我做了什么
开发了 qwen-subtitle —— 给视频做字幕智能纠错 + 多语言出海配音的工具,全程由百炼 CLI 驱动,已开源(MIT):https://github.com/oil-oil/qwen_subtitle
录屏 / 教程 / 讲解类视频的字幕,无论哪家 ASR,专有名词永远会被听错:Claude 听成 cloud、Codex 听成 class q、html2pptx 听成 html to ppt。靠手工维护术语表去替换既累又补不全。
核心洞察:录屏视频里,正确的词往往就明明白白写在屏幕上。所以让视觉模型 qwen-vl 按时间戳去看那一帧,读屏幕上真实写着的字来纠正——这是纯语音工具永远做不到的。纠错后还能翻译成多语言、用从视频里克隆出的原声配音,做电商 / 跨境带货出海。
使用的工具
- 百炼 CLI(
bl)
- Skill 名称:qwen-subtitle(开源,自带 SKILL.md,Claude Code / Codex 即取即用)
- 用到的百炼模型与命令(5 步全程
bl):
| 步骤 |
能力 |
模型 |
bl 命令 |
| 1 听写 |
语音识别(句+词级毫秒时间戳) |
fun-asr |
bl speech recognize |
| 2 看屏纠错 ★ |
标错 + 看帧定夺 |
qwen3.7-max + qwen3-vl-plus |
bl text chat / bl vision describe |
| 3 顺滑 |
算法断句 + 去水词 |
qwen-plus |
bl text chat |
| 4 翻译 |
字幕 / 配音稿 |
qwen-mt-turbo / qwen-plus |
bl text chat |
| 5 克隆配音 |
声音复刻 + 合成 |
cosyvoice-v2 |
bl file upload / bl speech synthesize |
效果展示
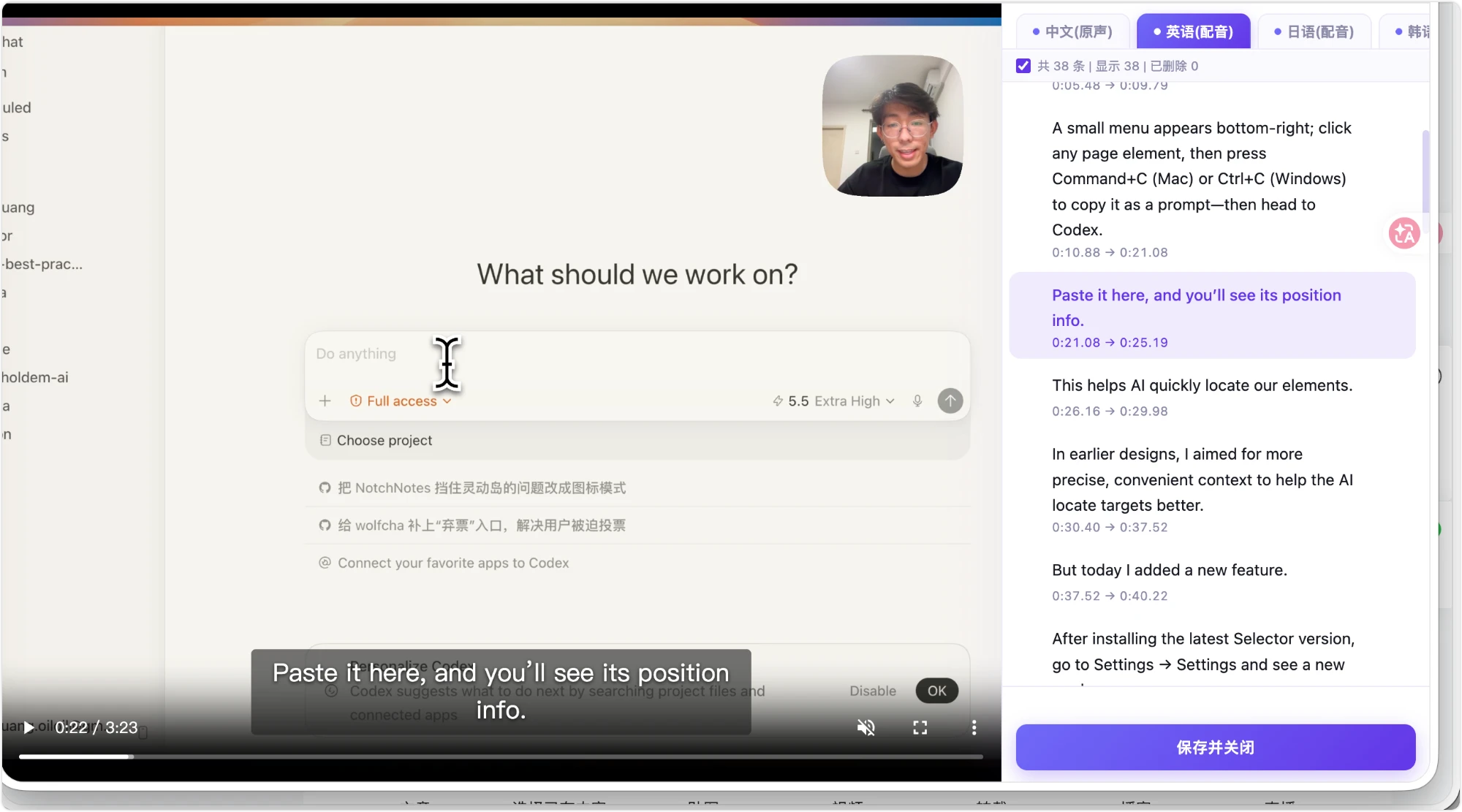
自带本地预览页:右上角语言 tab 一键切换字幕 + 视频音轨(中文原声 / 英·日·韩克隆配音);左边视频烧入对应语言字幕、与帧同步。
纠错实测:7 分钟录屏(78 句),全片 14 处修改 13 处正确,典型如 cloud→Claude、class q→Codex、html to ppt→html2pptx——都是单通道字幕工具修不了的同音术语错,且每处都带画面证据(report.md)。取不到画面证据的句子保留原文 + 标记待人工确认,绝不让模型盲猜(零误改优先)。
多语言出海:英文克隆配音 + 西/葡多语言字幕端到端跑通。配音用 CosyVoice 从视频里克隆的原声(中/英/日/韩),字幕支持 qwen-mt 的 92 语种。有配音的语言,字幕 = 配音同一份文案,一字不差。
一条命令跑完:python3 scripts/subfix.py <video.mp4> → python3 scripts/dub_multi.py <video.mp4> --transcript ... --langs en,ja,es
踩坑记录
bl text chat --output json 不能加 --quiet:加了会返回数组、把 JSON 解析坏掉;不加才是标准 {choices:[{message:{content}}]}。- VL 会幻觉 / 过度纠正(把"超级麦吉"改成"超级码力"、给
ooxml 补成 ooxml.md):加了一组零误改闸门才稳——VL 只认画面上能逐字读到的字(禁图标/logo 推断),最小替换、发音一致,标错阶段别把通顺的中文名当音译错。
- 声音克隆百炼 CLI 暂无对应命令:走原始 DashScope API——
bl file upload --model cosyvoice-v2 拿 oss:// URL → POST .../audio/tts/customization 复刻,必须加请求头 X-DashScope-OssResourceResolve: enable 才能解析 OSS → 拿 voice_id → bl speech synthesize --voice <id>。
- 配音"听着没说完 / 音画对不上":① 按整句念不按字幕碎段;② 字幕与配音用同一份译文;③
atempo 只压缩不拉慢(上限 1.5)。
我做了什么
开发了 qwen-subtitle —— 给视频做字幕智能纠错 + 多语言出海配音的工具,全程由百炼 CLI 驱动,已开源(MIT):https://github.com/oil-oil/qwen_subtitle
录屏 / 教程 / 讲解类视频的字幕,无论哪家 ASR,专有名词永远会被听错:
Claude听成cloud、Codex听成class q、html2pptx听成html to ppt。靠手工维护术语表去替换既累又补不全。核心洞察:录屏视频里,正确的词往往就明明白白写在屏幕上。所以让视觉模型 qwen-vl 按时间戳去看那一帧,读屏幕上真实写着的字来纠正——这是纯语音工具永远做不到的。纠错后还能翻译成多语言、用从视频里克隆出的原声配音,做电商 / 跨境带货出海。
使用的工具
bl)bl):bl speech recognizebl text chat/bl vision describebl text chatbl text chatbl file upload/bl speech synthesize效果展示
自带本地预览页:右上角语言 tab 一键切换字幕 + 视频音轨(中文原声 / 英·日·韩克隆配音);左边视频烧入对应语言字幕、与帧同步。
纠错实测:7 分钟录屏(78 句),全片 14 处修改 13 处正确,典型如
cloud→Claude、class q→Codex、html to ppt→html2pptx——都是单通道字幕工具修不了的同音术语错,且每处都带画面证据(report.md)。取不到画面证据的句子保留原文 + 标记待人工确认,绝不让模型盲猜(零误改优先)。多语言出海:英文克隆配音 + 西/葡多语言字幕端到端跑通。配音用 CosyVoice 从视频里克隆的原声(中/英/日/韩),字幕支持 qwen-mt 的 92 语种。有配音的语言,字幕 = 配音同一份文案,一字不差。
一条命令跑完:
python3 scripts/subfix.py <video.mp4>→python3 scripts/dub_multi.py <video.mp4> --transcript ... --langs en,ja,es踩坑记录
bl text chat --output json不能加--quiet:加了会返回数组、把 JSON 解析坏掉;不加才是标准{choices:[{message:{content}}]}。ooxml补成ooxml.md):加了一组零误改闸门才稳——VL 只认画面上能逐字读到的字(禁图标/logo 推断),最小替换、发音一致,标错阶段别把通顺的中文名当音译错。bl file upload --model cosyvoice-v2拿oss://URL →POST .../audio/tts/customization复刻,必须加请求头X-DashScope-OssResourceResolve: enable才能解析 OSS → 拿 voice_id →bl speech synthesize --voice <id>。atempo只压缩不拉慢(上限 1.5)。