Attention-Based Transformer for Robust Financial Time Series Classification
This Master's Thesis investigates the application of Attention-Based Transformer Encoders to build robust Buy/Sell classification models for financial time series data.
Financial markets are inherently non-stationary, noisy, and regime-dependent, which challenges conventional machine learning models.
To address these issues, this research integrates De Prado-inspired data preprocessing with a hybrid Transformer-LSTM architecture, enabling improved temporal modeling and robust evaluation.
- De Prado–Inspired Data Pipeline: Combines Dollar-Bars sampling with the Triple-Barrier Method for economically meaningful labeling.
- Hybrid Transformer–LSTM Model: Fuses long-range attention with short-term memory for richer temporal understanding.
- Leak-Free Evaluation Framework: Implements Purged K-Fold Cross-Validation to ensure realistic backtesting integrity.
| ML / DL Models |
|
| Programming & Frameworks |
|
| Financial / Data Tools |
|
| Utilities |
|
- Robust Data Structuring: Construct an information-dense, volatility-adjusted dataset using Lopez de Prado’s techniques.
- Advanced Temporal Modeling: Develop a Transformer Encoder–based architecture to learn multi-scale, non-linear dependencies.
- Rigorous Validation: Apply Purged K-Fold Cross-Validation to avoid temporal leakage and ensure true out-of-sample generalization.
This section describes advanced techniques for labeling financial time series and avoiding look-ahead bias during model evaluation, based on Advances in Financial Machine Learning (López de Prado, 2018).
The Triple-Barrier Method (TBM) is a robust labeling technique that generates economically meaningful labels for supervised learning in finance.
TBM sets three barriers around the entry price of a trade:
- Upper Barrier (Profit-Taking) – label
+1if price reaches a volatility-adjusted profit threshold. - Lower Barrier (Stop-Loss) – label
-1if price drops below a volatility-adjusted loss threshold. - Vertical Barrier (Time Limit) – label
0if a pre-defined time horizon expires without hitting upper/lower barriers.
- Produces labels reflecting actual profit/loss events.
- Adapts to market volatility using dynamic thresholds.
- Prevents stale trades with the vertical barrier.
- Reduces look-ahead bias, ensuring realistic model evaluation.
- Compute volatility-adjusted thresholds:
Upper Barrier = p_t + k * sigma_t
Lower Barrier = p_t - k * sigma_t
Where:
p_t= price at entrysigma_t= volatility estimatek= threshold multiplier
-
Monitor price until a barrier is hit or the vertical barrier (time limit) is reached.
-
Assign labels:
+1→ Upper barrier hit first (profit)-1→ Lower barrier hit first (loss)0→ Vertical barrier reached (neutral)
Purged K-Fold CV is an evaluation framework designed to avoid look-ahead bias in financial data, which is common in traditional K-Fold CV due to temporal dependence between samples.
- Data is split into
Kfolds like standard K-Fold. - Training samples that overlap with the test period are “purged” to prevent leakage of future information.
- Optionally, a “gap” can be introduced between training and test sets to further reduce overlap effects.
- Financial time series are non-i.i.d. and autocorrelated; standard K-Fold can inflate performance metrics by leaking information.
- Purging ensures that no training sample contains information from the future, producing more realistic out-of-sample performance estimates.
- Particularly important when using event-based labeling like TBM, where price movements affect multiple sequential samples.
- Leak-free evaluation of predictive models
- Accurate out-of-sample performance estimation
- Reduces false optimism in backtesting
Summary:
- TBM creates structured, economically meaningful labels for financial ML.
- Purged K-Fold CV ensures robust, leak-free model evaluation, preventing look-ahead bias common in traditional K-Fold for time series.
Reference:
- López de Prado, M. (2018). Advances in Financial Machine Learning. Wiley.
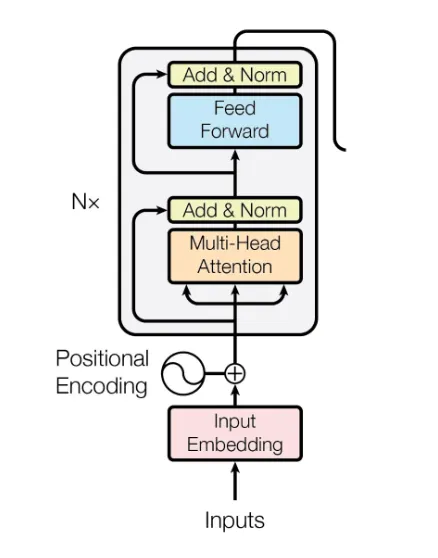
Source: ResearchGate
The Transformer Encoder is a fundamental component of the Transformer architecture, introduced in "Attention Is All You Need" by Vaswani et al. It generates contextualized representations for downstream tasks.
Each encoder block consists of:
- Multi-Head Self-Attention (MHSA)
- Add & Norm (Residual Connection + Layer Normalization)
- Position-Wise Feed-Forward Network (FFN)
- Add & Norm (Residual Connection + Layer Normalization)
Typically stacked 6+ times to form the complete encoder.
- Purpose: Capture dependencies between all tokens in the sequence.
- Mechanism: For each token, compute Query (Q), Key (K), and Value (V) vectors. Attention is:
- Multi-Heading: Uses multiple attention heads to capture different relational aspects.
- Residual Connection: Input + sub-layer output to aid gradient flow.
- Layer Normalization: Stabilizes training across features.
- Activation: ReLU or GELU.
- Function: Enhances token-wise representation independently.
- Residual + normalization, as before.
- 6+ identical layers
- Outputs of one layer feed as input to the next
- Enables progressively abstract sequence representations
Since Transformers lack intrinsic order, positional encodings are added:
- Parallelization: Faster than RNNs
- Long-Range Dependencies: Captures distant relationships
- Scalability: More layers/heads improve performance
| Parameter | Description |
|---|---|
| Dataset | Multi-asset OHLCV converted to Dollar-Bars |
| Feature Set | Technical indicators (RSI, MACD, Bollinger Bands), PCA-reduced |
| Labeling | Triple-Barrier Method |
| Validation | Purged K-Fold (5 folds) |
| Framework | PyTorch |
The table below summarizes the average performance of all models across the full range of look-back and look-forward window configurations (3, 5, 7, and 10 days) on the 9-stock dataset. These results demonstrate the overall superiority of the attention-based model.
| Model | Mean Precision (Across 16 Settings) | Mean AUC Score (Across 16 Settings) |
|---|---|---|
| Transformer (Hybrid) | 🟢 60.3% | 🟢 0.57 |
| Random Forest | 55.9% | 0.53 |
| Logistic Regression | 53.3% | 0.53 |
| SVM | 47.8% | 0.49 |
The Transformer model consistently outperforms traditional methods, achieving a meaningful predictive edge with a 60.3% average precision across all experimental settings.
- Attention layers captured latent inter-bar dependencies
- LSTM hybridization enhanced short-term recall
- False positives occurred during high-volatility periods
- Hybrid attention + Dollar-Bars/TBM improves robustness and interpretability
- Temporal Fusion Transformers for multi-horizon forecasting
- Volatility clustering features (GARCH, realized volatility)
- Adaptive fine-tuning for regime-aware updates
- Attention-based architectures improve predictive power and robustness in financial time series
- Data preprocessing (Dollar-Bars + TBM) ensures economically meaningful labeling
- Hybrid Transformer–LSTM captures macro and micro temporal patterns
Back to Main: README.md
Figures & Results: figures/
Thesis Report: thesis_document.pdf