
SonicMoE is a simple but blazing-fast Mixture-of-Experts (MoE) implementation optimized for NVIDIA Hopper (SM90), Blackwell datacenter (SM100, e.g. B200/B300), and Blackwell consumer (SM120, e.g. RTX 5090) GPUs. It mainly leverages CuTeDSL and Triton to deliver state-of-the-art performance through IO-aware optimizations. These 2 figures provide an overview of activation memory usage and training throughput on Hopper GPUs (H100) and Blackwell GPUs (B300). The current version of SonicMoE builds on the Grouped GEMM kernels from the QuACK library which is itself built on CUTLASS.
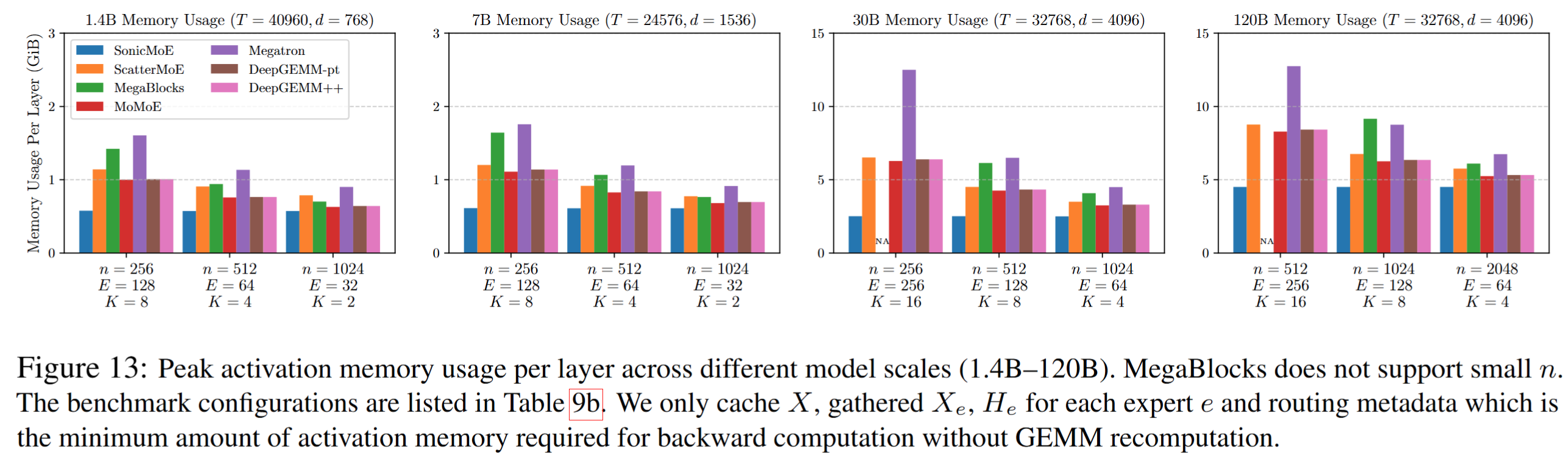
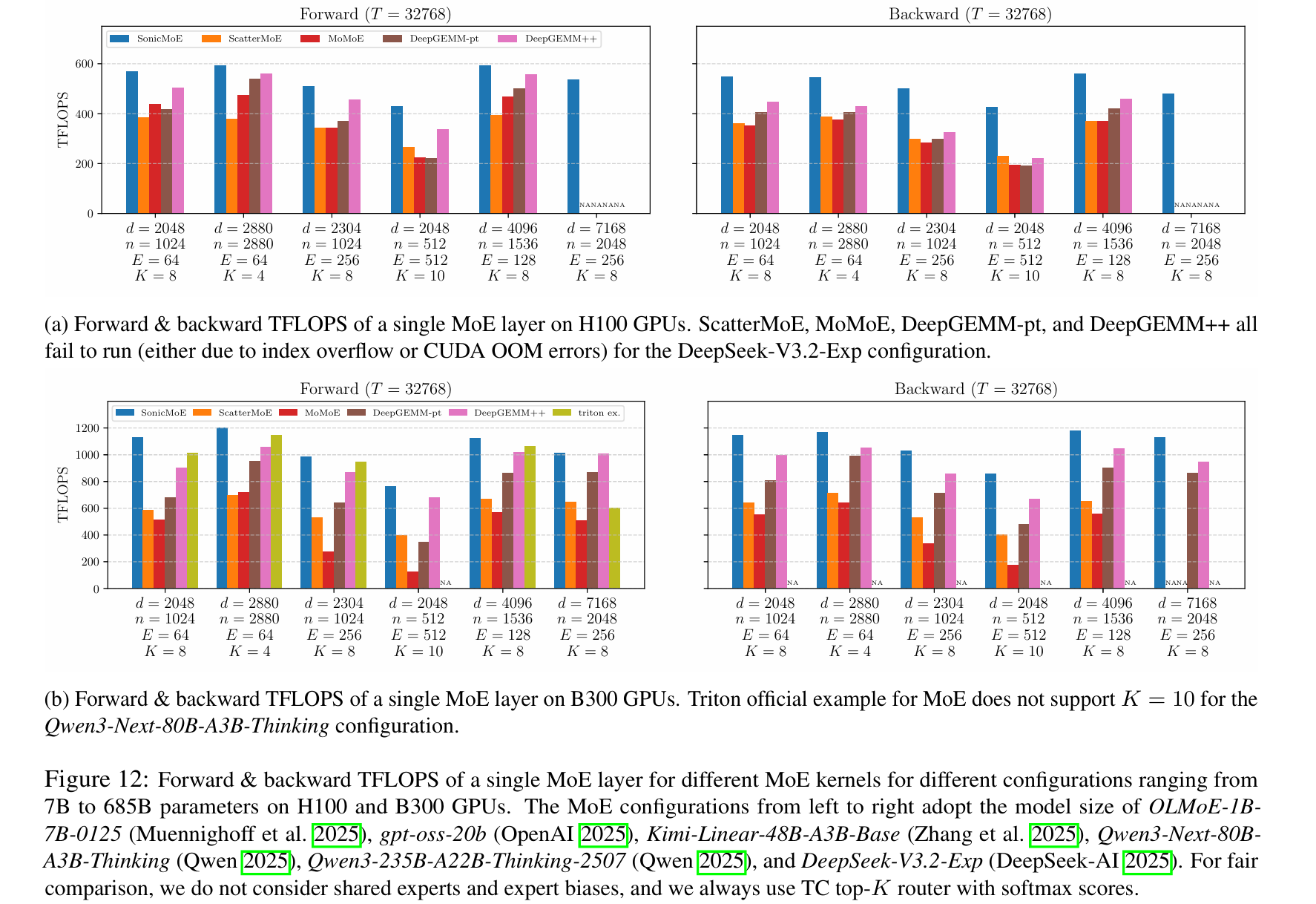
-
04/22/2026: We release a blogpost on SonicMoE's activation memory-efficient and IO-aware design, and how we extend it to Blackwell GPUs through QuACK's software abstraction.
-
04/19/2026: we release SonicMoE with Blackwell (SM100) support, built on QuACK's Grouped GEMM kernels.
- NVIDIA Hopper GPUs (H100, H200, etc.), Blackwell datacenter GPUs (GB200, B200, B300, etc.), or Blackwell consumer GPUs (e.g. RTX 5090, SM120)
- CUDA 12.9+ (13.0+ for B300 GPUs)
- Python 3.12+ recommended
- PyTorch 2.7+ (2.9.1 recommended)
B300 users: please manually upgrade Triton to 3.6.0 after installing PyTorch.
pip install sonic-moe# Clone the repository
git clone https://github.com/Dao-AILab/sonic-moe.git
cd sonic-moe
# Install dependencies
pip install -r requirements.txt
# Install SonicMoE
pip install -e .import torch
from sonicmoe import MoE, KernelBackendMoE
from sonicmoe.enums import ActivationType
# Create MoE layer
moe = MoE(
num_experts=128, # Number of experts
num_experts_per_tok=8, # Top-k experts per token
hidden_size=4096, # Hidden dimension
intermediate_size=1536, # Expert intermediate size
activation_function=ActivationType.SWIGLU, # SwiGLU activation
add_bias=False, # Add bias to linear layers
std=0.02, # Weight initialization std
).to(device="cuda", dtype=torch.bfloat16)
# Forward pass
x = torch.randn(32768, 4096, device="cuda", dtype=torch.bfloat16)
output, aux_loss = moe(x, kernel_backend_moe=KernelBackendMoE.sonicmoe)Run the test suite to verify correctness:
make test-
SonicMoE with TC top-K routing (softmax-over-topk, or
softmax(topk(logits))) and interleaved weight layout format for up-proj weightspython benchmarks/moe-cute.py --thiek 32768,4096,1024,128,8 --activation swiglu
-
SonicMoE with Qwen3-style routing (topk-over-softmax, or
topk(softmax(logits))) with topk probabilities renormalization and interleaved weight layout format for up-proj weightspython benchmarks/moe-cute.py --thiek 32768,4096,1024,128,8 --topk_over_softmax --norm_topk_probs
-
SonicMoE with token rounding routing (SwiGLU activation) and interleaved weight layout format for up-proj weights
python benchmarks/moe-token-rounding.py --routing nr --thiekq 16384,4096,1024,256,8,128
-
SonicMoE with concatenated weight layout format for up-proj weights
By default, SonicMoE expects
w1(the gated up-projection weights) in interleaved format:[gate_0, up_0, gate_1, up_1, ...]. HuggingFace models (Qwen3, Mixtral, DeepSeek, etc.) storegate_up_projin concatenated format:[gate_0, gate_1, ..., gate_{I-1}, up_0, up_1, ..., up_{I-1}].# Concatenated weight layout format with TC top-K routing python benchmarks/moe-cute.py --thiek 32768,4096,1024,128,8 --concat_layout
We welcome contributions! Please feel free to submit issues, feature requests, or pull requests.
This project is licensed under the Apache License 2.0 - see the LICENSE file for details.
If you use SonicMoE in your research, please cite:
@misc{guo2025sonicmoeacceleratingmoeio,
title={SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations},
author={Wentao Guo and Mayank Mishra and Xinle Cheng and Ion Stoica and Tri Dao},
year={2025},
eprint={2512.14080},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2512.14080},
}