|
| 1 | +# 05.携程 Java 暑期实习一面 |
| 2 | + |
| 3 | +## Java 基础 |
| 4 | + |
| 5 | +### 1、Java 中有哪些常见的数据结构? |
| 6 | + |
| 7 | +图片来源于:JavaGuide |
| 8 | + |
| 9 | +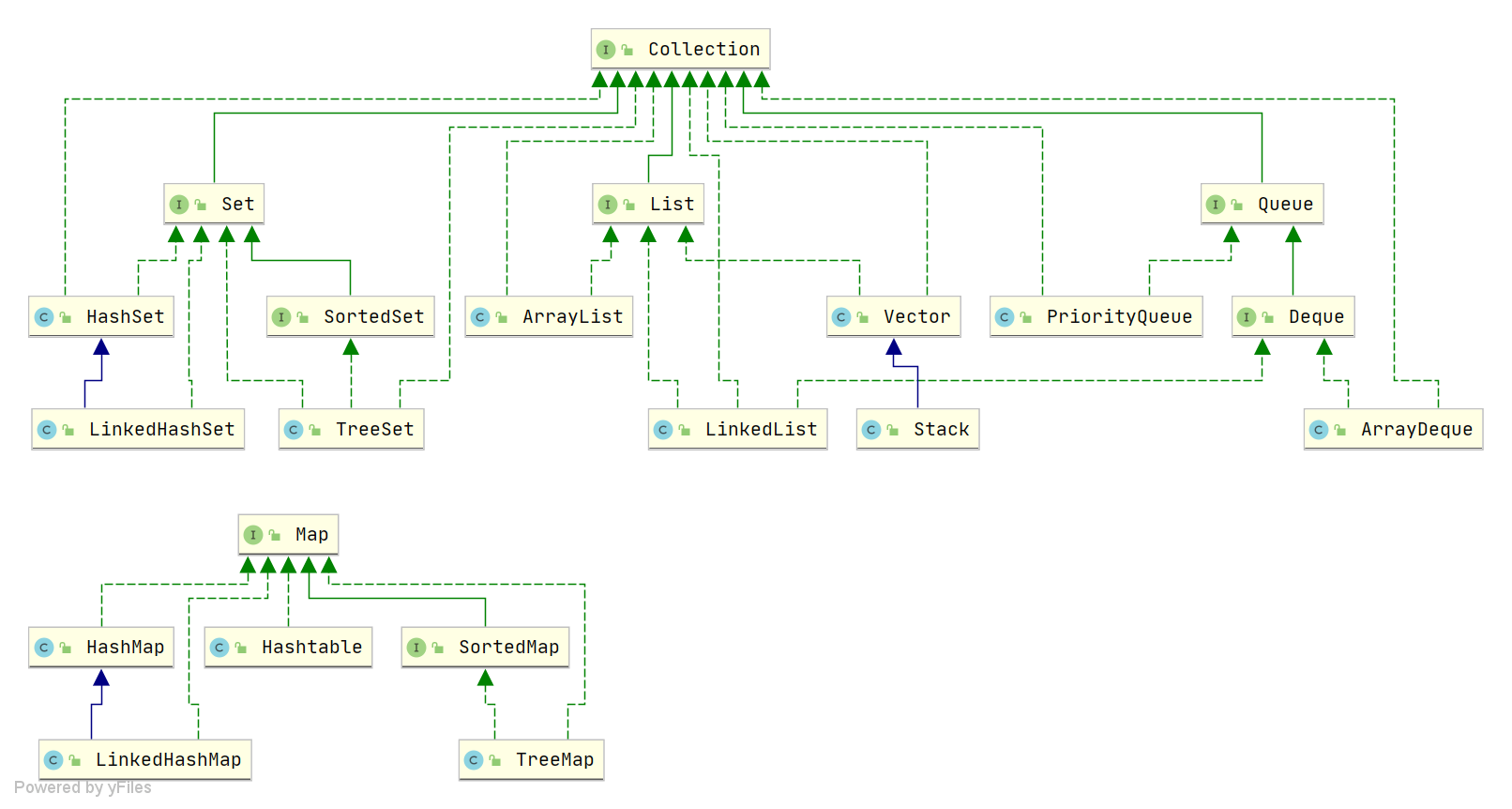 |
| 10 | + |
| 11 | +Java 中常见的数据结构包含了 List、Set、Map、Queue,**在回答的时候,只要把经常使用的数据结构给说出来即可,不需要全部记住** |
| 12 | + |
| 13 | +如下: |
| 14 | + |
| 15 | +**List 列表:** 有 ArrayList、LinkedList |
| 16 | + |
| 17 | +1、ArrayList 是动态数组 |
| 18 | + |
| 19 | +2、LinkedList 是双向链表 |
| 20 | + |
| 21 | + |
| 22 | + |
| 23 | +**Set 集合:** 有 HashSet、LinkedHashSet、TreeSet |
| 24 | + |
| 25 | +1、HashSet 基于 HashMap 实现,不保证元素的顺序,利用 Map 的 key 不能重复保证元素的唯一性 |
| 26 | + |
| 27 | +2、LinkedHashSet 继承自 HashSet,基于 LinkedHashMap 实现,通过链表维护元素的插入顺序 |
| 28 | + |
| 29 | +3、TreeSet 基于红黑树实现,元素自然排序或指定排序器排序 |
| 30 | + |
| 31 | + |
| 32 | + |
| 33 | +**Map 哈希映射:** 有 HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap |
| 34 | + |
| 35 | +1、HashMap 基于数组+链表+红黑树实现 |
| 36 | + |
| 37 | +2、LinkedHashMap 继承自 HashMap,通过链表维护元素插入顺序 |
| 38 | + |
| 39 | +3、TreeMap 基于红黑树实现,会对元素的 key 进行自然排序或指定排序器排序 |
| 40 | + |
| 41 | +4、ConcurrentHashMap 并发安全的 HashMap,在 JDK1.8 及以后通过 CAS + synchronized 实现线程安全 |
| 42 | + |
| 43 | + |
| 44 | + |
| 45 | +**Queue 队列:** 有 PriorityQueue、ArrayDeque |
| 46 | + |
| 47 | +1、PriorityQueue 基于优先级堆的优先队列实现,元素自然排序或指定排序器排序 |
| 48 | + |
| 49 | +2、ArrayDeque 基于数组的双端队列 |
| 50 | + |
| 51 | + |
| 52 | + |
| 53 | + |
| 54 | + |
| 55 | + |
| 56 | + |
| 57 | + |
| 58 | + |
| 59 | + |
| 60 | + |
| 61 | +### 2、HashMap 介绍一下,key 可以设置为 null 吗? |
| 62 | + |
| 63 | +HashMap 是哈希结构,存储 k-v 键值对,底层实现的话由数组+链表+红黑树进行实现 |
| 64 | + |
| 65 | +HashMap 中是可以存储 null 的 key 或 value 的,在 HashMap 中,为 null 的 key 只有一个,当传入 key 为 null 的时候,就会返回数组中索引为 0 的位置 |
| 66 | + |
| 67 | + |
| 68 | + |
| 69 | +### 3、ConcurrentHashMap 的 key 可以为 null 吗? |
| 70 | + |
| 71 | +**在 ConcurrentHashMap 中的 key 和 value 是不可以为 null 的** |
| 72 | + |
| 73 | + |
| 74 | + |
| 75 | +大家可以思考一下,**为什么 HashMap 中 key 可以为 null,ConcurrentHashMap 中不可以呢?** |
| 76 | + |
| 77 | +ConcurrentHashMap 是并发安全的,因此是在多线程环境中使用的,如果 key 或者 value 可以为 null 的话,那么就会存在 **二义性** |
| 78 | + |
| 79 | +因为一个线程在操作 ConcurrentHashMap 的时候,其他线程也有可能同时来进行修改,因此会存在 **二义性** 的问题: |
| 80 | + |
| 81 | +如果 key 为 null,就无法区分这个 key 是否存在于 ConcurrentHashMap 中;如果 value 为 null,就无法区分这个 value 是不存在 ConcurrentHashMap 中还是该 value 被置为了 null |
| 82 | + |
| 83 | + |
| 84 | + |
| 85 | +**HashMap 中的 key 和 value 为什么可以为 null?** |
| 86 | + |
| 87 | +而 HashMap 中的 key 和 value 可以为 null 就是因为 HashMap 是并发不安全的,因此使用 HashMap 的话,都是在单线程环境下使用,一个线程操作的时候,其他的线程不会同时操作,因此不会存在二义性问题 |
| 88 | + |
| 89 | + |
| 90 | + |
| 91 | +**那么为什么 ConcurrentHashMap 源码不设计成可以判断是否存在 null 值的 key?** |
| 92 | + |
| 93 | +如果 key 为 null,那么就会带来很多不必要的麻烦和开销。比如,你需要用额外的数据结构或者标志位来记录哪些 key 是 null 的,而且在多线程环境下,还要保证对这些额外的数据结构或者标志位的操作也是线程安全的。而且,key 为 null 的意义也不大,因为它并不能表示任何有用的信息。 |
| 94 | + |
| 95 | + |
| 96 | + |
| 97 | + |
| 98 | + |
| 99 | + |
| 100 | + |
| 101 | +### 4、如果多线程同时操作一个数据,会有什么问题,怎么解决? |
| 102 | + |
| 103 | +会存在线程安全的问题,只需要控制多个线程之间的操作同步,并且对该变量添加 `volatile` 关键字,保证该变量对多个线程的可见性即可 |
| 104 | + |
| 105 | +控制多个线程之间操作同步的话,通过 synchronized 或者 ReentrantLock 进行控制即可 |
| 106 | + |
| 107 | + |
| 108 | + |
| 109 | + |
| 110 | + |
| 111 | +### 5、线程池介绍一下,线程池的参数中最大线程数可以设得比核心线程数小吗? |
| 112 | + |
| 113 | +介绍线程池的时候,说一下线程池的几个核心参数,以及线程池的工作流程 |
| 114 | + |
| 115 | +线程池中重要的参数如下: |
| 116 | + |
| 117 | +- `corePoolSize` :核心线程数量 |
| 118 | +- `maximumPoolSize` :线程池最大线程数量 = 核心线程数+非核心线程数 |
| 119 | +- `keepAliveTime` :非核心线程存活时间 |
| 120 | +- `unit`:空闲线程存活时间单位(keepAliveTime单位) |
| 121 | +- `workQueue` :工作队列(任务队列),存放等待执行的任务 |
| 122 | + - LinkedBlockingQueue:无界的阻塞队列,最大长度为 Integer.MAX_VALUE |
| 123 | + - ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序 |
| 124 | + - SynchronousQueue:同步队列,不存储元素,对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务 |
| 125 | + - PriorityBlockingQueue:具有优先级的无界阻塞队列,优先级通过参数Comparator实现。 |
| 126 | +- `threadFactory` :线程工厂,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。 |
| 127 | +- `handler`: 拒绝策略 ,有4种 |
| 128 | + - AbortPolicy :直接抛出异常,默认策略 |
| 129 | + - CallerRunsPolicy:用调用者所在的线程来执行任务 |
| 130 | + - DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务 |
| 131 | + - DiscardPolicy :当前任务直接丢弃 |
| 132 | + |
| 133 | + |
| 134 | + |
| 135 | +新加入一个任务,线程池处理流程如下: |
| 136 | + |
| 137 | +1. 如果核心线程数量未达到,创建核心线程执行 |
| 138 | +2. 如果当前运行线程数量已经达到核心线程数量,查看任务队列是否已满 |
| 139 | +3. 如果任务队列未满,将任务放到任务队列 |
| 140 | +4. 如果任务队列已满,看最大线程数是否达到,如果未达到,就新建非核心线程处理 |
| 141 | +5. 如果当前运行线程数量未达到最大线程数,则创建非核心线程执行 |
| 142 | +6. 如果当前运行线程数量达到最大线程数,根据拒绝策略处理 |
| 143 | + |
| 144 | +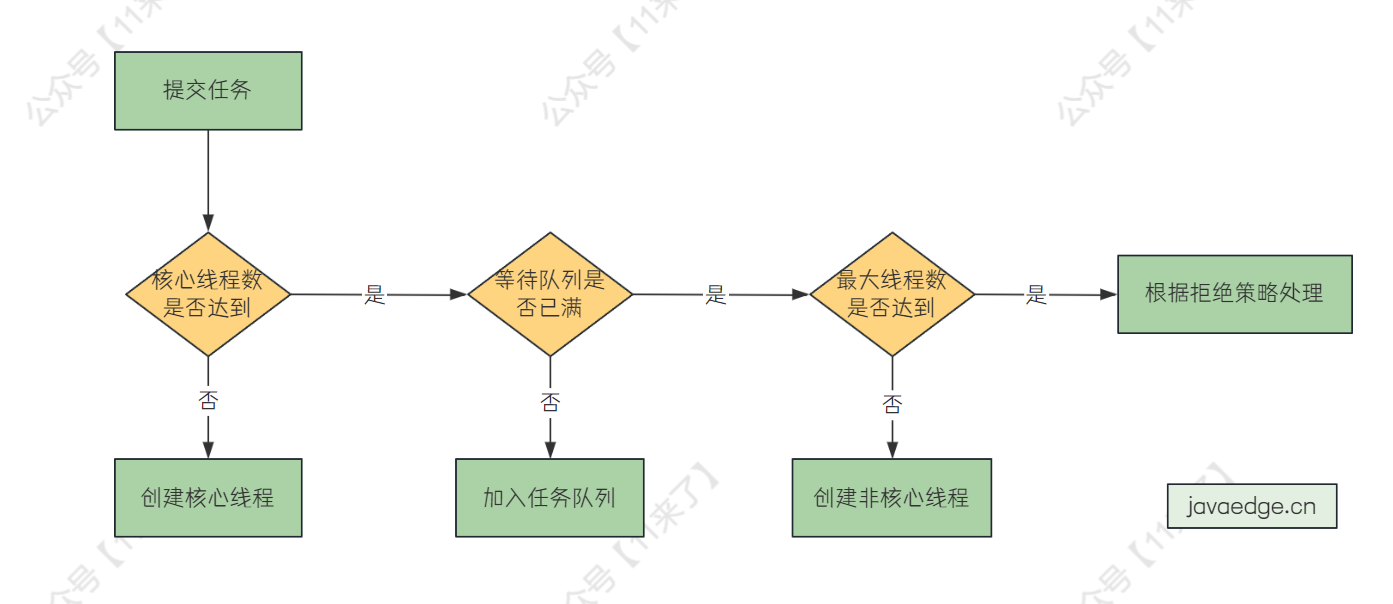 |
| 145 | + |
| 146 | + |
| 147 | + |
| 148 | + |
| 149 | + |
| 150 | + |
| 151 | + |
| 152 | +**线程池的参数中最大线程数可以设得比核心线程数小吗?** |
| 153 | + |
| 154 | +这个一般对于线程池有了解的都不会这么设置,最大线程数 = 核心线程数 +非核心线程数,所以最大线程数不可能比核心线程数还要小,这是错误的使用方式 |
| 155 | + |
| 156 | + |
| 157 | + |
| 158 | +## JVM |
| 159 | + |
| 160 | +### 6、JVM 内存结构 |
| 161 | + |
| 162 | +JVM 的内存结构分为:堆、虚拟机栈、本地方法栈、方法区 |
| 163 | + |
| 164 | +**堆** 主要存储 JVM 中创建的对象,堆是多个线程共享的空间 |
| 165 | + |
| 166 | +**方法区** 主要存储编译后的 Java 代码,也就是 class 文件的信息 |
| 167 | + |
| 168 | +**虚拟机栈** 包括了一个个的栈帧,每执行一个方法,都会为该方法生成一个栈帧压入虚拟机栈中,当执行完该方法之后,就会将该栈帧弹出虚拟机栈,这个虚拟机栈是 `线程私有` 的,方法中的一些局部变量也会在该栈帧中进行存储 |
| 169 | + |
| 170 | +**本地方法栈** 类似于虚拟机栈,里边的栈帧就是使用到的本地方法,本地方法指的是底层的非 Java 代码,因为 Java是一门高级语言,我们不直接与操作系统资源、系统硬件打交道。如果想要直接与操作系统与硬件打交道,就需要使用到本地方法了 |
| 171 | + |
| 172 | +**程序计数器** 用于存储当前线程所执行的字节码指令的行号,让线程知道下一次要执行哪一个字节码指令,程序计数器是线程私有的 |
| 173 | + |
| 174 | + |
| 175 | + |
| 176 | +**JVM 整体结构图如下:** |
| 177 | + |
| 178 | + |
| 179 | + |
| 180 | + |
| 181 | + |
| 182 | +### 7、垃圾回收算法和垃圾回收器都讲一下 |
| 183 | + |
| 184 | +垃圾回收算法有:标记-清除算法、复制算法、标记-压缩算法、分代回收算法 |
| 185 | + |
| 186 | +**标记-清除算法** 会从 GC Roots 开始遍历,将可到达的对象做标记,标记为存活对象,那么其他未标记的对象就是需要对象,将垃圾对象清除掉即可 |
| 187 | + |
| 188 | +缺点就是会产生内存碎片 |
| 189 | + |
| 190 | +**复制算法** 需要将内存区域分成大小相等的两块,当需要 GC 时,将其中一块内存区域中的存活对象复制到另外一块区域,再将原来的一块内存区域清空即可 |
| 191 | + |
| 192 | +优点是不会产生内存碎片,缺点是存在比较大的空间浪费 |
| 193 | + |
| 194 | +**标记-压缩算法** 是基于标记-清除算法的改进,先标记存活对象,之后将所有存活对象压缩到内存的一端,清除边界以外的垃圾对象即可 |
| 195 | + |
| 196 | +优点是既解决了标记-清除算法出现内存碎片的问题,又解决了复制算法中空间浪费的问题,但是效率低于复制算法 |
| 197 | + |
| 198 | +**分代收集算法** 是将 Java 堆分为新生代和老年代,这样就可以对不同生命周期的对象采取不同的收集方式,因为新生代中的对象生命周期短,存活率低,适合使用 `复制算法` ,老年代生命周期长,存活率高,适合使用 `标记-清除` 或 `标记-压缩` 算法 |
| 199 | + |
| 200 | + |
| 201 | + |
| 202 | +**垃圾收集器** |
| 203 | + |
| 204 | +有 8 种垃圾回收器,分别用于不同分代的垃圾回收: |
| 205 | + |
| 206 | +- 新生代回收器:Serial、ParNew、Parallel Scavenge |
| 207 | +- 老年代回收器:Serial Old、Parallel Old、CMS |
| 208 | +- 整堆回收器:G1、ZGC |
| 209 | + |
| 210 | +这里就不重复介绍了,可以参考 :[JVM垃圾收集器](http://11come.cn/pages/2b4756/#serial-%E4%B8%B2%E8%A1%8C%E5%9B%9E%E6%94%B6) |
| 211 | + |
| 212 | +JDK1.8 中默认的垃圾收集器是 **Parallel Scavenge(新生代)+Parallel Old(老年代)** |
| 213 | + |
| 214 | +**公司中一般使用指定 G1 作为垃圾收集器的比较多** ,因为 G1 的特点就是天生适合用于大内存机器,无论内存多大,都可以指定期望的 GC 停顿时间,这样不至于停顿时间太长,导致用户体验卡顿 |
| 215 | + |
| 216 | + |
| 217 | + |
| 218 | +### 8、有看过 GC 日志吗 |
| 219 | + |
| 220 | +GC 日志的话可以通过 **gceasy** 工具进行分析,首先需要设置 VM Options 来开启 GC 日志打印: |
| 221 | + |
| 222 | +```bash |
| 223 | + # 开启 GC 日志创建更详细的 GC 日志 |
| 224 | + -XX:+PrintGCDetails |
| 225 | + # 开启 GC 时间提示 |
| 226 | +-XX:+PrintGCTimeStamps,-XX:+PrintGCDateStamps |
| 227 | +# 打印堆的GC日志 |
| 228 | +-XX:+PrintHeapAtGC |
| 229 | +# 指定GC日志路径 |
| 230 | +-Xloggc:./logs/gc.log |
| 231 | +``` |
| 232 | + |
| 233 | + |
| 234 | + |
| 235 | +分析 GC 日志的话,就是将生成的 `gc.log` 日志文件放入 gceasy 工具进行分析,分析的话主要看以下这几个重要的参数: |
| 236 | + |
| 237 | +1、**新生代、老年代、元空间占用情况:** 看一下分配的空间大小以及峰值空间大小,来判断是否空间分配不合理,在 JDK1.8 中,如果不指定元空间大小,默认的初始值为 21MB,最大值为系统内存大小,元空间太小会导致频繁 Full GC 来提升元空间大小,因此这一点要注意 |
| 238 | + |
| 239 | +2、**平均/最大 GC 暂停时间:** 看一下暂停时间有没有特别长,如果特别长,说明是存在问题的 |
| 240 | + |
| 241 | +3、**GC 持续时间/GC 次数:** 判断 GC 持续时间是否过长、GC 次数是否频繁,如果 Full GC 较为频繁,也是存在问题的(因为 Full GC 比较慢,要减少 Full GC 次数),之后就要分析 Full GC 原因,看看是有大对象、还是产生非常多的对象、还是元空间初始值太小了 |
| 242 | + |
| 243 | +详细 GC 日志分析可参考:[通过 gceasy工具对生成的 GC 日志进行分析](http://11come.cn/pages/2b4756/#%E9%80%9A%E8%BF%87-gceasy%E5%B7%A5%E5%85%B7%E5%AF%B9%E7%94%9F%E6%88%90%E7%9A%84-gc-%E6%97%A5%E5%BF%97%E8%BF%9B%E8%A1%8C%E5%88%86%E6%9E%90) |
| 244 | + |
| 245 | + |
| 246 | + |
| 247 | +## MQ |
| 248 | + |
| 249 | +### 9、项目中的 RocketMQ 怎么保证消息一定发出去且收到了? |
| 250 | + |
| 251 | +这里问的就是 RocketMQ 如何保证消息的可靠性,避免消息在传输过程中丢失了 |
| 252 | + |
| 253 | +RocketMQ 作为分布式消息中间件,肯定是要尽可能保证消息传输的 **可靠性** ,要保证消息的可靠性,先来思考一下从哪些方面保证呢? |
| 254 | + |
| 255 | +这要看消息的生命周期,既然保证可靠性,那么就是要保证 A 发送给 B 的消息一定可以成功,那么首先要保证发送成功,其次要保证 B 接收成功,而在 RocketMQ 中,消息是先发送到 Broker 中了,那么还需要保证 MQ 在 Broker 中不会丢失 |
| 256 | + |
| 257 | +因此 RocketMQ 是从三方面保障了消息的可靠性: |
| 258 | + |
| 259 | +- 保证 **生产者发送消息** 的可靠性 |
| 260 | +- 保证 **Broker 存储消息** 的可靠性 |
| 261 | +- 保证 **消费者消费消息** 的可靠性 |
| 262 | + |
| 263 | + |
| 264 | + |
| 265 | +#### 发送消息的可靠性 |
| 266 | + |
| 267 | +RocketMQ 在发送端保证发送消息的可靠性主要就是通过 **重试机制** 来实现的 |
| 268 | + |
| 269 | +生产者发送消息分为了 **同步发送** 、 **异步发送** 、**单向发送** 三种方式: |
| 270 | + |
| 271 | +- **同步发送** :发送消息后,阻塞线程等待消息发送结果 |
| 272 | +- **异步发送** :发送消息后,并不会阻塞等待,回调任务会在另一个线程中执行 |
| 273 | +- **单向发送** :发送消息后,立即返回,不返回消息发送是否成功,因此不可以保证发送消息的可靠性 |
| 274 | + |
| 275 | + |
| 276 | + |
| 277 | +只有单向发送没有消息可靠性的保证,在 **同步** 和 **异步** 发送中,都可以通过设置发送消息的 **重试次数** 来保证发送端的可靠性,默认重试次数为 2 次 |
| 278 | + |
| 279 | +并且还可以设置如果发送失败,尝试发送到其他 Broker 节点 |
| 280 | + |
| 281 | +```java |
| 282 | +// 同步设置重试次数 |
| 283 | +producer.setRetryTimesWhenSendFailed(3) |
| 284 | +// 异步设置重试次数 |
| 285 | +producer.setRetryTimesWhenSendAsyncFailed(3); |
| 286 | +// 如果发送失败,是否尝试发送到其他 Broker 节点 |
| 287 | +producer.setRetryAnotherBrokerWhenNotStoreOK(true); |
| 288 | +``` |
| 289 | + |
| 290 | + |
| 291 | + |
| 292 | + |
| 293 | + |
| 294 | +#### 存储消息的可靠性 |
| 295 | + |
| 296 | +**可靠性保证一:消息落盘存储保证消息的可靠性** |
| 297 | + |
| 298 | +在消息发送到 Broker 之后,Broker 会将消息存储在磁盘中,这样如果 Broker 异常宕机之后,可以读取磁盘中的数据来保证消息的 **可靠性** |
| 299 | + |
| 300 | + |
| 301 | + |
| 302 | +**RocketMQ 如何存储消息:** |
| 303 | + |
| 304 | +RocketMQ 会先将消息写入到操作系统的 page cache 中,之后消息刷入磁盘分为了 **同步刷盘** 和 **异步刷盘** 两种方式, **默认是异步刷盘方式** |
| 305 | + |
| 306 | +page cache 就是将文件映射到内存中,这样直接操作内存比较快,避免了频繁的磁盘 IO |
| 307 | + |
| 308 | +Broker 通过 **page cache** 和 **异步刷盘** 在保证消息可靠性的前提下,还尽可能提升了消息写入的性能 |
| 309 | + |
| 310 | + |
| 311 | + |
| 312 | +**在 Broker 端写入消息的流程如下:** |
| 313 | + |
| 314 | +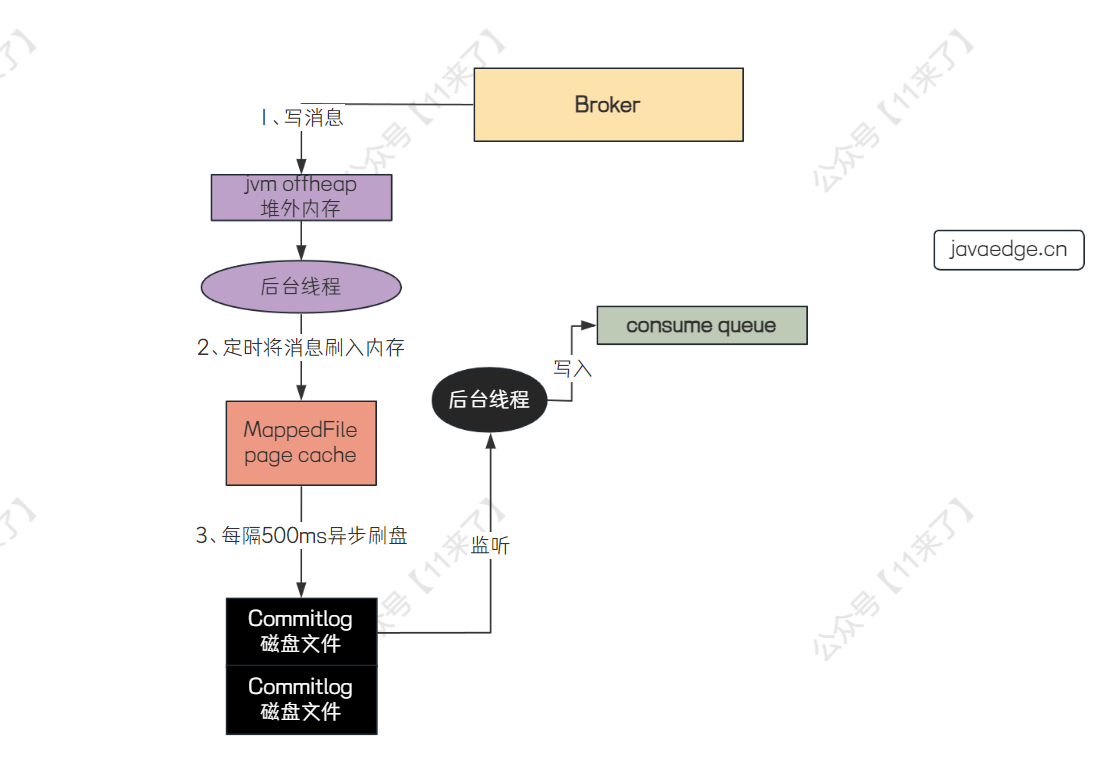 |
| 315 | + |
| 316 | +可以看到,这里写消息先写在了 JVM 的 **堆外内存** 中,而不是直接写在了 page cache 中,这是 RocketMQ 提供的 **transientStorePoolEnabled(瞬时存储池启用)机制** 来实现内存级别的读写分离(需要开启 `transientStorePoolEnabled(瞬时存储池启用)机制` 才会先写入 JVM 的堆外内存) |
| 317 | + |
| 318 | +为什么要将消息先写在 **堆外内存** 呢?如果高并发的读写请求都直接落在 page cache 中的话,那么会导致对 page cache 的竞争太过于激烈,因此令写请求操作 **堆外内存** ,读请求操作 **page cache** ,实现 **读写分离** ,避免高并发情况下对 page cache 的激烈竞争 |
| 319 | + |
| 320 | + |
| 321 | + |
| 322 | + |
| 323 | + |
| 324 | +**可靠性保证二:主从复制保证 Broker 的消息可靠性** |
| 325 | + |
| 326 | +上边是通过将消息写入磁盘来保证 Broker 存储端的消息可靠性,还有另一种方式:对 Broker 采用一主多从的方式部署,通过 **主从复制** 来保证消息的可靠性 |
| 327 | + |
| 328 | +在 Broker 主从复制时,会将 master 节点的消息同步到 slave 节点,slave 节点作为 master 节点的 **热备份** 存在,保证消息的可靠性 |
| 329 | + |
| 330 | + |
| 331 | + |
| 332 | +#### 消费消息的可靠性 |
| 333 | + |
| 334 | +消费者为了保证消息的可靠性: **会先消费消息,再提交消息消费成功的状态** ,不过可能会出现 **重复消费** 的情况,因此需要业务方保证 **幂等性** 来解决重复消费的问题(可以建立一张消息消费表来避免重复消费) |
| 335 | + |
| 336 | +**可靠性保证一:消息重试保证可靠性** |
| 337 | + |
| 338 | +消费者只有返回 **CONSUME_SUCCESS** 才算消费完成,如果返回 **CONSUME_LATER** 则会按照不同的延迟时间再次消费,如果消费满 16 次之后还是未能消费成功,则会将消息发送到死信队列 |
| 339 | + |
| 340 | + |
| 341 | + |
| 342 | +**可靠性保证二:死信队列保证可靠性** |
| 343 | + |
| 344 | +如果消息最终重试消费失败,并不会立即丢弃,而是将消息放入到了死信队列,之后还可以通过 MQ 提供的接口获取对应的消息, **保证消费消息的可靠性** |
| 345 | + |
| 346 | + |
| 347 | + |
0 commit comments