

2015: 5,154 scientists co-authored one paper on the Higgs boson.
Today: We're launching the largest academic collaboration in human history
— 🏛️ Building the Library of Alexandria for AGI, Accelerating Automated Scientific Discovery.
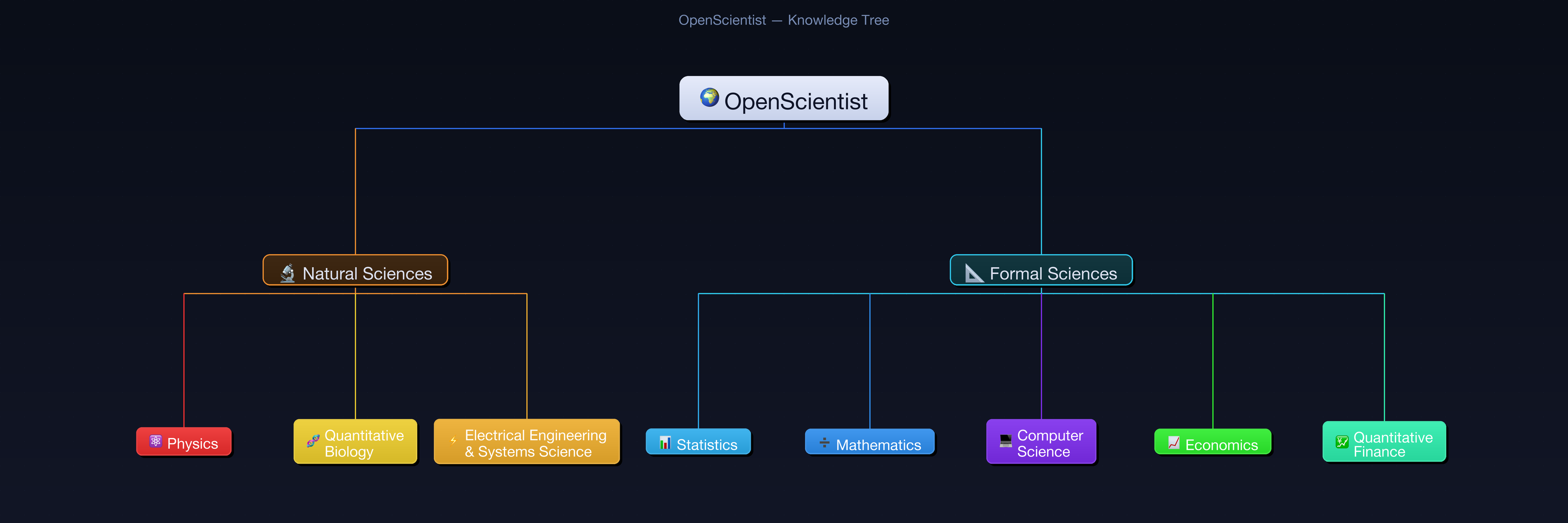
View Interactive Knowledge Tree →
Science is the last important problem left for AI to solve. Real scientific breakthroughs require something no model has: the hard-won intuition of researchers who've spent years at the frontier.
This intuition lives in your head — the know-how, the heuristics, the reasoning patterns, the "I just know this won't work" instinct. It never makes it into papers. It dies when you retire.
OpenScientist captures it before it's lost. We turn the tacit knowledge of the world's top researchers — their skills, thinking frameworks, and principles — into reusable AI agent skills (compatible with Claude Code and Codex CLI). Every contribution makes every AI scientist — now and in the future — smarter, permanently.
Each skill encodes the knowledge, tools, reasoning protocols, and common pitfalls of a scientific field. Skills can be written by domain experts or auto-extracted from your research conversations using /extract-knowhow. Point your AI agent at a skill, and it reasons like a domain expert.
npm install -g @openscientist/extract-knowhowClaude Code:
/extract-knowhow
Codex CLI:
$extract-knowhow
The command automatically scans your conversation history, extracts research know-how, and opens an interactive report in your browser — where you can review, edit, and submit skills directly to OpenScientist via GitHub.
Enable memory so the AI can access your history:
| Platform | How to enable | Settings link |
|---|---|---|
| ChatGPT | Settings > Personalization > turn on Memory and Reference chat history | Settings |
| Claude | Settings > Capabilities > turn on Memory | Settings |
| Gemini | Settings > Personal context > turn on Your past chats with Gemini | Settings |
Then paste this prompt into a new conversation:
Click to expand the full prompt
Review all our past conversations and extract every piece of reusable scientific research know-how. Focus exclusively on research activities — ignore general programming, setup, or casual conversations.
For each piece of know-how you find, classify it into one of these 10 categories:
1. Literature Search — search strategies, paper filtering, citation analysis
2. Hypothesis & Ideation — hypothesis formation, research question development
3. Math & Modeling — proof strategies, derivations, mathematical formulations
4. Experiment Planning — protocols, control strategies, variable selection
5. Data Acquisition — data sources, cleaning pipelines, labeling strategies
6. Coding & Execution — research coding patterns, library choices, debugging
7. Result Analysis — statistical methods, visualization, interpretation
8. Reusable Tooling — tools, methods, or workflows you helped me build
9. Paper Writing — writing structure, figure standards, claim formulation
10. Review & Rebuttal — self-critique, reviewer responses, revision strategies
Output each item in a SINGLE code block using this exact format, so I can copy-paste it directly:
---
name: short-descriptive-title
description: >
2-3 sentences explaining what this know-how is and when to apply it.
domain: [physics|mathematics|computer-science|quantitative-biology|statistics|eess|economics|quantitative-finance]
subdomain: specific-area
category: [01-literature-search|02-hypothesis-and-ideation|03-math-and-modeling|04-experiment-planning|05-data-acquisition|06-coding-and-execution|07-result-analysis|08-reusable-tooling|09-paper-writing|10-review-and-rebuttal]
author: "My Name (My Institution)"
expertise_level: intermediate
tags: [keyword1, keyword2]
dependencies: []
version: 1.0.0
status: draft
reviewed_by: []
---
## Purpose
[Expand the description into a full paragraph]
## Tools
- **[Tool Name]**: what it does, when to use it
## Domain Knowledge
### Key Concepts
[Core concepts relevant to this know-how]
### Fundamental Principles
[Underlying scientific principles]
## Reasoning Protocol
Step 1: [specific step]
Step 2: [specific step]
Step 3: [specific step]
## Common Pitfalls
- [Pitfall 1: what goes wrong and how to avoid it]
- [Pitfall 2: what goes wrong and how to avoid it]
## References
- Extracted from conversation history
- Extraction date: [today's date]
---
Rules:
- Extract EVERY piece of research know-how, no matter how small
- GENERALIZE from project-specific details to subdomain-universal principles. Ask: "Would this help any researcher in this field, not just me?" For example: "AMIX=0.05 worked for our LiFePO4 run" → "For GGA+U on transition metal oxides with localized d-electrons, reduce AMIX to 0.05"
- DE-IDENTIFY all output: remove file paths, usernames, project names, private URLs, collaborator names. Replace with generic descriptions. The only real name allowed is the author field.
- Focus on tacit knowledge: thinking frameworks, decision-making principles, diagnostic reasoning, heuristics — the kind of intuition that never makes it into papers
- DO NOT extract generic programming knowledge, AI tool usage patterns, or textbook basics
- DO NOT summarize or group multiple items — one skill file per know-how item
- After the code block, confirm whether that is the complete set or if any remain
After running, submit via: Submit your skill →
Write your own skill following the template, then submit via GitHub Issue →
Don't see your field? Propose a new area → · Need a skill but can't write it yourself? Request a skill →
Reviewers are domain experts who guard the scientific quality of skills in their subdomain. You need substantial peer-review experience in the relevant field.
What you do: Review submitted skills for scientific accuracy and completeness. Provide constructive feedback to contributors. Promote skill status from draft to reviewed once verified.
What you get: Approve or request changes on submissions in your subdomain.
Aligned with the arXiv category taxonomy. 8 domains, 155 subcategories.
| Domain | arXiv | Subcategories | Reviewer(s) |
|---|---|---|---|
| ⚛️ Physics | astro-ph, cond-mat, gr-qc, hep, nlin, physics, ... | 51 | Seeking reviewer |
| ➗ Mathematics | math | 32 | Seeking reviewer |
| 💻 Computer Science | cs | 40 | Seeking reviewer |
| 🧬 Quantitative Biology | q-bio | 10 | Seeking reviewer |
| 📊 Statistics | stat | 6 | Seeking reviewer |
| ⚡ Electrical Engineering & Systems Science | eess | 4 | Seeking reviewer |
| 📈 Economics | econ | 3 | Seeking reviewer |
| 💹 Quantitative Finance | q-fin | 9 | Seeking reviewer |
View all 155 subcategories in the interactive knowledge tree →
CC BY 4.0 — free to share and adapt, with attribution.
With gratitude to everyone who makes this possible:
Contributors → · Reviewers → · Sponsors → · Organizers →