面向多角色有声内容创作的桌面端 TTS 工具,基于 Cosyvoice3 TTS大模型 构建,提供文本编辑、角色配置、批量生成和本地 API 服务。
详细教程、页面说明、排错和完整更新记录已迁移到 Wiki: https://github.com/Moeary/CosyVoiceDesktop/wiki
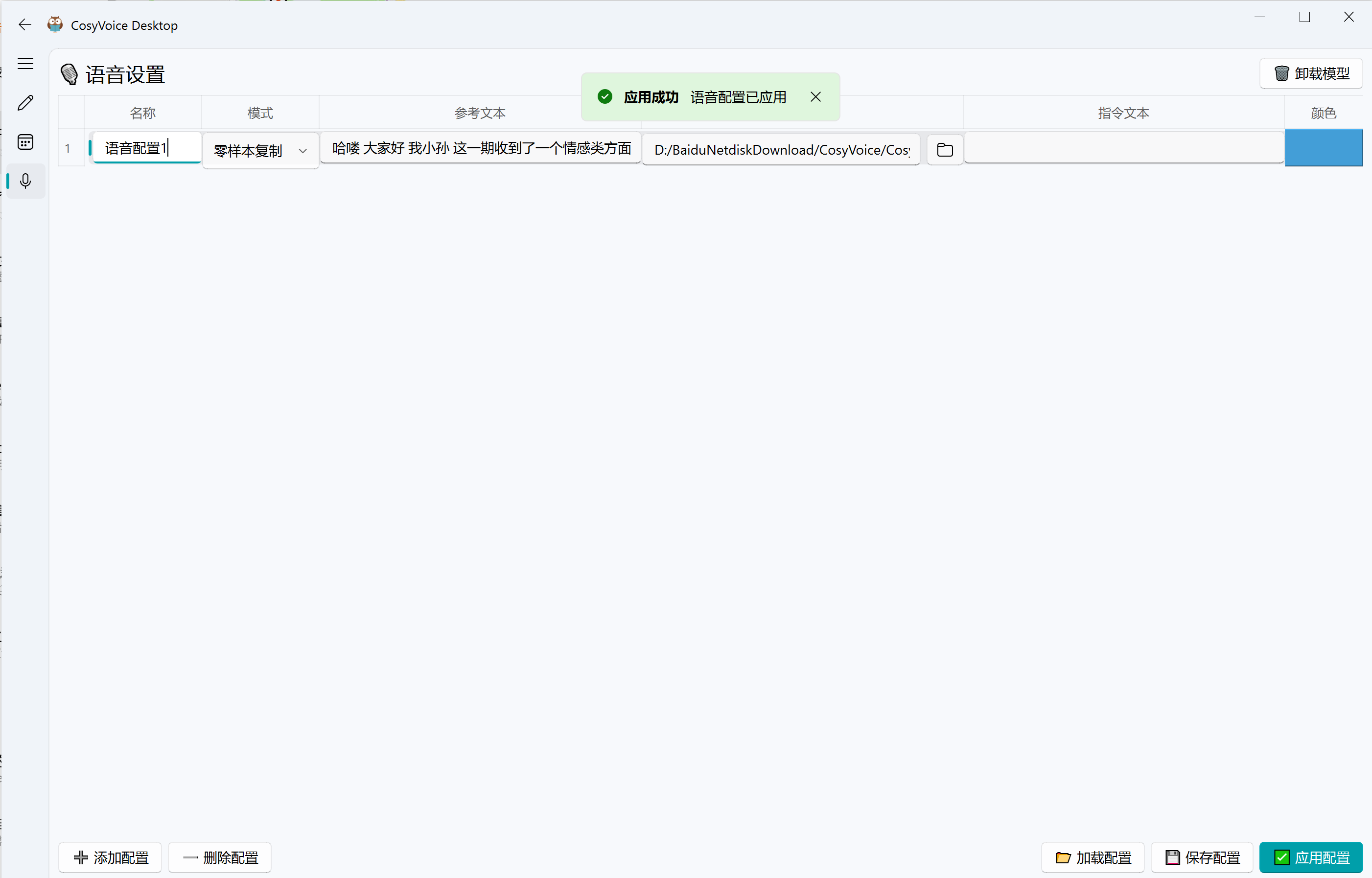
- 多角色语音配置:角色名、参考文本、参考音频、模式、颜色统一管理。
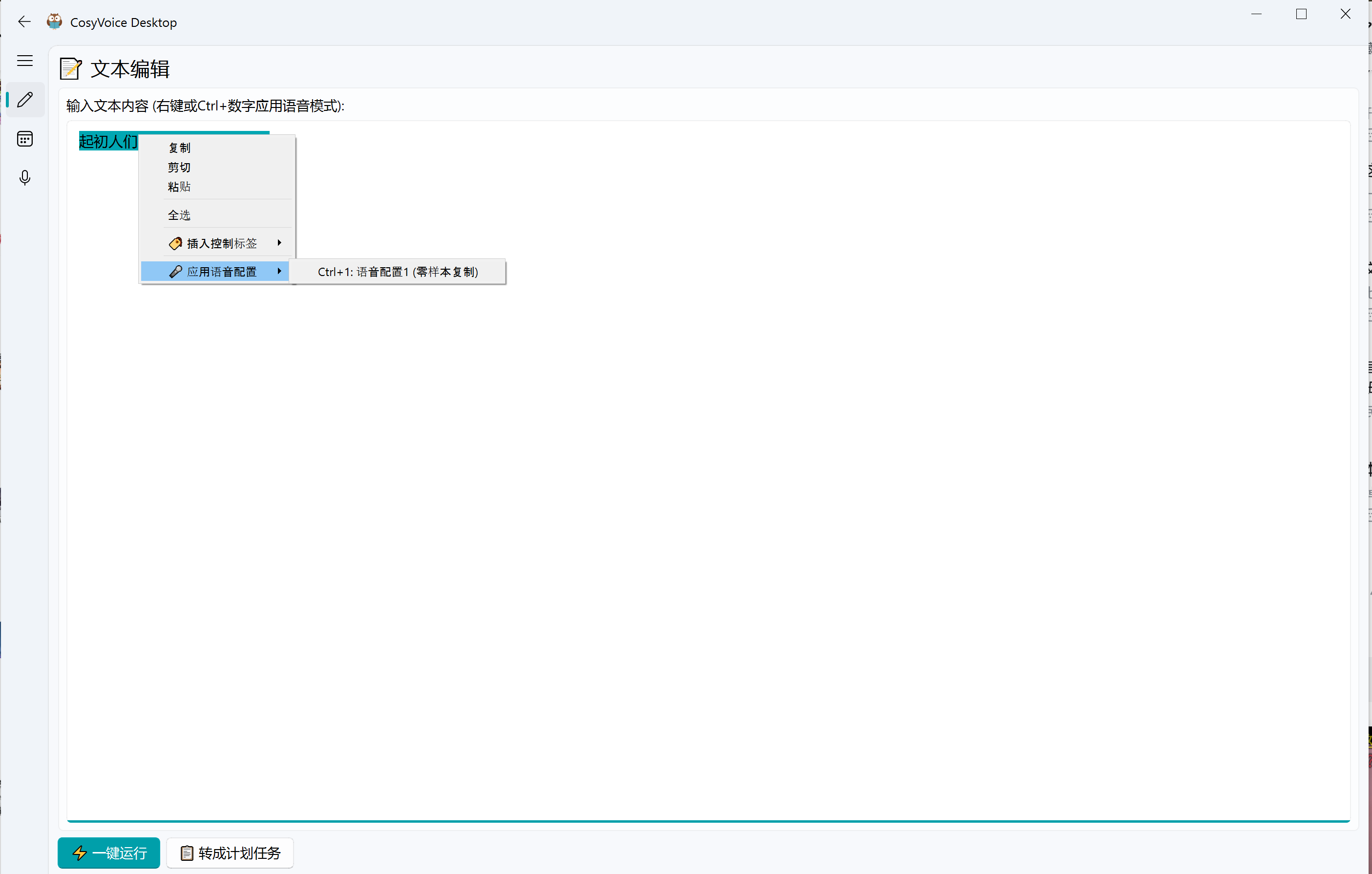
- 文本分段标注:支持右键 /
Ctrl+数字手动打标签。 - AI 角色分配:调用 OpenAI 兼容 LLM 按段落自动识别角色,可手动确认或全自动应用。
- 本地 TTS API:兼容 OpenAI TTS 风格接口,并提供酒馆以及 CosyVoice 原生接口。
- 模型下载与配置记忆:路径、项目、角色配置自动持久化。
- 发行版下载: GitHub Releases
- 项目主页: Moeary/CosyVoiceDesktop
启动后按下面顺序使用:
- 双击
StartCosyvoice.bat启动GUI应用,或使用pixi start run命令。 - 在“模型下载”页面准备
wetext和CosyVoice3模型。 - 打开语音设置页面,创建或导入角色配置,选择参考音频并点击"应用配置"(后续启动会自动加载)。
- 切换到文本编辑页面,输入或粘贴待合成文本,通过快捷键(Ctrl+数字)或右键工具菜单为不同段落分配语音配置(不同颜色标记)。
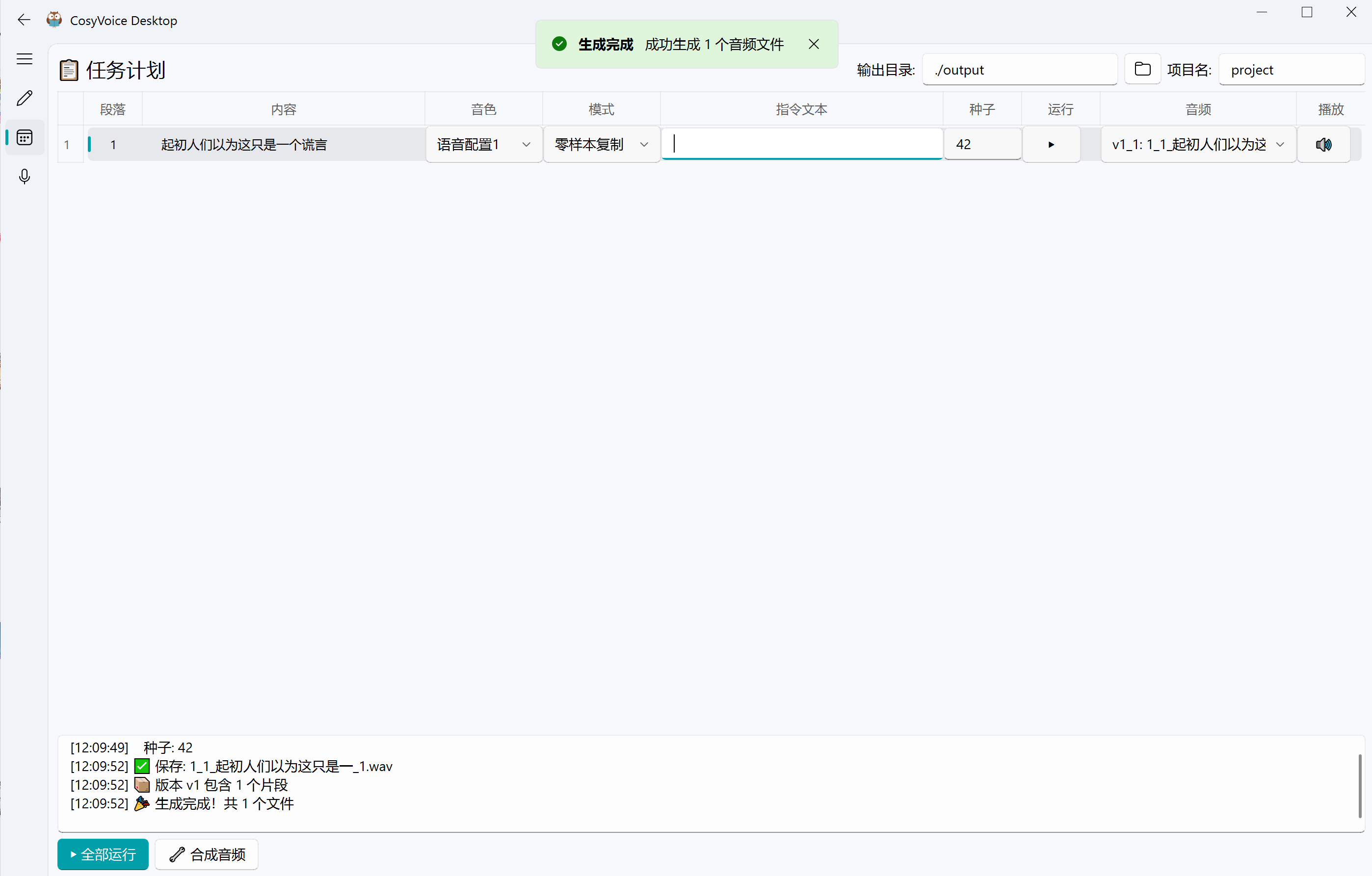
- 点击一键运行(或将任务转换为计划任务),切换到计划任务页面,查看任务执行日志和输出。
- 若合成效果不满意,可在计划任务页面点击"三角形运行按钮"进行重Roll。
- 所有段落合成完成后,点击"合成音频"按钮(需要ffmpeg环境),将分段音频合并为完整音频文件。
CosyvoiceDesktop_Demo_AV1.mp4
- 详细安装步骤、模型下载说明、页面教程、FAQ、更新日志和示例素材说明已迁移到 Wiki。
- 请确保你对输入文本、参考音频和生成内容拥有合法使用权。
- 本项目基于 CosyVoice 开源能力,遵循原项目许可证及使用规范。请在下载和部署前阅读并遵守 CosyVoice 官方条款。
- 用户在创作过程中应确保拥有使用输入文本、参考音频及生成内容的合法权利,不得侵犯第三方的版权、肖像权或其他合法权益。
- 禁止将本项目用于任何违法、违规或违背公共秩序与善良风俗的用途;如因违规使用导致损失,责任由用户自行承担。
- 项目提供的打包版本及脚本仅供个人学习与研究使用,未经许可不得用于商业再发行或转售。
- 项目维护者保留依据法律法规或社区反馈随时更新、暂停或终止服务与支持的权利。
使用 CosyVoiceDesktop 即视为同意上述协议条款。若您不同意任何条款,请立即停止使用并删除相关文件。