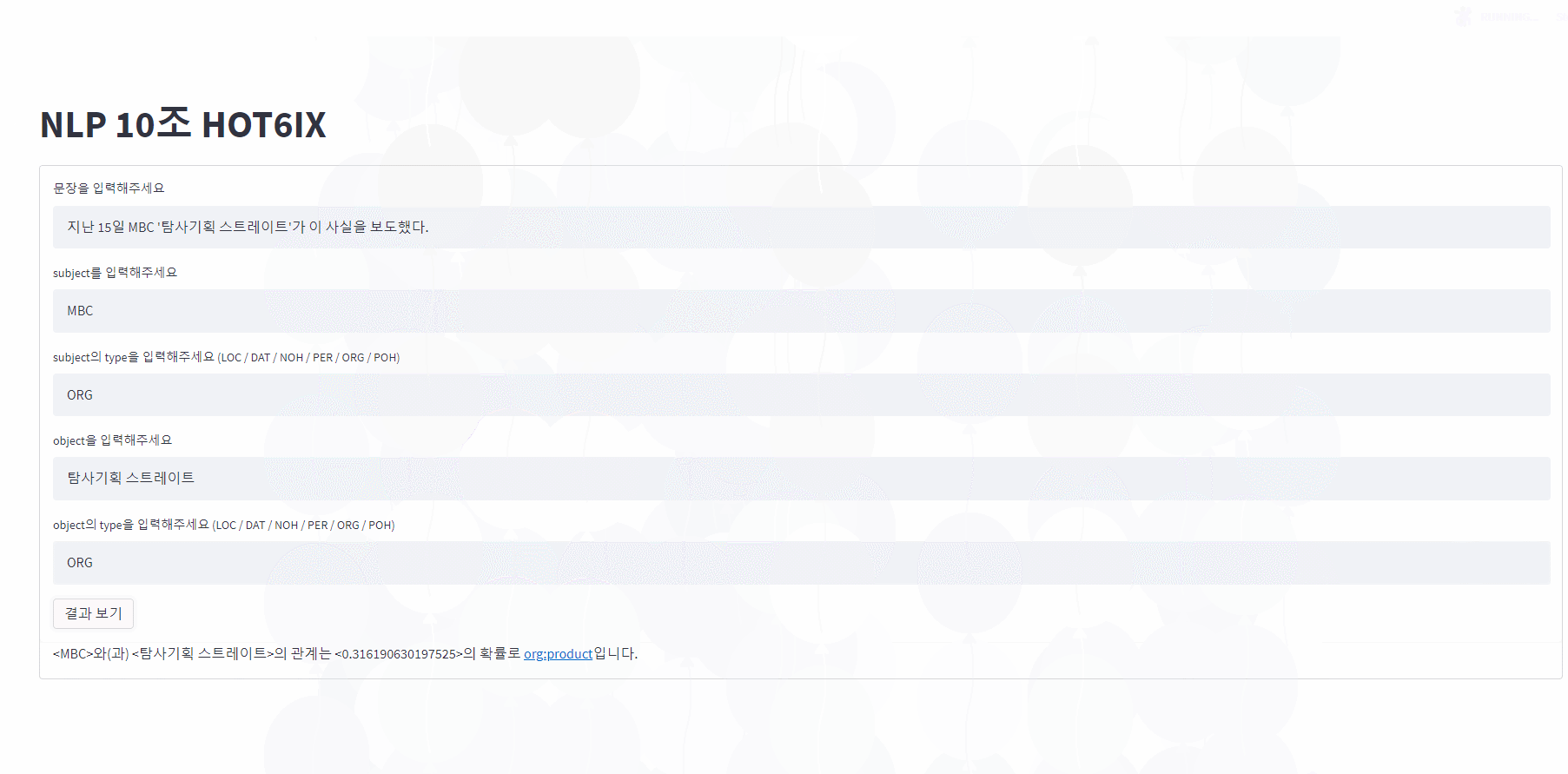
문장의 단어(Entity)에 대한 속성과 관계(30가지)를 예측하는 인공지능 만들기
문장, 단어에 대한 정보를 통해 문장 속에서 단어 사이의 관계를 추론하는 모델을 학습시켜서, 모델이 단어들의 속성과 관계를 파악하며 개념을 학습할 수 있게 만드는 것이 목표.
[NLP] 문장 내 개체간 관계 추출 대회 WrapUP 리포트(PDF 파일 다운로드) : KLUE_NLP_팀 리포트(10조).pdf
WrapUP 리포트 피드백 접기/펼치기
이가람 멘토님
1.종합의견 Level1 대회에서는 협업하는 측면에서 아쉬움이 있었던 캠퍼분들이 다소 계셨는데 이번 대회에서는 보다 나은 협업 방식에 대해서 여러가지로 고민하고 협업 툴도 적극적으로 활용하여 좋은 성과로 이어진 것 같습니다. 이번에 경험한 서로의 장점과 강점을 바탕으로 앞으로의 대회에서도 좋은 팀웤이 이루어지길 기대합니다.
2.우수한 점 -프로젝트 수행 task 별로 어느 정도의 기간동안 어떤 형태로 이루어졌는지 상세하게 드러나있어 주어진 기간을 효율적으로 활용하신 점이 전달되는 것 같습니다. -Imbalanced된 데이터 문제를 해결하기 위해 back translation 등의 data augmentation 기법을 적극적으로 잘 활용해주신 것 같습니다. -논문을 통해 충분히 사전 조사를 하고 프로젝트에 임하셨다는 것이 느껴졌습니다. -협업 툴을 사전에 정하고 학습하는 과정을 통해 효율적인 진행이 가능했던 것 같습니다. -데이터를 하나하나 뜯어보면서 태깅에 오류가 있는 점에 대해 해결방법을 다각도로 시도해보신 것 같습니다.
3.아쉬운 점 -<중요> 가장 중요한 점은 실험에서 각각의 방식을 어떤 이유로 고려했는지(예를 들어, 논문에서 이 방식이 어떤 장점이 있다고 소개되어 우리의 상황이 어떠어떠하기에 시도해보기로 했다 등) 나름의 근거를 가지고 가설을 세운 부분이 직접 명시되어야 하며 실험한 이후에 이 가설이 유효했는지 아니면 유효하지 않아 다른 어떤 새로운 가설을 세웠는지에 대한 설명이 보완되어야할 것 같습니다. 명확한 이유까지 파악하기 어려운 경우가 있더라도 근거를 제시해야 보다 객관적으로 신뢰할만한 결과가 될 것 같습니다. -EDA 및 전처리 과정에서 각각의 시각화를 통해 데이터의 분포 특징에 대해 어떤 해석을 도출해냈는지에 대해 같이 설명되었으면 더 좋을 것 같습니다. -논문 인용 방식이 저널처럼 엄격하게 지켜질 필요는 없으나 일관성있게 통일되면 더 좋을 것 같습니다. -중복 데이터/오태깅 데이터의 경우 각각의 사례를 간단히 포함시켜도 좋을 것 같습니다. -(마이너한 부분이지만) 중간에 코드를 캡처 이미지로 삽입한 부분이 있는데 리포트의 배경이 흰색이니 테마를 다크모드로 하는 것보다는 동일하게 흰색으로 하는 것이 독자에게 가독성이 좋을 것 같습니다. -대회에서는 이 부분까지 고려할 필요는 없지만 최종 프로젝트에서는 이 프로젝트가 어떤 비즈니스적인 가치를 가지고 실제 활용될 수 있을지 use case에 대한 시나리오가 제시되면 더 풍성한 발표가 될 것 같습니다.
지난 5주동안 적극적으로 해주셔서 감사합니다 :) 마지막까지 처음 마음가짐 유지하시면서 좋은 결실 거두시길 바랍니다!
| 김남현 | 민원식 | 전태양 | 정기원 | 주정호 | 최지민 |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
| Github | Github | Github | Github | Github | Github |
-
train.csv: 총 32470개
-
test_data.csv: 총 7765개
-
Data

-
Class
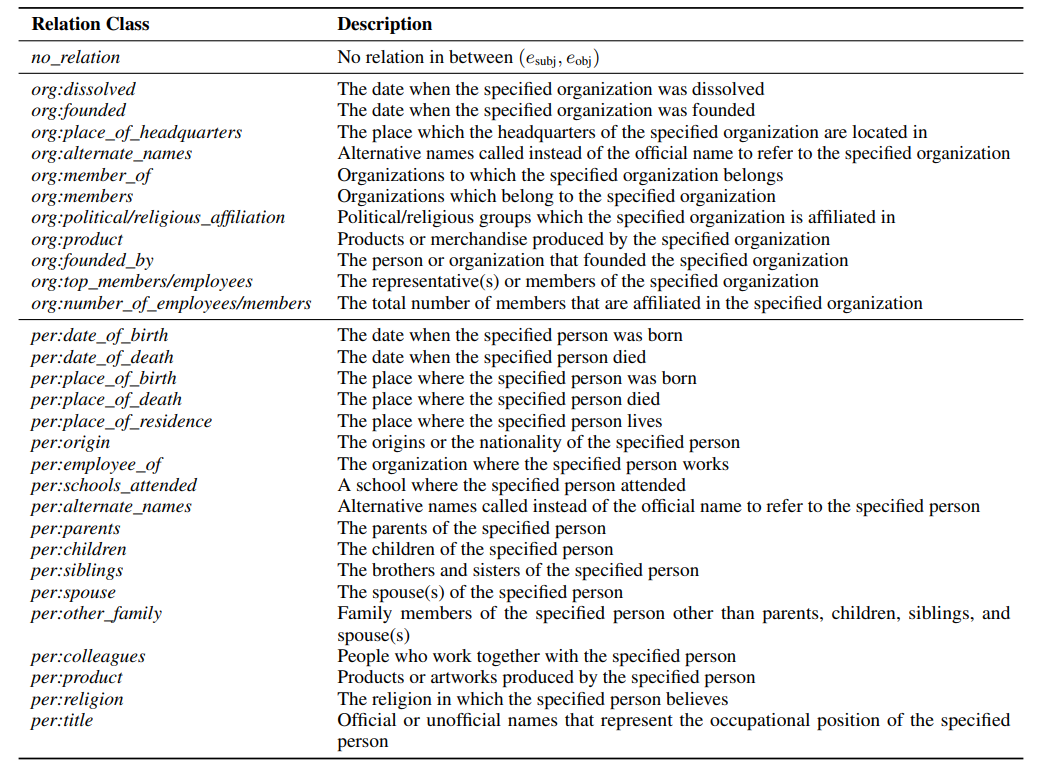
-
EDA
-
label
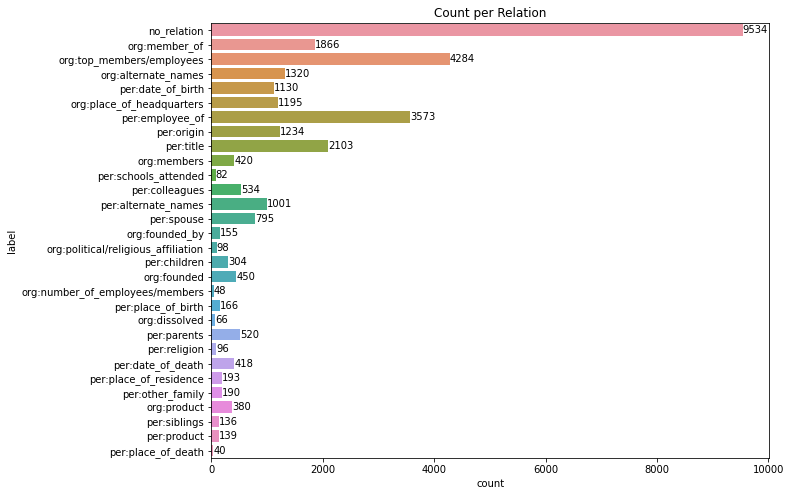
-
문장 분포 확인
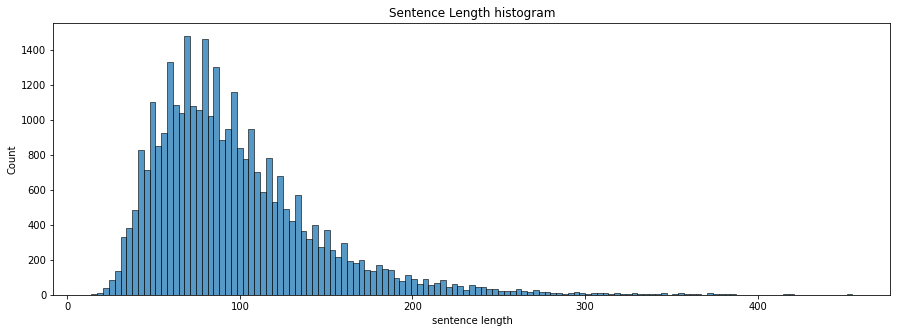
-
label별 문장 분포 확인
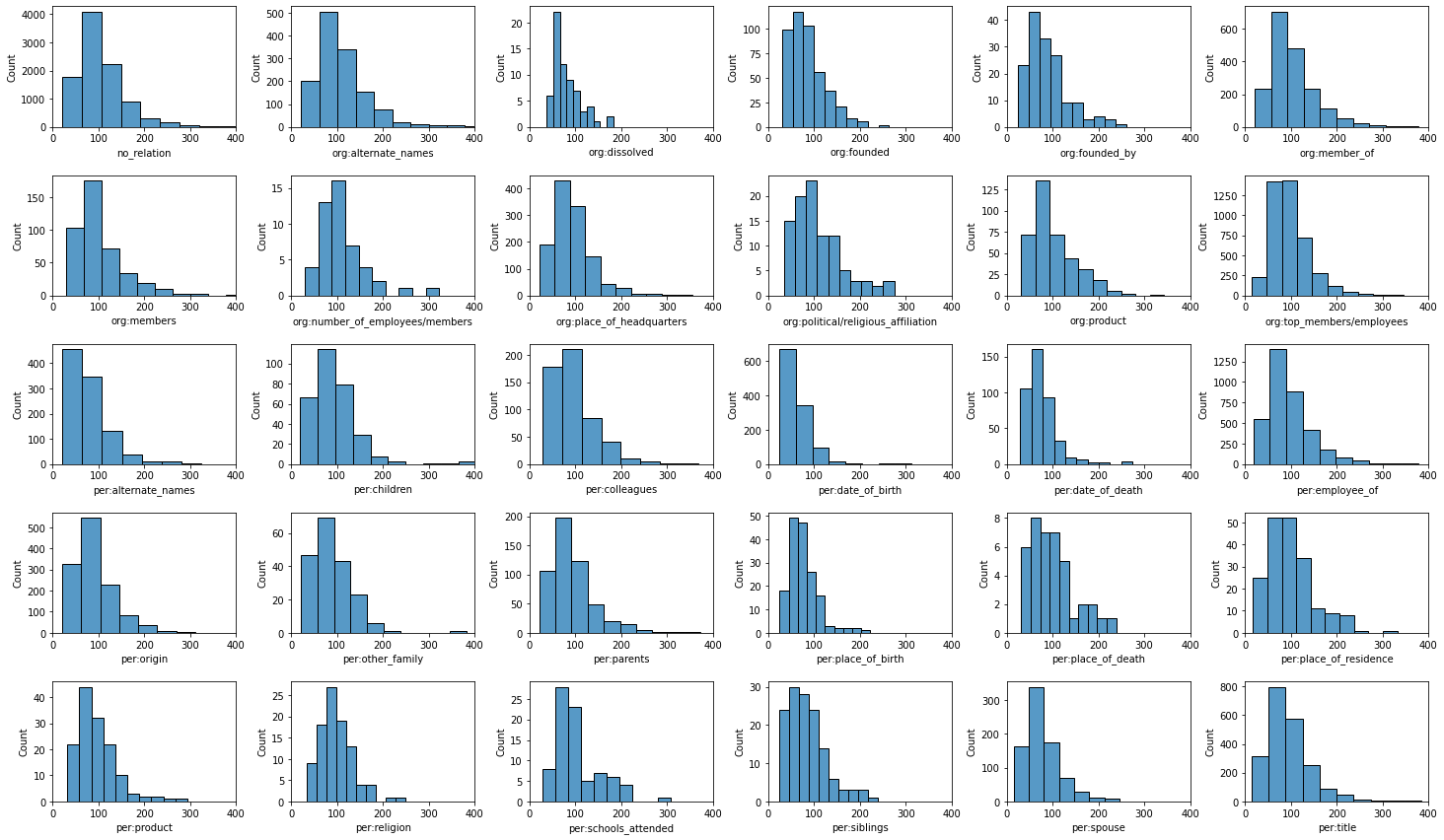
-
학습 데이터의 Subject, Object 단어의 type 분포 확인
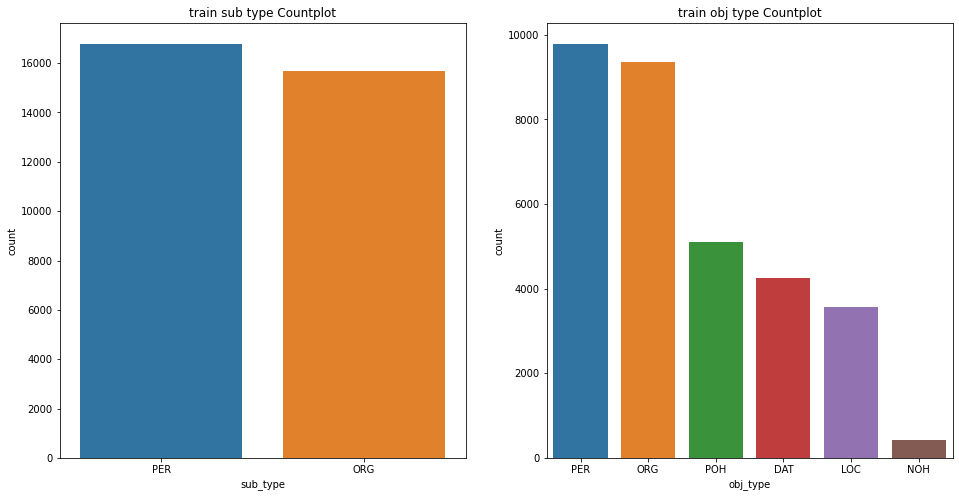
-
테스트 데이터의 Subject, Object 단어의 type 분포 확인
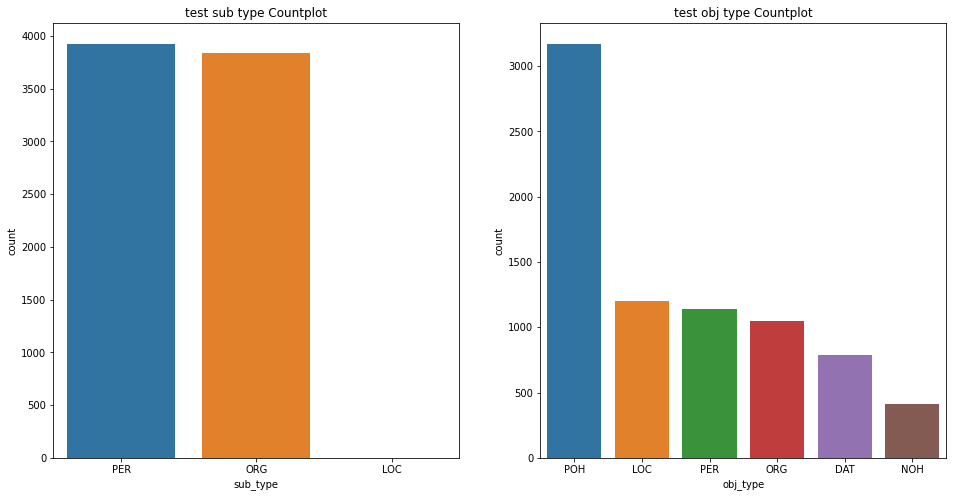
-
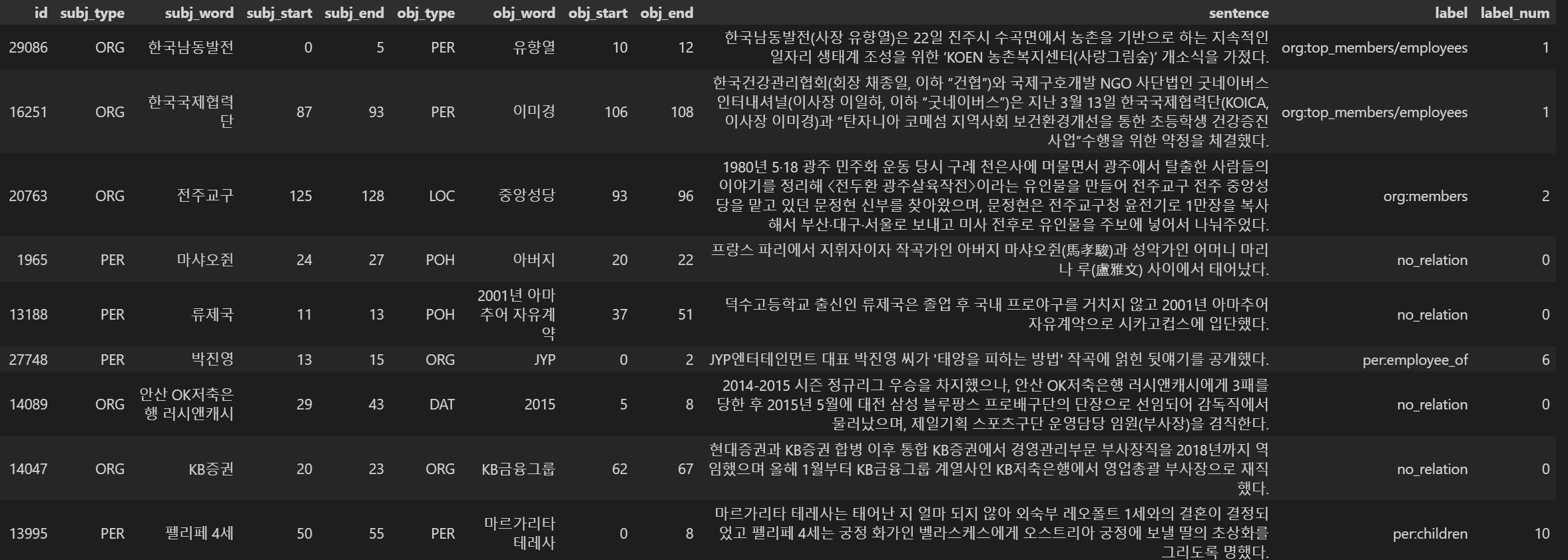
학습 데이터 : id-subj_info-obj_info-sen-label-label_num 순서로 구조 재구성
-
중복 데이터 : 84개의 중복 데이터 확인 후 제거
-
오태깅 데이터 제거 : 5개의 오태깅 데이터 확인 후 제거
-
데이터 교정 : 학습 데이터 중
subj_type,obj_type,label이 잘못된 데이터를 교정 → 오히려 성능이 떨어져 원래의 학습 데이터를 사용 -
Easy Data Augmentation : KoEDA 라이브러리를 사용하여 Random Insertion, Random Deletion, Random Swap, Synonym Replacement 적용 → 성능 개선 효과 없었음
- 논문 “1901.11196.pdf (arxiv.org)” 참고
-
-
Preprocess
-
Typed Entity marker(punct)
- 논문 “An Improved Baseline for Sentence-level Relation Extraction” 참고

원본 : 〈Something〉는 조지 해리슨이 쓰고 비틀즈가 1969년 앨범 《Abbey Road》에 담은 노래다.
→ Typed Entity marker(punct) : 〈Something〉는 # ^ [PER] ^ 조지 해리슨 # 이 쓰고 @ * [PER] * 비틀즈 @ 가 1969년 앨범 《Abbey Road》에 담은 노래다.
⇒ [CLS] 〈Something〉는 # ^ [PER] ^ 조지 해리슨 # 이 쓰고 @ * [PER] * 비틀즈 @ 가 1969년 앨범 《Abbey Road》에 담은 노래다. [SEP]
- 논문 “An Improved Baseline for Sentence-level Relation Extraction” 참고
-
Typed Entity marker(punct) + Query
- 논문 “BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding” 참고
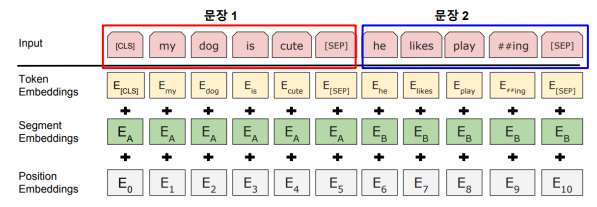
⇒ 기존 BERT의 Pretain 방식과 유사한 input으로 만들어줌
원본 : 〈Something〉는 조지 해리슨이 쓰고 비틀즈가 1969년 앨범 《Abbey Road》에 담은 노래다.
→ Typed Entity marker(punct) : 〈Something〉는 # ^ [PER] ^ 조지 해리슨 # 이 쓰고 @ * [PER] * 비틀즈 @ 가 1969년 앨범 《Abbey Road》에 담은 노래다.
→ Query : @ * [PER] * 비틀즈 @ 와 # ^ [PER] ^ 조지 해리슨 # 의 관계
⇒ [CLS] @ * [PER] * 비틀즈 @ 와 # ^ [PER] ^ 조지 해리슨 # 의 관계 [SEP] 〈Something〉는 # ^ [PER] ^ 조지 해리슨 # 이 쓰고 @ * [PER] * 비틀즈 @ 가 1969년 앨범 《Abbey Road》에 담은 노래다. [SEP]
- 논문 “BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding” 참고
-
Standard with Entity Location Token
- 논문 “엔티티 위치 정보를 활용한 한국어 관계 추출 모델 비교 및 분석” 참고

원본 : 〈Something〉는 조지 해리슨이 쓰고 비틀즈가 1969년 앨범 《Abbey Road》에 담은 노래다.
→ Standard with Entity Location Token : 〈Something〉는 [OBJ] 조지 해리슨 [/OBJ] 이 쓰고 [SUB] 비틀즈 [/SUB] 가 1969년 앨범 《Abbey Road》에 담은 노래다.
⇒ [CLS] 〈Something〉는 [OBJ] 조지 해리슨 [/OBJ] 이 쓰고 [SUB] 비틀즈 [/SUB] 가 1969년 앨범 《Abbey Road》에 담은 노래다. [SEP]
- 논문 “엔티티 위치 정보를 활용한 한국어 관계 추출 모델 비교 및 분석” 참고
-
Backtranslation : Selenium을 활용한 크롤링을 통해 한국어 → 영어 → 한국어 번역
원본 : 〈Something〉는 조지 해리슨이 쓰고 비틀즈가 1969년 앨범 《Abbey Road》에 담은 노래다.
→ "Something" is a song written by George Harrison and included by the Beatles on their 1969 album Abbey Road.
⇒ "Something"은 조지 해리슨이 작곡하고 비틀즈가 1969년 앨범 Abbey Road에 포함시킨 노래입니다.
-
성능 비교(micro f1)
(AutoModelForSequenceClassification.from_pretrained("klue/roberta-large"))
- Typed Entity marker(punct) : 71%
- Typed Entity marker(punct) + Query : 73%
- Standard with Entity Location Token : 70%
- Backtranslation : 72% → 생성 문장을 살펴보면 저품질 문장이 많음
-
-
Model
-
Pretrained Model
- klue/bert-base
- klue/roberta-large
-
Additional Layer
-
AutoModelForSequenceClassification
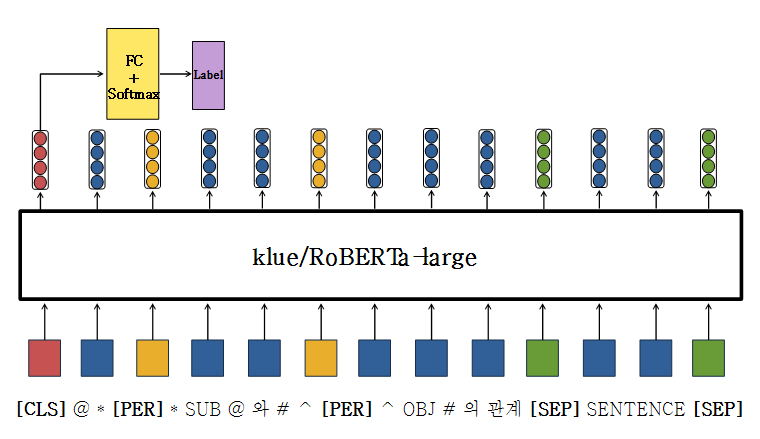
-
FC
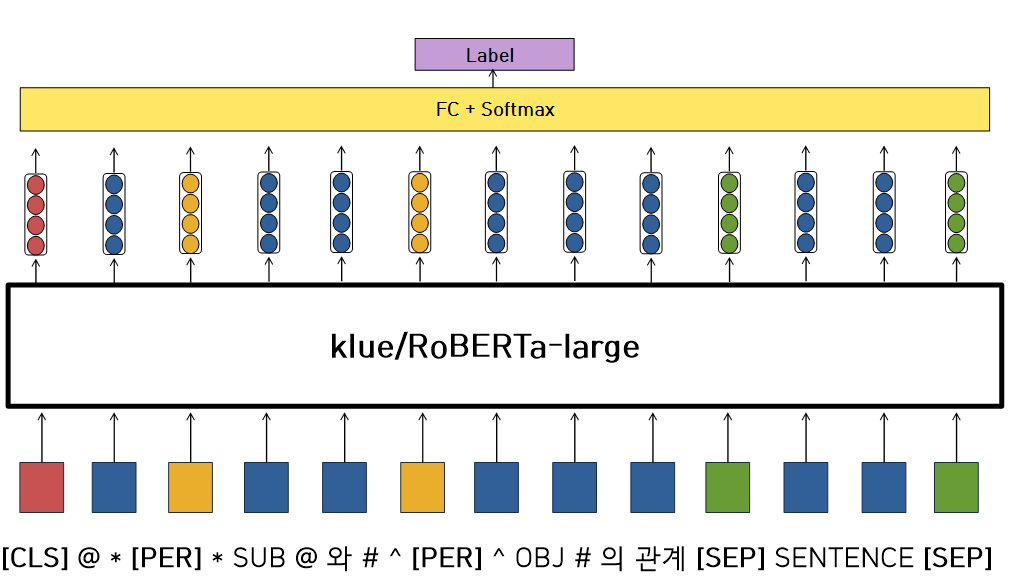
-
BiLSTM
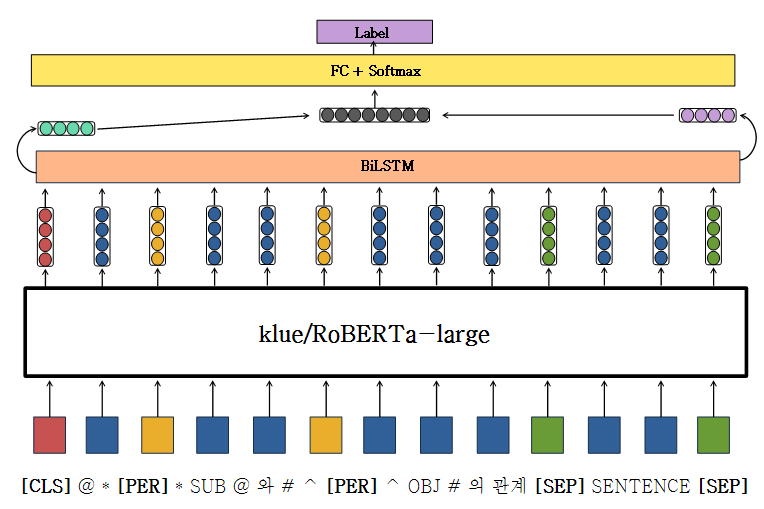
-
BiGRU
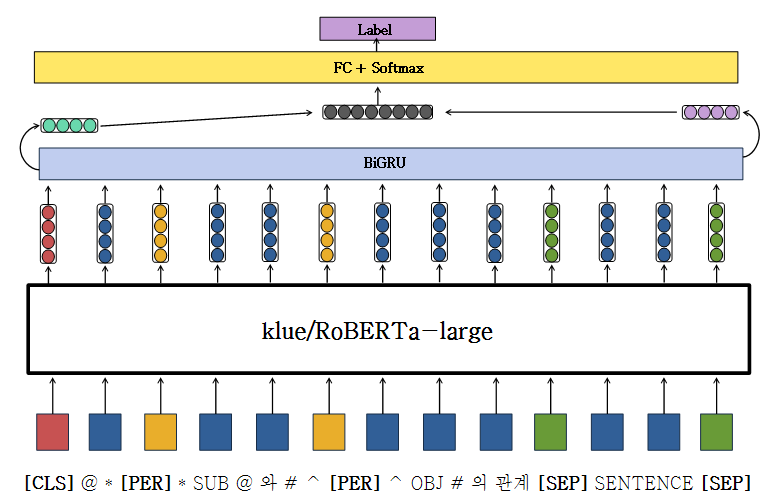
-
BiGRU + Multi-Head-Attention + BiGRU
- 논문 “UO UP V2 at HAHA 2019: BiGRU Neural
Network Informed with Linguistic Features for
Humor Recognition” 참고
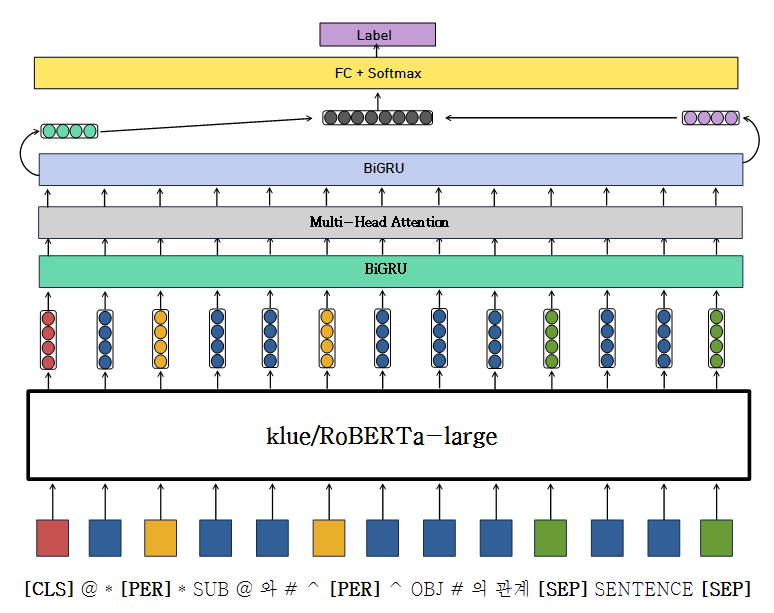
- 논문 “UO UP V2 at HAHA 2019: BiGRU Neural
Network Informed with Linguistic Features for
Humor Recognition” 참고
-
-
-
성능 비교(micro f1)
(Typed Entity marker(punct) + Query)
- AutoModelForSequenceClassification : 74.9%
- FC : 74.3%
- BiLSTM : 75.6%
- BiGRU : 75.1%
- BiGRU + Multi-Head-Attention + BiGRU : 74.4%
-
Hyper Parameter
-
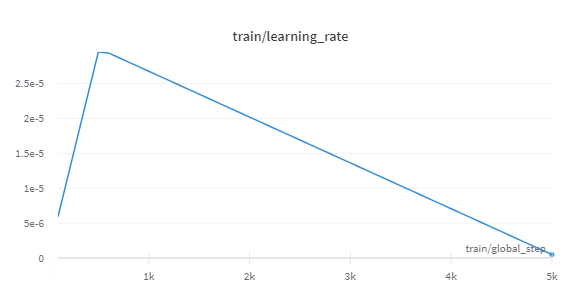
Learning Rate
- 3e - 5
- warmup_ratio : 0.1
- decay to 0
- weight decay : 0.01 → overfitting 방지
→ 논문 “An Improved Baseline for Sentence-level Relation Extraction” 참고
-
Batch Size
- 64
- 32
→ Out Of Memory가 일어나지 않는 선에서 Batch Size는 클수록 성능이 좋았음
-
max_len : 입력 Sentence의 최대 길이
- 160
- 256
→ 성능은 비슷했지만, 256은 batch size를 64로 했을 때, Out Of Memory가 발생해 160을 사용
-
Epoch
- 5
- 10
→ 똑같은 조건에서 Epoch가 10일 때, 성능이 더 떨어졌고, Overfitting이 발생했다고 판단
-
Loss Function
- Cross Entropy : Transformer의 Default
- Focal Loss : Class Imabalance를 개선하지만 CE와 성능 차이가 없었음
- Label Smoothing : 0.1 → Class Imbalance 개선
-
Optimizer
- AdamW : Transformer의 Default
-
-
Train
- StratifiedKFold : 성능 개선 효과 없었음
-
SOTA 모델
-
Preprocess : Typed Entity marker(punct) + Query
-
Model
- Pretrained Model : “klue/roberta-large”
- Additional Layer : BiLSTM
-
Hyper Parameter
-
Learning Rate
- 3e - 5
- warmup_ratio : 0.1
- decay to 0
- weight decay : 0.01
-
Batch Size : 64
-
max_len : 160
-
Epoch : 5
-
Loss Function
- Cross Entropy
- Label Smoothing : 0.1
-
Optimizer : AdamW
-
-
-
Ensemble
- Soft Voting
- 리더보드 상위 4개 모델 : 76.7338% (SOTA + 1%)
- 5개의 모델 : 75.5%
- AutoModelForSequenceClassification : 74.9%
- FC : 74.3%
- BiLSTM : 75.6%
- BiGRU : 75.1%
- BiGRU + Multi-Head-Attention + BiGRU : 74.4%
- 상위 3개의 모델 : 75.7%
- AutoModelForSequenceClassification : 74.9%
- BiLSTM : 75.6%
- BiGRU : 75.1%
- Soft Voting
-
최종 결과
-
Public(11팀 中 2등)

-
Private(11팀 中 3등)

-
-
프로토타입