|
| 1 | +# 03-为啥LLM还没能完全替代你? |
| 2 | + |
| 3 | +## 1 不具备记忆能力的 |
| 4 | + |
| 5 | +它是零状态的,我们平常在使用一些大模型产品,尤其在使用他们的API的时候,我们会发现那你和它对话,尤其是多轮对话的时候,经过一些轮次后,这些记忆就消失了,因为它也记不住那么多。 |
| 6 | + |
| 7 | +## 2 上下文窗口的限制 |
| 8 | + |
| 9 | +大模型对其input和output,也就是它的输入输出有数量限制。为了保护它的,这计算能力或保护相当于一个带宽概念,如说openAI之前只有32k。最新上下文窗口扩张到128k,大概相当于一本《Clean Code》,这个角度来说,这个问题其实已被解决。 |
| 10 | + |
| 11 | +但其他很多模型上下文窗口还是比较小,就有很多限制。如不可发一长段prompt或提示词,也不可不停在那对话,你就需要注意计算你整个窗口token消耗,避免被截断,可能就没有办法去输入和输出。 |
| 12 | + |
| 13 | +## 3 实时信息更新慢,新旧知识难区分 |
| 14 | + |
| 15 | +基于预训练的模型,拿大量数据来在神经网络的训练,然后形成模型,它的知识库就依赖于拿去训练的这些材料。 |
| 16 | + |
| 17 | +底模数据较小时,就会出现幻觉,胡乱回答。 |
| 18 | + |
| 19 | +## 4 无法灵活的操控外部系统 |
| 20 | + |
| 21 | +很多大模型只可对话,但无法作为一个外脑去操作外部的一些系统。虽然chatgpt出现插件机制和插件开发工具。但实际使用后,它还是相当于提供一个非常标准的东西,定制开发或更深度融合较难。 |
| 22 | + |
| 23 | +比如想用大模型作为一个外脑操控智能家居系统、操控汽车,都需要有一些连接器和框架帮助。 |
| 24 | + |
| 25 | +## 5 无法为领域问题提供专业靠谱的答案 |
| 26 | + |
| 27 | +你问他一些泛泛而谈的东西,他都能回答很好,但是你一旦问他一个非常专业问题,他就回答不上来,因为这块儿的专业问题,他可能不涉及。虽然他回答的答案是看起来是像一个人在回答,但一眼就能看出来那个答案不对。 |
| 28 | + |
| 29 | +针对这些问题,业界基本提出两种解决方案,但也都不能完全解决。 |
| 30 | + |
| 31 | +## 6 解决方案 |
| 32 | + |
| 33 | +### 6.1 微调(Fine-tunning) |
| 34 | + |
| 35 | +主要解决的就是专业问题,专业知识库问题,包括知识更新问题。 |
| 36 | + |
| 37 | +就是把这些数据喂给我们的大模型啊,再做一次训练。基本上一次训练也无法解决这个知识感知信息问题,它只能更新它的数据库。成本较高。因为相当于把你的数据问喂给OpenAI,然后全量训练一次,成本相当高。 |
| 38 | + |
| 39 | +#### 适用场景 |
| 40 | + |
| 41 | +做一些自有的大量数据的行业模型。所谓行业模型,如某专业领域的公司,积累的大量数据,如制药公司在制药过程积累大量制药数据,你希望这个数据以AI智能方式指导你的工作,就可用这种方式。把你的这个数据去喂给喂给大模型,对它再做一次调教。 |
| 42 | + |
| 43 | +这涉及一个概念 |
| 44 | + |
| 45 | +#### MaaS |
| 46 | + |
| 47 | +module as a service,模型即服务。通过这个微调在大模型基础上灌入行业数据,实现这种行业模型,就适合手里拥有大量行业数据的。 |
| 48 | + |
| 49 | +这也只能解决领域数据专业性和知识库更新问题,无法解决操作外部系统、记忆能力、窗口扩张。 |
| 50 | + |
| 51 | +### 6.2 提示词工程(prompt engineering) |
| 52 | + |
| 53 | +通过上下文提示词设计引导。在LLM基础上把这种专业数据通过: |
| 54 | + |
| 55 | +- Embedding嵌入 |
| 56 | +- prompt提示词 |
| 57 | + |
| 58 | +这两个工具实现精准的专业回答,同时可实现: |
| 59 | + |
| 60 | +- 实时系统的感知 |
| 61 | +- 操作外部系统 |
| 62 | +- 记忆增强 |
| 63 | +- 窗口控制扩张 |
| 64 | + |
| 65 | +好处明显,无需训练,不用去在LLM上面做训练。 |
| 66 | + |
| 67 | +#### 适用场景 |
| 68 | + |
| 69 | +适合数据样本比较少的这种场景。如你有一本书,你希望说从这本书上去得到一些信息,但是你又不想去读它,你希望有个机器人,你问他问题,他直接从书里面找到答案。这种就可以把书的数据作为专业数据,然后嵌入到我们的这个LLM,然后再通过prompt方式去引导,得到一个精确的答案。 |
| 70 | + |
| 71 | +这过程中间甚至还可把这些答案,和我的打印机系统连接,可直接打印。 |
| 72 | + |
| 73 | +两种方式都可解决大模型问题,但适用场景不同,各自擅长点也不一样,很多时候,两者结合用效果较好。 |
| 74 | + |
| 75 | +微调,现在已经把门槛降到很低了,可直接把。把你想要微调的数据直接upload上去就可,但闭源大模型的数据安全的问题,数据所有性问题和成本问题。 |
| 76 | + |
| 77 | +提示词工程适合开源大模型,如chatglm,在本地部署大模型,再做这种词嵌入和提示词引导,就可本地实现专业行业模型。但底层LLM可能没用强大的,可能只是一个6b13b,它可能在语言组织或说一些智能度上稍低。代表就是 langchain。 |
| 78 | + |
| 79 | +## 7 总结 |
| 80 | + |
| 81 | +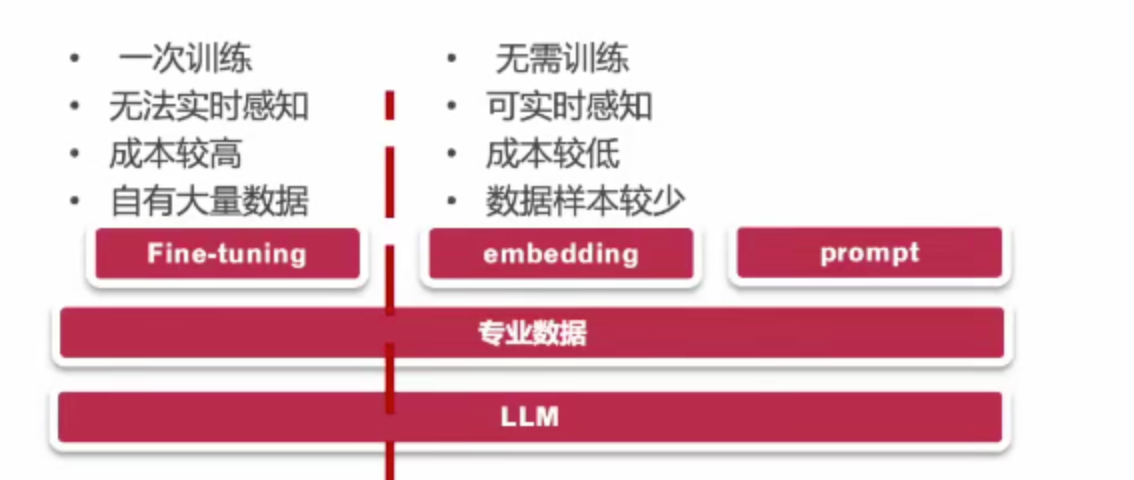 |
| 82 | + |
| 83 | +大模型的这几个问题都有,有两套这样的解决方案: |
| 84 | + |
| 85 | +- Model as aSerivce 模型即服务通过“微调”技术,在LLM基础上灌入行业数据,实现行业模型 |
| 86 | +- promptengineering提示词工程,通过上下文提示词设计31号LM输出精确答案 |
| 87 | + |
| 88 | +都有自己的优劣点,然后都有自己适用的场景。所以用什么方案呢?其实是看我们这个这个整个的这个项目的情况,专栏偏向第二种提示词工程, 即langchain框架的方式。 |
0 commit comments