![]()
AtlasPatch: Efficient Tissue Detection and High-throughput Patch Extraction for Computational Pathology at Scale


Project Page | Paper | Hugging Face | GitHub
- Installation
- Usage Guide
- Encoders
- Output Files
- SLURM job scripts
- Frequently Asked Questions (FAQ)
- Feedback
- Citation
- License
AtlasPatch targets Python 3.10+.
AtlasPatch needs the OpenSlide system library before you install the Python package.
# conda
conda install -c conda-forge openslide
# Ubuntu / Debian
sudo apt-get install openslide-tools
# macOS
brew install openslidepip install atlas-patchAll WSI-facing AtlasPatch commands use SAM2 for tissue segmentation.
pip install git+https://github.com/facebookresearch/sam2.gitThe default install stays lean. Install only the model stacks you need.
| Use case | Install |
|---|---|
| Broader built-in patch encoder registry | pip install "atlas-patch[patch-encoders]" |
| TITAN slide encoding | pip install "atlas-patch[titan]" |
| PRISM slide encoding | pip install "atlas-patch[prism]" |
| MOOZY slide or patient encoding | pip install "atlas-patch[moozy]" |
| All bundled slide encoder extras | pip install "atlas-patch[slide-encoders]" |
| All bundled patient encoder extras | pip install "atlas-patch[patient-encoders]" |
Some patch encoders still require upstream project packages in addition to atlas-patch[patch-encoders]:
# Optional: CONCH patch encoders
pip install git+https://github.com/MahmoodLab/CONCH.git
# Optional: MUSK patch encoder
pip install git+https://github.com/lilab-stanford/MUSK.gitUsing Conda Environment
# Create and activate environment
conda create -n atlas_patch python=3.10
conda activate atlas_patch
# Install OpenSlide
conda install -c conda-forge openslide
# Install AtlasPatch and SAM2
pip install atlas-patch
pip install git+https://github.com/facebookresearch/sam2.gitUsing uv
# Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# Create and activate environment
uv venv
source .venv/bin/activate # On Windows: .venv\\Scripts\\activate
# Install AtlasPatch and SAM2
uv pip install atlas-patch
uv pip install git+https://github.com/facebookresearch/sam2.gitAtlasPatch provides a flexible pipeline with 4 checkpoints that you can use independently or combine based on your needs.
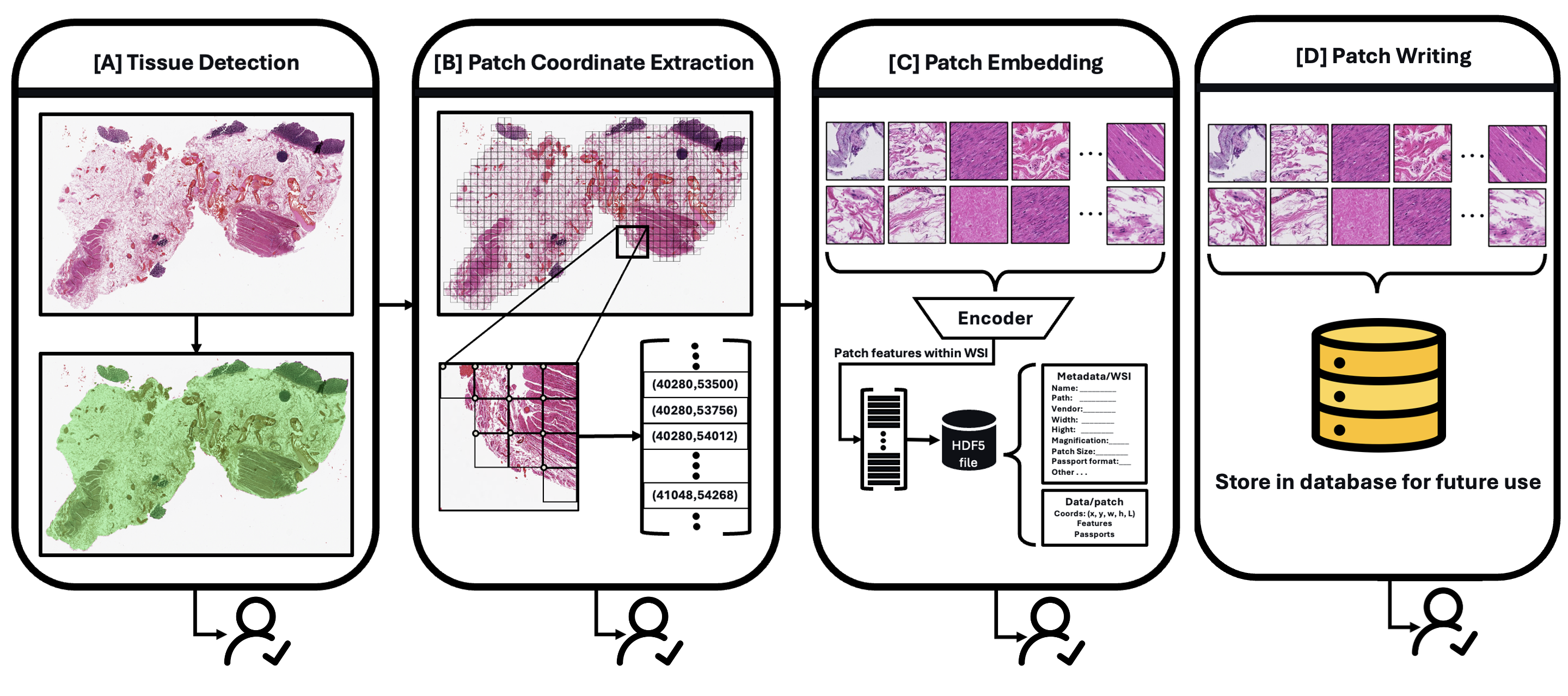
| Command | Use it when | Main outputs | Docs |
|---|---|---|---|
detect-tissue |
You only need tissue masks and overlays | visualization/ |
docs/commands/detect-tissue.md |
segment-and-get-coords |
You want patch locations now and feature extraction later | patches/<stem>.h5 |
docs/commands/segment-and-get-coords.md |
process |
You want the full patch pipeline, including patch features | patches/<stem>.h5, optional images/, optional visualization/ |
docs/commands/process.md |
encode-slide |
You want slide embeddings added to each slide H5 file | patches/<stem>.h5 with slide_features/<encoder> |
docs/commands/encode-slide.md |
encode-patient |
You have a CSV file that lists which slides belong to each patient | patient_features/<encoder>/<case_id>.h5 |
docs/commands/encode-patient.md |
atlaspatch process /path/to/slide.svs \
--output ./output \
--patch-size 256 \
--target-mag 20 \
--feature-extractors uni_v2 \
--device cudaThis writes a per-slide H5 file at ./output/patches/slide.h5 with:
coordsfeatures/uni_v2- slide metadata in file attributes
atlaspatch encode-slide /path/to/slides \
--output ./output \
--slide-encoders titan \
--patch-size 512 \
--target-mag 20 \
--device cudaencode-slide is WSI-only. It creates or reuses the per-slide patch H5, backfills the required upstream patch features automatically, and appends slide embeddings into the same file.
See Available Slide Encoders for the built-in encoder list, requirements, and install extras.
If you want multiple slide encoders in one run, they must be compatible with one patch geometry. For example, titan and prism need different patch sizes, so they should be run separately.
Create a CSV file:
case_id,slide_path,mpp
case-001,/data/case-001-slide-a.svs,0.25
case-001,/data/case-001-slide-b.svs,
case-002,/data/case-002-slide-a.svs,Then run:
atlaspatch encode-patient cases.csv \
--output ./output \
--patient-encoders moozy \
--patch-size 224 \
--target-mag 20 \
--device cudaencode-patient groups slides by case_id, creates or reuses per-slide H5 files, ensures the required patch features exist, and writes one patient embedding per case.
See Available Patient Encoders for the built-in encoder list, requirements, and install extras.
From atlaspatch info:
- WSI formats:
.svs,.tif,.tiff,.ndpi,.vms,.vmu,.scn,.mrxs,.bif,.dcm - image formats:
.png,.jpg,.jpeg,.bmp,.webp,.gif
Below are some examples for the output masks and overlays (original image, predicted mask, overlay, contours, grid).
Quantitative and qualitative analysis of AtlasPatch tissue detection against existing slide-preprocessing tools.
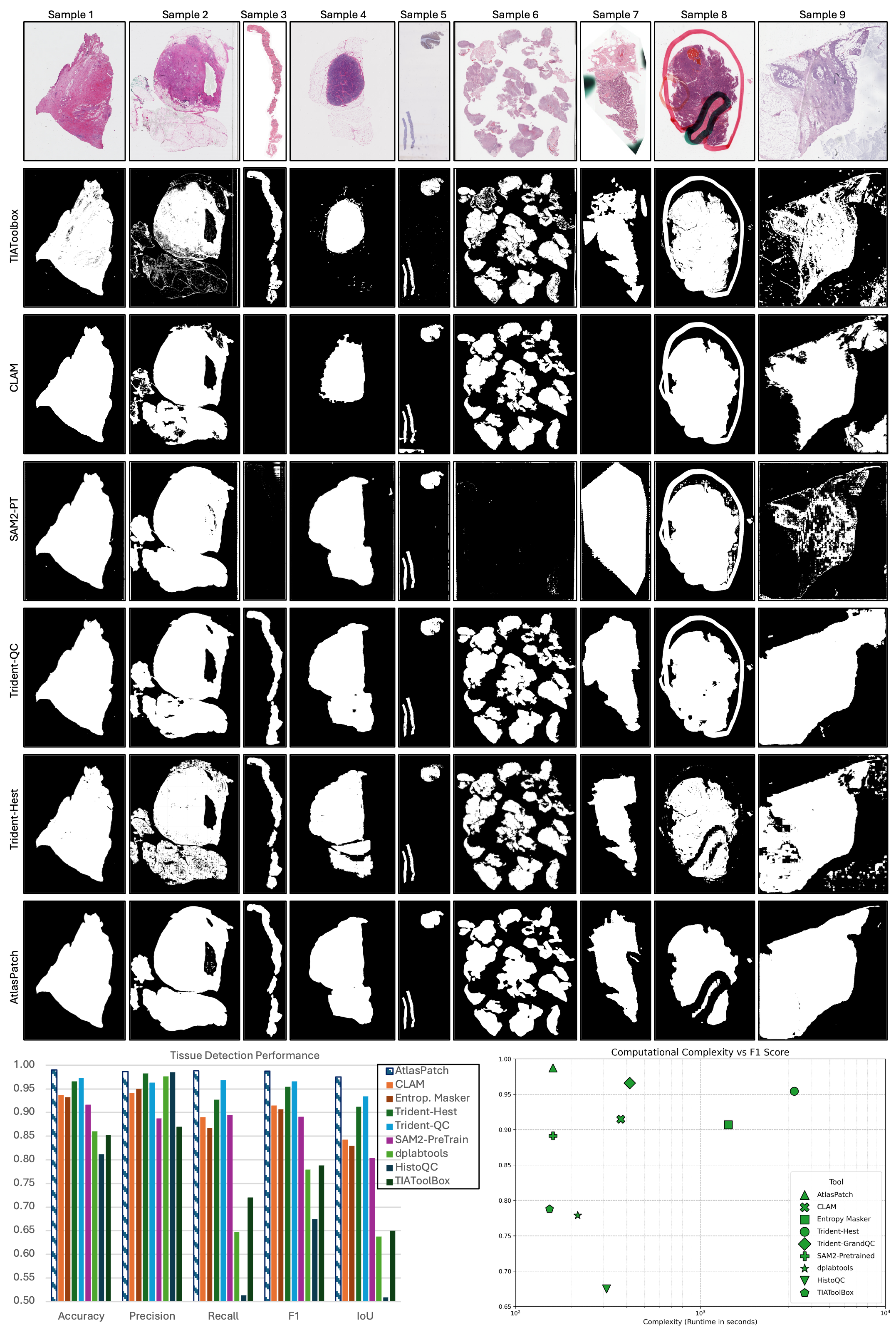
Representative WSI thumbnails are shown from diverse tissue features and artifact conditions, with tissue masks predicted by thresholding methods (TIAToolbox, CLAM) and deep learning methods (pretrained "non-finetuned" SAM2 model, Trident-QC, Trident-Hest and AtlasPatch), highlighting differences in boundary fidelity, artifact suppression and handling of fragmented tissue. Tissue detection performance is also shown on the held-out test set for AtlasPatch and baseline pipelines, highlighting that AtlasPatch matches or exceeds their segmentation quality. The segmentation complexity–performance trade-off, plotting F1-score against segmentation runtime (on a random set of 100 WSIs), shows AtlasPatch achieves high performance with substantially lower wall-clock time than tile-wise detectors and heuristic pipelines, underscoring its suitability for large-scale WSI preprocessing.
| Name | Output Dim |
|---|---|
resnet18 |
512 |
resnet34 |
512 |
resnet50 |
2048 |
resnet101 |
2048 |
resnet152 |
2048 |
convnext_tiny |
768 |
convnext_small |
768 |
convnext_base |
1024 |
convnext_large |
1536 |
vit_b_16 |
768 |
vit_b_32 |
768 |
vit_l_16 |
1024 |
vit_l_32 |
1024 |
vit_h_14 |
1280 |
dinov2_small (DINOv2: Learning Robust Visual Features without Supervision) |
384 |
dinov2_base (DINOv2: Learning Robust Visual Features without Supervision) |
768 |
dinov2_large (DINOv2: Learning Robust Visual Features without Supervision) |
1024 |
dinov2_giant (DINOv2: Learning Robust Visual Features without Supervision) |
1536 |
dinov3_vits16 (DINOv3) |
384 |
dinov3_vits16_plus (DINOv3) |
384 |
dinov3_vitb16 (DINOv3) |
768 |
dinov3_vitl16 (DINOv3) |
1024 |
dinov3_vitl16_sat (DINOv3) |
1024 |
dinov3_vith16_plus (DINOv3) |
1280 |
dinov3_vit7b16 (DINOv3) |
4096 |
dinov3_vit7b16_sat (DINOv3) |
4096 |
Note: Some encoders (e.g.,
uni_v1, etc.) require access approval from Hugging Face. To use these models:
- Request access on the respective Hugging Face model page
- Once approved, set your Hugging Face token as an environment variable:
export HF_TOKEN=your_huggingface_token- Then you can use the encoder in your commands
| Name | Output Dim |
|---|---|
clip_rn50 (Learning Transferable Visual Models From Natural Language Supervision) |
1024 |
clip_rn101 (Learning Transferable Visual Models From Natural Language Supervision) |
512 |
clip_rn50x4 (Learning Transferable Visual Models From Natural Language Supervision) |
640 |
clip_rn50x16 (Learning Transferable Visual Models From Natural Language Supervision) |
768 |
clip_rn50x64 (Learning Transferable Visual Models From Natural Language Supervision) |
1024 |
clip_vit_b_32 (Learning Transferable Visual Models From Natural Language Supervision) |
512 |
clip_vit_b_16 (Learning Transferable Visual Models From Natural Language Supervision) |
512 |
clip_vit_l_14 (Learning Transferable Visual Models From Natural Language Supervision) |
768 |
clip_vit_l_14_336 (Learning Transferable Visual Models From Natural Language Supervision) |
768 |
Add a custom encoder without touching AtlasPatch by writing a small plugin and pointing the CLI at it with --feature-plugin /path/to/plugin.py. The plugin must expose a register_feature_extractors(registry, device, dtype, num_workers) function; inside that hook call register_custom_encoder with a loader that knows how to load the model and run a forward pass.
import torch
from torchvision import transforms
from atlas_patch.models.patch.custom import CustomEncoderComponents, register_custom_encoder
def build_my_encoder(device: torch.device, dtype: torch.dtype) -> CustomEncoderComponents:
"""
Build the components used by AtlasPatch to embed patches with a custom model.
Returns:
CustomEncoderComponents describing the model, preprocess transform, and forward pass.
"""
model = ... # your torch.nn.Module
model = model.to(device=device, dtype=dtype).eval()
preprocess = transforms.Compose([transforms.Resize(224), transforms.ToTensor()])
def forward(batch: torch.Tensor) -> torch.Tensor:
return model(batch) # must return [batch, embedding_dim]
return CustomEncoderComponents(model=model, preprocess=preprocess, forward_fn=forward)
def register_feature_extractors(registry, device, dtype, num_workers):
register_custom_encoder(
registry=registry,
name="my_encoder",
embedding_dim=512,
loader=build_my_encoder,
device=device,
dtype=dtype,
num_workers=num_workers,
)Run AtlasPatch with --feature-plugin /path/to/plugin.py --feature-extractors my_encoder to benchmark your encoder alongside the built-ins. Multiple plugins and extractors can be added at once. Your custom embeddings will be written under features/my_encoder, row-aligned with coords, next to the built-in extractors.
| Encoder | Embedding dim | Required patch encoder | Patch size | Model | Paper | Install |
|---|---|---|---|---|---|---|
titan |
768 | conch_v15 |
512 | MahmoodLab/TITAN | A multimodal whole-slide foundation model for pathology | atlas-patch[titan] or atlas-patch[slide-encoders] |
prism |
1280 | virchow_v1 |
224 | paige-ai/Prism | PRISM: A Multi-Modal Generative Foundation Model for Slide-Level Histopathology | atlas-patch[prism] or atlas-patch[slide-encoders] |
moozy |
768 | lunit_vit_small_patch8_dino |
224 | AtlasAnalyticsLab/MOOZY | MOOZY: A Patient-First Foundation Model for Computational Pathology | atlas-patch[moozy] or atlas-patch[slide-encoders] |
| Encoder | Embedding dim | Required patch encoder | Patch size | Model | Paper | Install |
|---|---|---|---|---|---|---|
moozy |
768 | lunit_vit_small_patch8_dino |
224 | AtlasAnalyticsLab/MOOZY | MOOZY: A Patient-First Foundation Model for Computational Pathology | atlas-patch[moozy] or atlas-patch[patient-encoders] |
Everything AtlasPatch writes lives under the directory you pass to --output.
Each processed slide gets one H5 file:
<output>/patches/<stem>.h5
That file may contain:
coordsfeatures/<patch_encoder>slide_features/<slide_encoder>
Rows in features/<patch_encoder> are aligned with coords.
Patient embeddings are written separately:
<output>/patient_features/<encoder>/<case_id>.h5
Each patient H5 file stores the case embedding in features.
- patch PNGs:
<output>/images/<stem>/ - overlays and masks:
<output>/visualization/
Per-slide H5 files keep patch coordinates, patch features, and slide embeddings together in one place.
- dataset:
coords - shape:
(N, 5) - columns:
(x, y, read_w, read_h, level) xandyare level-0 pixel coordinates.read_w,read_h, andleveldescribe how the patch was read from the WSI.- the level-0 footprint of each patch is stored as the
patch_size_level0file attribute
Example:
import h5py
import numpy as np
import openslide
from PIL import Image
h5_path = "output/patches/sample.h5"
wsi_path = "/path/to/slide.svs"
with h5py.File(h5_path, "r") as f:
coords = f["coords"][...] # (N, 5) int32: [x, y, read_w, read_h, level]
patch_size = int(f.attrs["patch_size"])
with openslide.OpenSlide(wsi_path) as wsi:
for x, y, read_w, read_h, level in coords:
img = wsi.read_region(
(int(x), int(y)),
int(level),
(int(read_w), int(read_h)),
).convert("RGB")
if img.size != (patch_size, patch_size):
img = img.resize((patch_size, patch_size), resample=Image.BILINEAR)
patch = np.array(img) # (H, W, 3) uint8- group:
features/ - dataset:
features/<patch_encoder> - shape:
(N, D)
Rows in every feature matrix are aligned with coords.
import h5py
with h5py.File("output/patches/sample.h5", "r") as f:
feature_names = list(f["features"].keys())
resnet50_features = f["features/resnet50"][...]- group:
slide_features/ - dataset:
slide_features/<slide_encoder> - shape:
(D,)
import h5py
with h5py.File("output/patches/sample.h5", "r") as f:
titan_embedding = f["slide_features/titan"][...]Patient embeddings are stored in separate H5 files under patient_features/<encoder>/.
import h5py
with h5py.File("output/patient_features/moozy/case-001.h5", "r") as f:
case_embedding = f["features"][...]We prepared ready-to-run SLURM templates under jobs/:
- Patch extraction (SAM2 + H5/PNG):
jobs/atlaspatch_patch.slurm.sh. Edits to make:- Set
WSI_ROOT,OUTPUT_ROOT,PATCH_SIZE,TARGET_MAG,SEG_BATCH. - Ensure
--cpus-per-taskmatches the CPU you want; the script passes--patch-workers ${SLURM_CPUS_PER_TASK}and caps--max-open-slidesat 200. --fast-modeis on by default; append--no-fast-modeto enable content filtering.- Submit with
sbatch jobs/atlaspatch_patch.slurm.sh.
- Set
- Feature embedding (adds features into existing H5 files):
jobs/atlaspatch_features.slurm.sh. Edits to make:- Set
WSI_ROOT,OUTPUT_ROOT,PATCH_SIZE, andTARGET_MAG. - Configure
FEATURES(comma/space list, multiple extractors are supported),FEATURE_DEVICE,FEATURE_BATCH,FEATURE_WORKERS, andFEATURE_PRECISION. - This script is intended for feature extraction; use the patch script when you need segmentation + coordinates, and run the feature script to embed one or more models into those H5 files.
- Submit with
sbatch jobs/atlaspatch_features.slurm.sh.
- Set
- Running multiple jobs: you can submit several jobs in a loop (for example,
for i in {1..50}; do sbatch jobs/atlaspatch_features.slurm.sh; done). AtlasPatch uses per-slide lock files to avoid overlapping work on the same slide.
I'm facing an out of memory (OOM) error
This usually happens when too many WSI files are open simultaneously. Try reducing the --max-open-slides parameter:
atlaspatch process /path/to/slides --output ./output --max-open-slides 50The default is 200. Lower this value if you're processing many large slides or have limited system memory.
I'm getting a CUDA out of memory error
Try one or more of the following:
-
Reduce feature extraction batch size:
--feature-batch-size 16 # Default is 32 -
Reduce segmentation batch size:
--seg-batch-size 1 # Default is 1 -
Use lower precision:
--feature-precision float16 # or bfloat16 -
Use a smaller patch size:
--patch-size 224 # Instead of 256
OpenSlide library not found
AtlasPatch requires the OpenSlide system library. Install it based on your system:
- Conda:
conda install -c conda-forge openslide - Ubuntu/Debian:
sudo apt-get install openslide-tools - macOS:
brew install openslide
See OpenSlide Prerequisites for more details.
Access denied for gated models (UNI, Virchow, etc.)
Some encoders require Hugging Face access approval:
- Request access on the model's Hugging Face page (e.g., UNI)
- Once approved, set your token:
export HF_TOKEN=your_huggingface_token - Run AtlasPatch again
Missing microns-per-pixel (MPP) metadata
Some slides lack MPP metadata. You can provide it via a CSV file:
atlaspatch process /path/to/slides --output ./output --mpp-csv /path/to/mpp.csvThe CSV should have columns wsi (filename) and mpp (microns per pixel value).
Processing is slow
Try these optimizations:
-
Enable fast mode (skips content filtering, enabled by default):
--fast-mode
-
Increase parallel workers:
--patch-workers 16 # Match your CPU cores --feature-num-workers 8 -
Increase batch sizes (if GPU memory allows):
--feature-batch-size 64 --seg-batch-size 4
-
Use multiple GPUs by running separate jobs on different GPU devices.
My file format is not supported
AtlasPatch supports most common formats via OpenSlide and Pillow:
- WSIs:
.svs,.tif,.tiff,.ndpi,.vms,.vmu,.scn,.mrxs,.bif,.dcm - Images:
.png,.jpg,.jpeg,.bmp,.webp,.gif
If your format isn't supported, consider converting it to a supported format or open an issue.
How do I skip already processed slides?
process and segment-and-get-coords already skip existing per-slide H5 outputs by default. Use --force when you want to overwrite them:
atlaspatch process /path/to/slides --output ./output --forceCan I run multiple slide encoders in one command?
Yes, but only when they agree on the required patch geometry. encode-slide runs one patch pipeline and then appends the requested slide embeddings into the same per-slide H5 file, so all requested slide encoders in that run must agree on the patch size they need.
For example, titan and prism should be run separately because they require different patch sizes.
What does encode-slide or encode-patient reuse?
Both commands reuse existing per-slide H5 files by default. If the required patch features for the requested encoder are already present, AtlasPatch uses them directly. If the H5 file exists but the required patch feature dataset is missing, AtlasPatch runs the missing patch feature extraction step and then continues with slide or patient encoding.
Use --force if you want to rebuild instead of reuse.
What should the encode-patient CSV file look like?
The CSV file must contain:
case_idslide_path
It may also contain:
mpp
Each row links one slide to one patient. AtlasPatch groups rows by case_id, runs or reuses the per-slide H5 pipeline for each referenced slide, and then writes one patient embedding per patient.
Does encode-patient use slide embeddings?
No. In v1.1.0, patient encoding uses the patch features stored in each slide H5 file. It does not read slide_features/<encoder>.
Where are slide and patient embeddings written?
Slide embeddings are written into the per-slide H5 file under:
slide_features/<slide_encoder>
Patient embeddings are written to separate files under:
patient_features/<encoder>/<case_id>.h5
Have a question not covered here? Feel free to open an issue and ask!
- Report problems via the bug report template so we can reproduce and fix them quickly.
- Suggest enhancements through the feature request template with your use case and proposal.
- When opening a PR, fill out the pull request template and run the listed checks (lint, format, type-check, tests).
If you use AtlasPatch in your research, please cite our paper:
@article{atlaspatch2026,
title = {AtlasPatch: Efficient Tissue Detection and High-throughput Patch Extraction for Computational Pathology at Scale},
author = {Alagha, Ahmed and Leclerc, Christopher and Kotp, Yousef and Metwally, Omar and Moras, Calvin and Rentopoulos, Peter and Rostami, Ghodsiyeh and Nguyen, Bich Ngoc and Baig, Jumanah and Khellaf, Abdelhakim and Trinh, Vincent Quoc-Huy and Mizouni, Rabeb and Otrok, Hadi and Bentahar, Jamal and Hosseini, Mahdi S.},
journal = {arXiv preprint arXiv:2602.03998},
year = {2026}
}AtlasPatch is released under CC BY-NC-SA 4.0.