类UNIX操作系统非常多,比如FreeBSD、Linux、macOS、Solaris等都属于UNIX操作系统的范畴
在类UNIX系统中用来启动MySQL服务器程序的可执行文件有很多,大多在MySQL安装目录的bin目录下,我们一起来看看。
mysqld这个可执行文件就代表着MySQL服务器程序,运行这个可执行文件就可以直接启动一个服务器进程。但这个命令不常用,我们继续往下看更牛逼的启动命令。
mysqld_safe是一个启动脚本,它会间接的调用mysqld,而且还顺便启动了另外一个监控进程,这个监控进程在服务器进程挂了的时候,可以帮助重启它。另外,使用mysqld_safe启动服务器程序时,它会将服务器程序的出错信息和其他诊断信息重定向到某个文件中,产生出错日志,这样可以方便我们找出发生错误的原因。
mysql.server也是一个启动脚本,它会间接的调用mysqld_safe,在调用mysql.server时在后边指定start参数就可以启动服务器程序了,就像这样:
mysql.server start
需要注意的是,这个 *mysql.server* 文件其实是一个链接文件,它的实际文件是 *../support-files/mysql.server*。我使用的macOS操作系统会在bin目录下自动创建一个指向实际文件的链接文件,如果你的操作系统没有帮你自动创建这个链接文件,那就自己创建一个呗~ 别告诉我你不会创建链接文件,上网搜搜呗~
另外,我们还可以使用mysql.server命令来关闭正在运行的服务器程序,只要把start参数换成stop就好了:
mysql.server stop
其实我们一台计算机上也可以运行多个服务器实例,也就是运行多个MySQL服务器进程。mysql_multi可执行文件可以对每一个服务器进程的启动或停止进行监控。这个命令的使用比较复杂,本书主要是为了讲清楚MySQL服务器和客户端运行的过程,不会对启动多个服务器程序进行过多介绍。
Windows里没有像类UNIX系统中那么多的启动脚本,但是也提供了手动启动和以服务的形式启动这两种方式,下面我们详细看。
同样的,在MySQL安装目录下的bin目录下有一个mysqld可执行文件,在命令行里输入mysqld,或者直接双击运行它就算启动了MySQL服务器程序了。
首先看看什么是个Windows 服务?如果无论是谁正在使用这台计算机,我们都需要长时间的运行某个程序,而且需要在计算机启动的时候便启动它,一般我们都会把它注册为一个Windows 服务,操作系统会帮我们管理它。把某个程序注册为Windows服务的方式挺简单,如下:
"完整的可执行文件路径" --install [-manual] [服务名]
其中的-manual可以省略,加上它的话,表示在Windows系统启动的时候不自动启动该服务,否则会自动启动。服务名也可以省略,默认的服务名就是MySQL。比如我的Windows计算机上mysqld的完整路径是:
C:\Program Files\MySQL\MySQL Server 5.7\bin\mysqld
所以如果我们想把它注册为服务的话可以在命令行里这么写:
"C:\Program Files\MySQL\MySQL Server 5.7\bin\mysqld" --install
在把mysqld注册为Windows服务之后,我们就可以通过下面这个命令来启动MySQL服务器程序了:
net start MySQL
当然,如果你喜欢图形界面的话,你可以通过Windows的服务管理器通过用鼠标点点点的方式来启动和停止服务(作为一个程序猿,还是用黑框框吧~)。
关闭这个服务也非常简单,只要把上面的start换成stop就行了,就像这样:
net stop MySQL
-
TCP/IP:
mysql -h127.0.0.1 -uroot -P3307 -p -
windows系统
- 命名管道:需要在启动服务器程序的命令中加上
--enable-named-pipe参数,然后在启动客户端程序的命令中加入--pipe或者--protocol=pipe参数。 - 共享内存:需要在启动服务器程序的命令中加上
--shared-memory参数,在成功启动服务器后,共享内存便成为本地客户端程序的默认连接方式,不过我们也可以在启动客户端程序的命令中加入--protocol=memory参数来显式的指定使用共享内存进行通信。不过需要注意的是,使用共享内存的方式进行通信的服务器进程和客户端进程必须在同一台Windows主机中。
- 命名管道:需要在启动服务器程序的命令中加上
-
类UNIX系统
-
UNIX套接字:如果我们在启动客户端程序的时候指定的主机名为
localhost,或者指定了--protocol=socket的启动参数,那服务器程序和客户端程序之间就可以通过Unix域套接字文件来进行通信了。MySQL服务器程序默认监听的Unix域套接字文件路径为/tmp/mysql.sock,客户端程序也默认连接到这个Unix域套接字文件。如果我们想改变这个默认路径,可以在启动服务器程序时指定socket参数,就像这样:mysqld --socket=/tmp/a.txt这样服务器启动后便会监听
/tmp/a.txt。在服务器改变了默认的UNIX域套接字文件后,如果客户端程序想通过UNIX域套接字文件进行通信的话,也需要显式的指定连接到的UNIX域套接字文件路径,就像这样:mysql -hlocalhost -uroot --socket=/tmp/a.txt -p这样该客户端进程和服务器进程就可以通过路径为
/tmp/a.txt的Unix域套接字文件进行通信了。
-
UNIX套接字高性能是因为数据绕过了网络协议,操作系统的零拷贝(sendfile系统调用)高性能是因为数据拷贝没有经过用户空间,只在内核空间中流转。
你抓住了重点!UNIX 域套接字确实和“零拷贝”有非常紧密的关系,但准确地说,它是通过“绕过网络协议栈”来实现类似零拷贝的高效效果。
简单来说,UNIX 域套接字之所以快,是因为它少干活(不处理网络协议)和少搬运(减少数据在内核和用户空间之间的拷贝)。
我们可以从以下三个层面来理解这种关系:
正如你引用的内容所说,TCP/IP 通信即使是在本机(127.0.0.1),也要走一遍完整的网络流程:
- TCP 流程: 应用层 → Socket → TCP(校验和、排序)→ IP(路由)→ 网络驱动 → 回环接口 → IP → TCP → Socket → 应用层。
- UNIX 域套接字流程: 应用层 → 内核消息队列 → 应用层。
结论: UNIX 域套接字直接把中间那一大堆“打包、拆包、校验”的活全砍掉了,数据在内核里直接“抄近道”。
虽然 UNIX 域套接字很快,但在操作系统底层,还有一个专门的技术叫零拷贝(Zero-Copy),通常指
sendfile系统调用。
- 传统拷贝: 数据从磁盘 → 内核缓冲区 → 用户缓冲区 → 内核 Socket 缓冲区 → 网卡。这里数据被拷贝了多次,CPU 很累。
- 零拷贝(sendfile): 数据从磁盘 → 内核缓冲区 → 内核 Socket 缓冲区 → 网卡。数据完全不进入用户空间,CPU 只需要搬运极少量的描述符信息。
UNIX 域套接字和零拷贝技术经常被放在一起讨论,是因为它们经常配合使用来达到极致的性能:
- UNIX 域套接字是“高速公路”: 它提供了一个不拥堵(无网络协议栈开销)的传输通道。
- 零拷贝是“直达货车”: 当通过 UNIX 域套接字传输大文件时,如果配合
sendfile或mmap技术,数据甚至不需要经过 CPU 的反复拷贝,直接在内核空间完成流转。举个例子: 很多高性能的消息队列(如 ZeroMQ)或数据库,在本地通信时,会优先选择 UNIX 域套接字,并在底层利用 零拷贝 机制。这样既省去了网络协议的“过路费”,又省去了数据搬运的“人工费”,所以速度能达到极致。
你提到的“数据直接在内核里拷贝”,其实正是 UNIX 域套接字避免了网络协议栈的结果。虽然它不等同于严格意义上的“零拷贝”(Zero-Copy),但它通过减少上下文切换和减少数据拷贝次数,达到了和零拷贝一样的高性能目标。

从图中我们可以看出,服务器程序处理来自客户端的查询请求大致需要经过三个部分,分别是连接管理、解析与优化、存储引擎
-
客户端进程可以采用我们上面介绍的
TCP/IP、命名管道或共享内存、Unix域套接字这几种方式之一来与服务器进程建立连接 -
每当有一个客户端进程连接到服务器进程时,服务器进程都会创建一个线程来专门处理与这个客户端的交互,当该客户端退出时会与服务器断开连接,服务器并不会立即把与该客户端交互的线程销毁掉,而是把它缓存起来,在另一个新的客户端再进行连接时,把这个缓存的线程分配给该新客户端。这样就起到了不频繁创建和销毁线程的效果,从而节省开销。
-
在客户端程序发起连接的时候,需要携带主机信息、用户名、密码,服务器程序会对客户端程序提供的这些信息进行认证,如果认证失败,服务器程序会拒绝连接。另外,如果客户端程序和服务器程序不运行在一台计算机上,我们还可以采用使用了
SSL(安全套接字)的网络连接进行通信,来保证数据传输的安全性。 -
当连接建立后,与该客户端关联的服务器线程会一直等待客户端发送过来的请求,
MySQL服务器接收到的请求只是一个文本消息,该文本消息还要经过各种处理
TLS(传输层安全)和 SSL(安全套接层)的关系其实非常简单:TLS 是 SSL 的升级版和正式继任者。
虽然大家习惯口头统称它们为“SSL”,但在现代互联网中,你实际使用的几乎全都是 TLS 协议。
为了让你更清晰地理解,我为你整理了它们的核心区别和关系:
你可以把它们的关系理解为 “Windows 98” (SSL) 和 “Windows 11” (TLS) 的关系。
- SSL (Secure Sockets Layer):由网景公司(Netscape)在 1990 年代开发,是早期的安全协议。
- TLS (Transport Layer Security):由于 SSL 存在严重的安全漏洞,国际互联网工程任务组(IETF)在 SSL 3.0 的基础上进行了标准化和升级,于 1999 年发布了 TLS 1.0。
结论: TLS 就是 SSL 的“正式转正”版本。
既然 TLS 已经取代了 SSL,为什么我们还在说“SSL 证书”?
- 习惯叫法: 就像我们习惯把“移动硬盘”叫成“U盘”一样,因为 SSL 出现得太早,知名度太高,所以行业里一直沿用了“SSL 证书”这个叫法。
- 实际情况: 现在你去购买所谓的“SSL 证书”,实际上配置在服务器上的都是 TLS 协议(通常是 TLS 1.2 或 TLS 1.3)。
维度 SSL (1.0 - 3.0) TLS (1.0 - 1.3) 状态 已淘汰 (存在严重漏洞) 当前标准 (安全且高效) 安全性 较低,易受攻击 (如 POODLE 漏洞) 高,支持更强的加密算法 (如 AES-GCM) 兼容性 现代浏览器已不再支持 兼容所有现代设备和浏览器 性能 握手慢,效率低 握手快 (尤其是 TLS 1.3),延迟低 开发者 网景公司 (Netscape) 互联网工程任务组 (IETF) 无论是叫 SSL 还是 TLS,它们的核心作用都是在你的浏览器和服务器之间建立一条加密通道(也就是 HTTPS)。这个过程通常被称为“握手”:
- 打招呼 (ClientHello): 浏览器告诉服务器:“我支持这些加密算法,这是我的随机数。”
- 回应 (ServerHello): 服务器选一个最强的算法,把自己的“身份证”(数字证书)发给浏览器。
- 验证 (Verification): 浏览器检查证书是不是正规机构发的,域名对不对。
- 交换钥匙 (Key Exchange): 双方通过复杂的数学计算(非对称加密),协商出一个只有它们俩知道的“会话密钥”。
- 加密通信: 之后的聊天内容,都用这个“会话密钥”进行加密传输(对称加密),黑客截获了也看不懂。
如果你是在配置服务器或购买证书:
- 忽略“SSL”这个名字: 只要知道它是用来开启 HTTPS 的就行。
- 关注版本: 务必在服务器上禁用 SSL 2.0/3.0 和 TLS 1.0/1.1,只启用 TLS 1.2 和 TLS 1.3。这是目前最安全、速度最快的组合。
简单总结:SSL 是旧称,TLS 是真相。
-
MySQL服务器并没有人聪明,如果两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。另外,如果查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表,如 mysql 、information_schema、 performance_schema 数据库中的表,那这个请求就不会被缓存。 -
MySQL的缓存系统会监测涉及到的每张表,只要该表的结构或者数据被修改,如对该表使用了
INSERT、UPDATE、DELETE、TRUNCATE TABLE、ALTER TABLE、DROP TABLE或DROP DATABASE语句,那使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除! -
虽然查询缓存有时可以提升系统性能,但也不得不因维护这块缓存而造成一些开销,比如每次都要去查询缓存中检索,查询请求处理完需要更新查询缓存,维护该查询缓存对应的内存区域。从MySQL 5.7.20开始,不推荐使用查询缓存,并在MySQL 8.0中删除。
- 如果查询缓存没有命中,接下来就需要进入正式的查询阶段了。因为客户端程序发送过来的请求只是一段文本而已,所以
MySQL服务器程序首先要对这段文本做分析,判断请求的语法是否正确,然后从文本中将要查询的表、各种查询条件都提取出来放到MySQL服务器内部使用的一些数据结构上来。 - 这个从指定的文本中提取出我们需要的信息本质上算是一个编译过程,涉及词法解析、语法分析、语义分析等阶段
- 语法解析之后,服务器程序获得到了需要的信息,比如要查询的列是哪些,表是哪个,搜索条件是什么等等,但光有这些是不够的,因为我们写的
MySQL语句执行起来效率可能并不是很高,MySQL的优化程序会对我们的语句做一些优化,如外连接转换为内连接、表达式简化、子查询转为连接等等的一堆东西。 - 优化的结果就是生成一个执行计划,这个执行计划表明了应该使用哪些索引进行查询,表之间的连接顺序是什么样的。我们可以使用
EXPLAIN语句来查看某个语句的执行计划,关于查询优化这部分的详细内容我们后边会仔细介绍,现在你只需要知道在MySQL服务器程序处理请求的过程中有这么一个步骤就好了。
-
截止到服务器程序完成了查询优化为止,还没有真正的去访问真实的数据表,
MySQL服务器把数据的存储和提取操作都封装到了一个叫存储引擎(表处理器)的模块里。我们知道表是由一行一行的记录组成的,但这只是一个逻辑上的概念,物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎负责的事情。为了实现不同的功能,MySQL提供了各式各样的存储引擎,不同存储引擎管理的表具体的存储结构可能不同,采用的存取算法也可能不同。 -
为了管理方便,人们把
连接管理、查询缓存、语法解析、查询优化这些并不涉及真实数据存储的功能划分为MySQL server的功能,把真实存取数据的功能划分为存储引擎的功能。各种不同的存储引擎向上面的MySQL server层提供统一的调用接口(也就是存储引擎API),包含了几十个底层函数,像"读取索引第一条内容"、"读取索引下一条内容"、"插入记录"等等。
MySQL支持非常多种存储引擎,我这先列举一些:
| 存储引擎 | 描述 |
|---|---|
ARCHIVE |
用于数据存档(行被插入后不能再修改) |
BLACKHOLE |
丢弃写操作,读操作会返回空内容 |
CSV |
在存储数据时,以逗号分隔各个数据项 |
FEDERATED |
用来访问远程表 |
InnoDB |
具备外键支持功能的事务存储引擎 |
MEMORY |
置于内存的表 |
MERGE |
用来管理多个MyISAM表构成的表集合 |
MyISAM |
主要的非事务处理存储引擎 |
NDB |
MySQL集群专用存储引擎 |
| Feature | MyISAM | Memory | InnoDB | Archive | NDB |
|---|---|---|---|---|---|
| B-tree indexes | yes | yes | yes | no | no |
| Backup/point-in-time recovery | yes | yes | yes | yes | yes |
| Cluster database support | no | no | no | no | yes |
| Clustered indexes | no | no | yes | no | no |
| Compressed data | yes | no | yes | yes | no |
| Data caches | no | N/A | yes | no | yes |
| Encrypted data | yes | yes | yes | yes | yes |
| Foreign key support | no | no | yes | no | yes |
| Full-text search indexes | yes | no | yes | no | no |
| Geospatial data type support | yes | no | yes | yes | yes |
| Geospatial indexing support | yes | no | yes | no | no |
| Hash indexes | no | yes | no | no | yes |
| Index caches | yes | N/A | yes | no | yes |
| Locking granularity | Table | Table | Row | Row | Row |
| MVCC | no | no | yes | no | no |
| Query cache support | yes | yes | yes | yes | yes |
| Replication support | yes | Limited | yes | yes | yes |
| Storage limits | 256TB | RAM | 64TB | None | 384EB |
| T-tree indexes | no | no | no | no | yes |
| Transactions | no | no | yes | no | yes |
| Update statistics for data dictionary | yes | yes | yes | yes | yes |
.ini和.cnf本质上都是纯文本格式的配置文件,用于存储软件或系统的初始化参数。虽然它们在技术原理上非常相似(都是“键=值”的结构),但在使用习惯、操作系统偏好以及特定领域的含义上有一些明显的区别。
为了让你一目了然,我为你整理了一个对比表:
维度 .ini 文件 .cnf 文件 全称 Initialization File (初始化文件) Configuration File (配置文件) 主要阵地 Windows 系统 Linux / Unix 系统 典型代表 win.ini,system.ini, 软件配置my.cnf(MySQL),php.ini(虽是ini但常用于Linux)结构特点 严格的 [Section]+Key=Value结构类似,但有时更灵活,甚至包含代码逻辑 其他含义 几乎专指配置文件 在数学/逻辑学中指“合取范式”
.ini(Windows 的“老传统”): 它是微软 Windows 早期(Windows 3.x, 95)用来存储系统设置的核心格式(如System.ini,Win.ini)。虽然后来 Windows 引入了注册表(Registry)来替代它,但.ini因为简单、便携、易于读写,依然被大量软件(包括很多游戏和专业软件)用来保存用户设置。.cnf(Linux/Unix 的“习惯”): 在 Linux 或 Unix 世界里,文件名后缀通常比较随意,.cnf是 "config" 的常见缩写。它更多是一种约定俗成的叫法。比如著名的数据库 MySQL,在 Windows 下它的配置文件叫my.ini,而在 Linux 下则叫my.cnf,其实内容格式几乎是一样的。
.ini通常很纯粹: 它通常严格遵守[节]、键=值、;注释的格式,很少包含复杂的逻辑。很多编程语言(如 Python 的configparser)都有专门的标准库来直接读取它。.cnf可能很复杂: 虽然很多.cnf文件也是简单的键值对,但在 Linux 下,有些.cnf文件(或者类似的.conf)实际上可能是脚本或代码片段。例如 Nginx 或 Apache 的配置文件,里面可能包含if判断、变量引用等逻辑,不仅仅是静态配置。除了配置文件,
.cnf在计算机科学的其他领域还有一个完全不同的含义:合取范式 (Conjunctive Normal Form)。
- 在逻辑学和 SAT 求解器(一种解决数学逻辑问题的软件)中,
.cnf文件用于描述布尔逻辑问题。- 这种文件的内容不是“键=值”,而是由数字组成的逻辑子句(如
1 -2 0),用来表示逻辑公式。如果你打开一个.cnf文件发现里面全是数字和奇怪的符号,那它大概率就是这种逻辑文件,而不是软件配置。
- 如果你看到
.ini:它几乎肯定是一个简单的配置文件,大概率出现在 Windows 环境,或者是一个跨平台软件的用户设置。- 如果你看到
.cnf:它大概率是 Linux 服务器上的软件配置(如数据库配置),或者是某种特定领域的逻辑定义文件。一句话概括: 它们是“异父异母的亲兄弟”,功能一样,只是出生的家庭(操作系统)不同,名字习惯不同而已。
这是一个非常敏锐的问题!你之所以会有这个疑问,是因为
echo在 Linux(Bash)和 Windows(CMD/PowerShell)中表现得太像了,以至于让人觉得它们是一回事。简单直接的回答是:Windows 之所以能使用
echo,是因为 Windows 的命令行解释器(CMD)也内置了这个命令,但这完全是微软“独立开发”的,和 Linux 的echo没有血缘关系。这就像两个人都叫“张三”,一个住在北京(Windows),一个住在纽约(Linux),虽然名字一样,功能也差不多(都会打招呼),但他们是两个完全不同的个体。
以下是详细的对比和解释:
为了“生存”和“竞争”。 在计算机早期(DOS 时代),微软需要让操作系统具备基本的脚本自动化能力。Linux/Unix 的 Shell 脚本当时已经非常流行且强大,为了让用户和开发者能顺利上手 DOS/Windows,微软在 CMD(命令提示符)中复刻了许多 Unix 的核心功能。
- 功能需求: 批处理脚本(.bat)需要向用户显示信息(比如“安装成功”、“正在复制文件”),所以必须有一个“回声/打印”命令。
- 命名习惯:
echo这个词简单直观,微软就直接沿用了这个名字。虽然它们都能打印文字,但在语法细节和特殊功能上,它们其实是“方言”不通的。
特性 Windows (CMD) 的 echoLinux (Bash) 的 echo核心身份 CMD 的内建命令 Bash 的内建命令 (也有外部程序 /bin/echo)变量引用 用百分号: echo %name%用美元符: echo $name引号处理 通常不需要引号: echo Hello通常建议加引号: echo "Hello"换行符 不支持 -e参数,无法识别\n支持 -e参数:echo -e "A\nB"特殊技能 控制回显: echo off(隐藏命令本身)无此功能 (Bash 不靠 echo 控制回显) 空行输出 必须加点: echo.直接回车或 echo ""你在网上看到的很多教程,可能会把两者混着用,这会导致报错。
- 场景: 你在 Windows 的 CMD 里输入了 Linux 的命令
echo -e "Hello\nWorld"。- 结果: Windows 会一脸懵逼地打印出:
-e "Hello\nWorld"。因为它不认识-e这个参数,它以为你想打印的文本就是以“-e”开头的。这是 Windows 批处理(.bat)特有的需求。
- Linux: 脚本执行时,默认只显示结果,不显示命令本身。
- Windows: 脚本执行时,默认会把每一行命令先打印一遍,再执行。这会让屏幕看起来很乱。
- 解决: Windows 的
echo被赋予了**“控制开关”**的职责。@echo off的意思就是:“把回显功能关掉,别把命令打印出来了,只显示结果”。这是 Linux 的echo完全没有的功能。Windows 可以使用
echo,是因为微软为了兼容用户习惯和脚本需求,**“山寨”**了这个命令。
- 如果你写 Linux 脚本,请用
echo $var和echo -e。- 如果你写 Windows 批处理,请用
echo %var%和@echo off。虽然它们长得像,但千万别把它们当成同一个东西混用哦!
CMake 在 C/C++ 生态中的地位,最接近 Java 中的 Maven/Gradle 以及 前端中的 Webpack/Vite。
为了让你更直观地理解,我们可以把它们放在一个表格中进行对比。
维度 C/C++ (CMake) Java (Maven/Gradle) 前端 (Webpack/Vite) 核心角色 项目管家:负责管理代码怎么编译、链接成二进制文件。 全能保姆:不仅负责编译,还负责下载依赖包、运行测试、打包发布。 打包搬运工:负责把分散的 JS/CSS/图片整合、压缩,让浏览器能读懂。 配置文件 CMakeLists.txtpom.xml(Maven)build.gradle(Gradle)webpack.config.jsvite.config.js依赖管理 较弱:主要靠 find_package找系统里装好的库,或者依赖外部工具(如 Conan, vcpkg)。极强:内置中央仓库,自动下载 jar 包和传递依赖。 强:依赖 npm/yarn 包管理器,自动从 npm 仓库下载 node_modules。主要功能 生成 Makefile 或 IDE 项目文件,控制编译器标志,处理跨平台差异。 编译 Java 字节码,管理生命周期(编译-测试-打包),发布到仓库。 代码转译(如 TS 转 JS),资源压缩,热更新(HMR),代码分割。 构建产物 原生二进制: .exe,.dll,.so,.a。字节码: .jar,.war(运行在 JVM 上)。静态资源: .js,.css,.html(运行在浏览器上)。跨平台性 极高:一套配置生成 VS, Xcode, Makefile 等。 极高:Write Once, Run Anywhere (JVM 屏蔽系统差异)。 高:主要在浏览器运行,受 Node.js 环境版本影响。
虽然角色类似,但 CMake 和 Java/前端的工具在**“依赖管理”**上有一个巨大的区别,这也是 C++ 开发者最羡慕 Java/前端开发者的地方:
- Java (Maven/Gradle) 是“自带仓库”的: 你在
pom.xml里写一行代码,Maven 就会自动去中央仓库把对应的 jar 包下载下来给你用,非常方便。- 前端 (npm/yarn) 是“极致模块化”的: 你输入
npm install react,代码就下来了。前端工具链(Webpack/Vite)非常擅长处理成千上万个小文件的打包和转换。- CMake 是“自力更生”的: CMake 本身不具备自动下载依赖的功能。如果你想用第三方库,你通常需要:
- 自己去官网下载源码。
- 自己编译安装到系统目录。
- 然后告诉 CMake 库在哪里(通过
find_package)。- 注:虽然现在有 Conan 或 vcpkg 这样的包管理器来配合 CMake,但它们不像 Maven 或 npm 那样是官方标配且无缝集成的。
- 如果你熟悉 Maven:CMake 就像是 Maven 的“编译插件”部分,但少了自动下载依赖的功能,多了很多底层编译器配置的麻烦。
- 如果你熟悉 Webpack:CMake 就像是 Webpack 的“Entry 配置”,告诉它入口文件在哪,输出到哪里,但 CMake 处理的是机器码,Webpack 处理的是脚本。
这四个文件都是程序代码的“容器”,但它们在程序运行中扮演的角色截然不同。简单来说,
.exe是最终能跑起来的程序,而.dll、.so、.a则是供程序调用的“零件库”。下面这张表格可以帮你快速理清它们的关系:
文件后缀 所属平台 文件类型 核心特点 .exeWindows 可执行文件 程序的“本体”,可以直接运行。 .dllWindows 动态链接库 程序的“外挂工具箱”,运行时才被调用,可被多个程序共享。 .aLinux 静态库 程序的“内嵌工具箱”,编译时就被完整地复制进程序里。 .soLinux 动态链接库 Linux 版的 .dll,功能和使用方式基本一致。
这两者的核心区别在于“链接”的时机,也就是工具箱被“安装”到程序里的时间不同。
- 静态库 (
.a)
- 编译时链接:当你编译程序时,链接器会把
.a库里所有用到的代码,完整地复制一份到你的最终程序里。- 优点:生成的程序是独立的,不依赖外部的库文件,方便分发。
- 缺点:程序体积会变大;如果库更新了,你的程序必须重新编译才能用上。
- 动态库 (
.dll,.so)
- 运行时链接:编译时,程序只记录“我需要用哪个库”。直到你真正运行程序时,操作系统才会去找到并加载这个库。
- 优点:程序体积小;多个程序可以共享内存中的同一个库,节省资源;库更新了,程序无需重新编译。
- 缺点:程序运行依赖这些外部库文件,如果丢失或版本不对,程序就会报错(比如经典的 “找不到 xxx.dll”)。
一个形象的比喻:
- 静态链接 就像你把菜谱(库)里的某几页撕下来,贴在自己的笔记本(程序)上。你的笔记变厚了,但可以随时查阅,不依赖原书。
- 动态链接 就像你的笔记本上只写了“详见《中华菜谱》第58页”。笔记本很薄,但你做菜时必须手边有那本《中华菜谱》才行。
当然不是。 这是一个非常普遍的误解。
.exe和.dll只是微软定义的文件格式标准(称为 PE格式)。你可以把它理解为一个“包装盒”,任何能编译成机器码的编程语言,都可以把自己的程序打包成这种格式,从而在 Windows 上运行。除了 C++,还有无数语言可以生成
.exe文件:
- C# / .NET:非常流行的 Windows 开发语言,生成的也是
.exe。- Delphi / Pascal:老牌的 Windows 开发工具。
- Go / Rust:现代系统级语言,它们的程序在 Windows 上也是
.exe。- Python / Java:虽然它们本身是解释型或运行在虚拟机上的,但可以通过打包工具(如 PyInstaller, jpackage)将解释器和所有依赖“打包”成一个独立的
.exe文件,方便在没有安装 Python/Java 环境的电脑上运行。总结一下: C++ 确实是开发高性能 Windows 程序和系统组件(很多
.dll就是 C++ 写的)的重要语言,但它绝不是唯一的选择。.exe只是一个通用的“外壳”,里面的“灵魂”(编程语言)可以是多种多样的。
首先,你需要停止MySQL服务。打开终端并执行以下命令:
sudo /usr/local/mysql/support-files/mysql.server stop
或者,如果你使用的是Homebrew安装的MySQL,可以使用:
brew services stop mysql
接下来,以安全模式启动MySQL服务,这样可以不需要密码即可访问:
sudo /usr/local/mysql/bin/mysqld_safe --skip-grant-tables &
或者,对于Homebrew安装的MySQL:
mysqld_safe --skip-grant-tables &
由于我们跳过了权限表,现在可以无需密码登录MySQL:
mysql -u root
在MySQL提示符下,选择mysql数据库:
USE mysql;
现在可以更新root用户的密码了。执行以下命令来设置新密码(将your_new_password替换为你想要设置的新密码):
UPDATE user SET authentication_string=PASSWORD('your_new_password') WHERE User='root';
或者,对于MySQL 5.7.6及以上版本,使用:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'your_new_password';
刷新权限表,然后退出MySQL:
FLUSH PRIVILEGES;EXIT;
现在,停止之前以跳过权限表启动的MySQL服务,并正常重启它:
sudo /usr/local/mysql/support-files/mysql.server stopsudo /usr/local/mysql/support-files/mysql.server start
或者,对于Homebrew安装的MySQL:
brew services stop mysqlbrew services start mysql
最后,使用新设置的密码登录MySQL:
mysql -u root -p
然后输入你的新密码。
以上步骤应该可以帮助你重新设置MySQL的root密码。如果你使用的是MariaDB而不是MySQL,步骤大致相同,只是路径和命令可能会稍有不同。例如,MariaDB通常位于/usr/local/mariadb目录下。
DQL语言:SELECT
DML语言:INSERT/UPDATE/DELETE/SELECT
DDL语言:CREATE\ALTER\DROP\RENAME\TRUNCATE
TCL语言/DCL语言:COMMIT/ROLLBACK/SAVEPOINT/GRANT
MYSQL不支持SQL92语法,Oracle支持.
SQL99语法支持性较好!即
LEFT JOIN ... ON/RIGHT JOIN...ON下面这句外连接,MYSQL执行错误,不支持该语法。
SELECT employee_id,department_name FROM employees e,departments d WHERE e.`department_id`=d.`department_id`;SQL编写建议:
- 关键字和函数名称全部大写
- 数据库名、表名、表别名、字段名、字段别名等全部小写
select @@sql_mode;-- 查询全局sql_mode
字符串存在隐式转换,如果转换成数值不成功,则看做0
select 1=2,1!=2,1='1',1='a',0='a' from dual; -- 0 1 1 0 1只要有null参与预算,结果就为null
select 1=null,null=null from dual; -- null null
<=>安全等于,可以对null进行判断
select 1<=>2,1<=>'1',1<=>'a',0<=>'a' from dual;-- 0 1 0 1
select 1<=>null,null<=>null from dual;-- 0 1mysql> SELECT LEAST(2, 5, 12, 3);
Result: 2
mysql> SELECT LEAST('2', '5', '12', '3');
Result: '12'
mysql> SELECT LEAST('techonthenet.com', 'checkyourmath.com', 'bigactivities.com');
Result: 'bigactivities.com'
mysql> SELECT LEAST('techonthenet.com', 'checkyourmath.com', null);
Result: NULL
mysql> SELECT GREATEST(2, 5, 12, 3);
Result: 12
mysql> SELECT GREATEST('2', '5', '12', '3');
Result: '5'
mysql> SELECT GREATEST('techonthenet.com', 'checkyourmath.com', 'bigactivities.com');
Result: 'techonthenet.com'
mysql> SELECT GREATEST('techonthenet.com', 'checkyourmath.com', null);
Result: NULLselect last_name form employees where last_name like '_\_a';-- 查询第二个字符是_,第三个字符是a的员工信息
select last_name form employees where last_name like '_$_a' escape '$';-- 定义转义字符别名查找name字段中以'st'为开头的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^st';查找name字段中以'ok'为结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'ok$';查找name字段中包含'mar'字符串的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP 'mar';查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据:
mysql> SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';需要where限制,不然多表会出现错误
SELECT * FROM t1
CROSS JOIN t2
WHERE t1.id = t2.id;限制条件是等于号就是等值连接
一个表连接自己,就是自连接
内连接
外连接
左外连接
右外连接
全外连接
UNION 效率低,会去重
UNION ALL 效率高,不会去重
| Functions - Alphabetical | MySQL Functions listed alphabetically |
|---|---|
| Functions - Category | MySQL Functions listed by category |
-- 五大聚合函数 AVG和SUM只能处理数值类型
SELECT AVG(salary) from employees;
SELECT SUM(salary) from employees;
SELECT MAX(salary) from employees;
SELECT MIN(salary) from employees;
-- 计算指定字段出现的个数时,是不包含null值的
SELECT COUNT(salary) from employees;
-- 比较特殊,返回表有多少行
SELECT COUNT(1) FROM employees;
SELECT COUNT(2) FROM employees;
SELECT COUNT(*) FROM employees;
-- GROUP BY中使用WITH ROLLUP 除了基本查到的数据,还包括不带GROUP BY的AVG(salary)
-- 使用WITH ROLLUP时,不能使用ORDER BY
SELECT department_id,AVG(salary) from employees GROUP BY department_id WITH ROLLUP;CONCAT(S1,S2)
LOWER(str)
UPPER(str)
LPAD( string, length, pad_string )# 填充
# substring
mysql> SELECT SUBSTRING('Techonthenet.com', 5);
Result: 'onthenet.com'
mysql> SELECT SUBSTRING('Techonthenet.com' FROM 5);
Result: 'onthenet.com'
mysql> SELECT SUBSTRING('Techonthenet.com', 1, 4);
Result: 'Tech'
mysql> SELECT SUBSTRING('Techonthenet.com' FROM 1 FOR 4);
Result: 'Tech'
mysql> SELECT SUBSTRING('Techonthenet.com', -3, 3);
Result: 'com'
mysql> SELECT SUBSTRING('Techonthenet.com' FROM -3 FOR 3);
Result: 'com'
# trim
mysql> SELECT TRIM(LEADING ' ' FROM ' techonthenet.com ');
Result: 'techonthenet.com '
mysql> SELECT TRIM(TRAILING ' ' FROM ' techonthenet.com ');
Result: ' techonthenet.com'
mysql> SELECT TRIM(BOTH ' ' FROM ' techonthenet.com ');
Result: 'techonthenet.com'
mysql> SELECT TRIM(' ' FROM ' techonthenet.com ');
Result: 'techonthenet.com'
mysql> SELECT TRIM(' techonthenet.com ');
Result: 'techonthenet.com'
mysql> SELECT TRIM(LEADING '0' FROM '000123');
Result: '123'
mysql> SELECT TRIM(TRAILING '1' FROM 'Tech1');
Result: 'Tech'
mysql> SELECT TRIM(BOTH '123' FROM '123Tech123');
Result: 'Tech'select ceil(1.5);
select floor(1.9);
select mod(3,4);
select rand();
select round(2.34,2);select curdate()
select curtime()
select now()
select year(date)
select month(date)
select day(date)正确的标准SQL查询逻辑处理顺序大致如下:
- FROM:确定查询的数据来源表。
- ON:对连接的表应用ON条件(如果存在JOIN语句)。
- JOIN:根据指定的连接类型(LEFT, RIGHT, INNER等)进行表的连接。
- WHERE:过滤从FROM和JOIN操作得到的数据行。
- GROUP BY:将结果集按指定列分组,通常用于与聚合函数一起使用。
- HAVING:过滤由GROUP BY生成的分组,类似于WHERE但作用于分组。
- SELECT:选择需要显示的列或表达式。
- DISTINCT:去除重复的行(如果指定了DISTINCT关键字)。
- ORDER BY:排序最终的结果集。
- LIMIT/OFFSET:限制返回的行数或跳过指定数量的行(如果指定了的话)。
关于优化方面,确实WHERE子句在大多数情况下比HAVING更高效。这是因为WHERE在分组和聚合之前就过滤掉了不符合条件的数据行,从而减少了后续需要处理的数据量。而HAVING子句则是在数据经过GROUP BY之后才开始过滤,这意味着它可能需要处理更多的数据行。因此,在能够使用WHERE过滤的情况下,优先考虑使用WHERE可以提高查询性能。不过,HAVING对于基于聚合结果的过滤是必不可少的,因为它允许我们基于计算出的汇总值来筛选分组。
单行操作符: = != > < >= <=
多行操作符:IN ANY ALL SOME
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id<>'IT_PROG' AND salary < ANY (SELECT salary FROM employees WHERE job_id='IT_PROG');
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id<>'IT_PROG' AND salary < SOME (SELECT salary FROM employees WHERE job_id='IT_PROG');
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id<>'IT_PROG' AND salary < ALL (SELECT salary FROM employees WHERE job_id='IT_PROG');
SELECT MIN(avg_sal) FROM (SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id) t_dept_avg_sal相关子查询(Correlated Subquery),也称为关联子查询,是一种在外部查询中引用了外部表的列的子查询。这意味着子查询不是独立的——它依赖于外部查询提供的值。因此,对于外部查询返回的每一行,相关子查询都会执行一次。
相关子查询通常用于WHERE或HAVING子句中,用来过滤数据。它们也可以出现在SELECT或FROM子句中,但是这种情况比较少见。相关子查询的一个典型用途是当你需要基于某一行的数据来计算或者判断另一行的数据时。
以下是使用相关子查询的一些示例:
- 查找每个部门工资最高的员工:
SELECT e.name, e.salary, e.department_id
FROM employees e
WHERE e.salary = (
SELECT MAX(sub.salary)
FROM employees sub
WHERE sub.department_id = e.department_id
);- 查找选修了所有课程的学生:
SELECT s.name
FROM students s
WHERE NOT EXISTS (
SELECT c.course_id
FROM courses c
WHERE NOT EXISTS (
SELECT 1
FROM enrollments e
WHERE e.student_id = s.student_id AND e.course_id = c.course_id
)
);- 找出销售额超过该销售员平均销售额的记录:
SELECT s.salesperson_id, s.sale_amount
FROM sales s
WHERE s.sale_amount > (
SELECT AVG(sub.sale_amount)
FROM sales sub
WHERE sub.salesperson_id = s.salesperson_id
);尽管相关子查询非常有用,但需要注意的是,由于每次外部查询迭代时都需要重新执行一次子查询,所以它们可能会导致性能问题,特别是在处理大数据集时。为了提高效率,可以考虑以下几种方法:
- 使用JOIN替代。
- 尝试使用窗口函数(Window Functions),比如
ROW_NUMBER()、RANK()等。 - 确保子查询能够有效地利用索引。
- 对于某些数据库系统,可能还可以使用其他优化技术,如物化视图(Materialized Views)等。
总之,在编写SQL查询时,应根据具体情况评估是否使用相关子查询,并且考虑到潜在的性能影响。
阿里巴巴开发规范:TRUNCATE TABLE 比DELETE速度快,且使用的系统和事务日志资源少,但TRUNCATE无事务且不触发TRIGGER,有可能造成事故,故不建议在开发代码中使用此语句
| 操作 | 是否可回滚 | 是否删除结构 | 是否记录日志 | 是否重置自增 | 推荐开发环境使用 |
|---|---|---|---|---|---|
DROP TABLE |
❌ | ✅ | ❌ | - | ❌(慎用) |
TRUNCATE TABLE |
❌(MySQL)✅(PG等) | ❌ | ❌ | ✅ | ❌(慎用) |
DELETE FROM |
✅(事务内) | ❌ | ✅ | ❌ | ✅(推荐) |
CREATE TABLE test1(
a int,
b int,
c int GENERATED ALWAYS AS (a+b) VIRTUAL); # 字段c即为计算列GENERATED ALWAYS AS (...)表示这是一个 计算列,其值由括号内的表达式自动生成。VIRTUAL表示该列是一个 虚拟列(Virtual Generated Column),即它的值不会实际存储在磁盘上,而是在查询时动态计算出来。
| 特性 | VIRTUAL |
STORED |
|---|---|---|
| 是否物理存储 | ❌ 不存储 | ✅ 存储 |
| 占用空间 | ❌ 几乎不占空间 | ✅ 占用磁盘空间 |
| 查询性能 | ⬇ 动态计算 | ⬆ 直接读取 |
| 更新开销 | ⬆ 小(无需更新) | ⬇ 需要重新计算并写入 |
| 是否可被索引 | ✅(隐式转为 STORED) | ✅ |
CREATE TABLE test_int2(
f1 int,
f2 int(5),
f3 int(5) ZEROFILL)# 1.显示宽度为5,当insert值不足5位时,用0填充 2.当使用ZEROFILL时,自动添加UNSIGNED| 场景 | 建议 |
|---|---|
| 需要格式化输出(如发票号、订单号等) | 不推荐用 ZEROFILL,建议在应用层格式化(如 Python 的 .zfill()) |
| 存储正整数(如 ID、计数器) | 推荐使用 UNSIGNED |
| 需要控制数据显示格式 | 在应用层处理更灵活 |
| 简单了解数据长度(用于文档目的) | 可以保留 INT(5) 这类写法,但不要依赖其行为 |
浮点型:FLOAT DOUBLE
定点型:DECIMAL
位类型:BIT
### 日期和时间类型
CHAR和VARCHAR的选择:
- 存储很短且位数相对固定的数据,用CHAR
- 十分频繁改变的column,用VARCHAR
- 在MYISAM存储引擎中,用CHAR;在MEMORY存储引擎中都可以;在INNODB存储引擎中,主要影响性能的因素是数据行使用的数据总量,多用VARCHAR
TEXT文本类型:可以存储比较大的文本段,由于TEXT和BLOB类型的数据删除后容易导致“空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含TEXT类型字段,建议单独分出去一个表
BLOB:实际工作中,不会用BLOB村大对象数据,会将图片、音频、视频文件存储到服务器的磁盘上,并将图片、音频和视频的访问路径存储到MYSQL中
-- 查询某个表的约束
select * from information_schema.table_constraints where table_name='employees';-- 创建表时添加列级约束和表级约束
create table emp(
name VARCHAR(15) NOT NULL,
last_name VARCHAR(15),
salary DECIMAL(10,2),
constraint uk_emp_last_name unique(last_name)-- constraint uk_emp_last_name 可省略
);-- 修改约束 方式一
alter table emp
modify name VARCHAR(15) NULL;
-- 修改约束 方式二
alter table test2
add constraint uk_test2_sal unique(salary);创建复合唯一性约束
create table `user`(
id int,
`name` varchar(15),
`password` varchar(25),
constraint uk_user_name_pwd unique(`name`,`password`)
);要删除唯一性约束,就要删除唯一性索引
alter table test2
drop index last_name;主键约束=唯一性约束+非空约束
对于外键约束,最好采用下面的方式:
on update cascade on delete set null(更新主表数据时从表数据级联更新,删除主表数据时从表数据设为null)
-- 主表
create table dept(
dept_id int primary key,-- 必须有主键约束,不然创建外键会失败报错
dept_name varchar(15)
);
-- 从表
create table empl(
emp_id int primary key auto_increment,
emp_name varchar(15),
department_id int,
constraint fk_empl_dept_id foreign key (department_id) references dept(dept_id) on update cascade on delete set null
);-- 删除外键约束
alter table empl
drop foreign key fk_empl_dept_id;
-- 查看empl的索引
show index from empl;
alter table empl
drop index fk_empl_dept_id;在mysql中,外键约束是有成本的,需要消耗系统资源。对于大并发的sql操作,有可能会不适合
阿里巴巴规范强制不能使用外键
在 MySQL 8.0 及以上版本中使用
CHECK约束,MYSQL 5.7虽然支持CHECK语法,但它并不会实际执行这些约束
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
salary DECIMAL(10,2),
CHECK (salary > 0)
);在这个例子中,CHECK (salary > 0) 确保了任何试图插入或更新 salary 字段使其值小于等于 0 的操作都会失败。
如果你需要更复杂的约束条件,可以结合多个字段进行检查。例如,假设我们希望确保员工的入职日期不能晚于当前日期:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
hire_date DATE,
CHECK (hire_date <= CURDATE())
);不过需要注意的是,CURDATE() 函数在这种情况下可能不会按照预期工作(因为它是动态计算的),所以更好的做法是让应用程序层处理这种类型的验证或者使用触发器来实现类似的功能。
你也可以在一个表上定义多个 CHECK 约束:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT,
salary DECIMAL(10,2),
CHECK (age >= 18 AND age <= 65),
CHECK (salary > 0)
);数据库对象包括:
- 用户(对数据库有权限访问的人)
- 视图(显示用户需要的数据项)
- 索引(给用户提供快速访问数据的途径)
- 触发器(用户定义的SQL事务命令集合)
- 序列(提供了唯一数值的顺序表)
- 图表(数据库表之间的一种关系示意图)。
视图和表之间是双向绑定的,视图就可以看做存储起来的select语句
-- 创建视图
create view 视图名称
as 查询语句阿里规范禁止使用存储过程,因为存储过程的移植性很差并且很难调试
-- 创建存储过程
delimiter $
create procedure select_all_data()
begin
select * from emps;
end $
delimiter ;-- 调用存储过程
call select_all_data();-- 带返回值的存储过程
delimiter $
create procedure show_min_salary(out ms double)
begin
select min(salary) into ms
from employees;
end $
delimiter ;-- 调用存储过程,并将返回值存储到用户定义的@ms变量中
call show_min_salary(@ms);-- 创建存储函数
delimiter //
create function email_by_name()
returns varchar(25)
deterministic -- 确定性的
contains sql -- 包含sql的
reads sql data -- 读取sql数据的
begin
select email from employees where last_name='Abel';
end //
delimiter ;-- 调用存储函数
select email_by_name();set global log_bin_trust_function_creator=1;-- 创建函数前执行此语句,保证函数的创建会执行成功
delimiter //
create function email_by_name(emp_id int)
returns varchar(25)
begin
return (select email from employees where employee_id=emp_id);
end //
delimiter ;set @emp_id=102;
select email_by_name(@emp_id);变量:
- 系统变量
- 全局系统变量(global):不能跨重启
- 会话系统变量(session)
- 用户自定义变量
- 会话用户变量
- 局部变量:写在存储过程或存储函数中
show global variables;
show session variables;
show variables;-- 默认查询的是会话系统变量select @@global.max_connections;-- 查看指定的全局系统变量
select @@session.pseudo_thread_id;-- 查看指定的会话系统变量
select @@character_set_client;-- 先查询会话系统变量,再查询全局系统变量-- 修改全局系统变量
set @@global.max_connections=161;
set global max_connections=161;-- set @用户变量:=表达式
set @m1=1;
select @count:=count(*) from employees;-- 不能省略冒号
select avg(salary) into @avg_sal from employees;delimiter $
create procedure test_var()
begin
declare a int default 0;
declare b int;
end $
delimiter ;
错误码的说明:
MySQL_error_code和sqlstate_value都可以表示MYSQL的错误
MySQL_error_code是数值类型错误代码sqlstate_value是长度为5的字符串类型错误代码例如:在ERROR 1418(HY000)中,1418是
MySQL_error_code,HY000是sqlstate_value
-- 定义条件
declare Field_Not_Be_Null condition for 1048;-- `MySQL_error_code`
declare Field_Not_Be_Null condition for sqlstate '23000';-- `sqlstate_value`MySQL 中可以使用 DECLARE 关键字来定义处理程序。其基本语法如下:
-- 定义处理程序
-- declare 处理方式 handler for 错误类型 处理语句
DECLARE handler_type HANDLER FOR condition_value[...] sp_statement其中,handler_type 参数指明错误的处理方式,该参数有 3 个取值。这 3 个取值分别是 CONTINUE、EXIT 和 UNDO。
CONTINUE表示遇到错误不进行处理,继续向下执行;EXIT表示遇到错误后马上退出;UNDO表示遇到错误后撤回之前的操作,MySQL 中暂时还不支持这种处理方式。
注意:通常情况下,执行过程中遇到错误应该立刻停止执行下面的语句,并且撤回前面的操作。但是,MySQL 中现在还不能支持 UNDO 操作。因此,遇到错误时最好执行 EXIT 操作。如果事先能够预测错误类型,并且进行相应的处理,那么可以执行 CONTINUE 操作。
condition_value参数指明错误类型,该参数有 6 个取值:
SQLSTATE sqlstate_value:包含 5 个字符的字符串错误值;condition_name:表示 DECLARE 定义的错误条件名称;SQLWARNING:匹配所有以 01 开头的 sqlstate_value 值;NOT FOUND:匹配所有以 02 开头的 sqlstate_value 值;SQLEXCEPTION:匹配所有没有被 SQLWARNING 或 NOT FOUND 捕获的 sqlstate_value 值;MySQL_error_code:匹配数值类型错误代码。
下面是定义处理程序的几种方式,代码如下:
-- 方法一:捕获 sqlstate_value
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info='CAN NOT FIND';
-- 方法二:捕获 mysql_error_code
DECLARE CONTINUE HANDLER FOR 1146 SET @info='CAN NOT FIND';
-- 方法三:先定义条件,然后调用
DECLARE can_not_find CONDITION FOR 1146;
DECLARE CONTINUE HANDLER FOR can_not_find SET @info='CAN NOT FIND';
-- 方法四:使用 SQLWARNING
DECLARE EXIT HANDLER FOR SQLWARNING SET @info='ERROR';
-- 方法五:使用 NOT FOUND
DECLARE EXIT HANDLER FOR NOT FOUND SET @info='CAN NOT FIND';
-- 方法六:使用 SQLEXCEPTION
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info='ERROR';流程控制只能在存储过程和存储函数中执行
游标在存储过程和存储函数中的使用步骤:
declare游标
open游标
fetch游标
close游标
DELIMITER //
CREATE FUNCTION FindSiteID ( name_in VARCHAR(50) )
RETURNS INT
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE siteID INT DEFAULT 0;
DECLARE c1 CURSOR FOR
SELECT site_id
FROM sites
WHERE site_name = name_in;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
OPEN c1;
FETCH c1 INTO siteID;
CLOSE c1;
RETURN siteID;
END; //
DELIMITER ;DELIMITER //
CREATE PROCEDURE get_count_by_limit_total_salary(IN limit_total_salary DOUBLE,OUT total_count INT)
BEGIN
DECLARE sum_salary DOUBLE DEFAULT 0; #记录累加的总工资
DECLARE cursor_salary DOUBLE DEFAULT 0; #记录某一个工资值
DECLARE emp_count INT DEFAULT 0; #记录循环个数
#定义游标
DECLARE emp_cursor CURSOR FOR SELECT salary FROM employees ORDER BY salary DESC;
#打开游标
OPEN emp_cursor;
REPEAT
#使用游标(从游标中获取数据)
FETCH emp_cursor INTO cursor_salary;
SET sum_salary = sum_salary + cursor_salary;
SET emp_count = emp_count + 1;
UNTIL sum_salary >= limit_total_salary
END REPEAT;
SET total_count = emp_count;
#关闭游标
CLOSE emp_cursor;
END //
DELIMITER ;DELIMITER //
CREATE TRIGGER contacts_before_insert
BEFORE INSERT
ON contacts FOR EACH ROW
BEGIN
DECLARE vUser varchar(50);
-- Find username of person performing INSERT into table
SELECT USER() INTO vUser;
-- Update create_date field to current system date
SET NEW.created_date = SYSDATE();
-- Update created_by field to the username of the person performing the INSERT
SET NEW.created_by = vUser;
END; //
DELIMITER ;
CREATE TABLE copyDbName AS SELECT * FROM dbName复制表
CREATE TABLE copyDbName AS SELECT * FROM dbName WHERE 1=2复制表结构
-
字符集指的是某个字符范围的编码规则,UTF8mb4是UTF8mb3的超集,用于存储emoji-
在MYSQL8.0之前,默认字符集为latin1,utf8字符集指向的时utfmb3
-
从MYSQL8.0开始,数据库的默认编码将改为utf8mb4,从而解决中文乱码问题
-
-
比较规则是针对某个字符集中的字符比较大小的一种规则。 -
在
MySQL中,一个字符集可以有若干种比较规则,其中有一个默认的比较规则,一个比较规则必须对应一个字符集。 -
查看
MySQL中查看支持的字符集和比较规则的语句如下:SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式]; SHOW COLLATION [LIKE 匹配的模式];
-
MySQL有四个级别的字符集和比较规则
-
服务器级别
character_set_server表示服务器级别的字符集,collation_server表示服务器级别的比较规则。 -
数据库级别
创建和修改数据库时可以指定字符集和比较规则:
CREATE DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称]; ALTER DATABASE 数据库名 [[DEFAULT] CHARACTER SET 字符集名称] [[DEFAULT] COLLATE 比较规则名称];character_set_database表示当前数据库的字符集,collation_database表示当前默认数据库的比较规则,这两个系统变量是只读的,不能修改。如果没有指定当前默认数据库,则变量与相应的服务器级系统变量具有相同的值。 -
表级别
创建和修改表的时候指定表的字符集和比较规则:
CREATE TABLE 表名 (列的信息) [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称]]; ALTER TABLE 表名 [[DEFAULT] CHARACTER SET 字符集名称] [COLLATE 比较规则名称]; -
列级别
创建和修改列定义的时候可以指定该列的字符集和比较规则:
CREATE TABLE 表名( 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称], 其他列... ); ALTER TABLE 表名 MODIFY 列名 字符串类型 [CHARACTER SET 字符集名称] [COLLATE 比较规则名称];
- 从发送请求到接收结果过程中发生的字符集转换:
- 客户端使用操作系统的字符集编码请求字符串,向服务器发送的是经过编码的一个字节串。
- 服务器将客户端发送来的字节串采用
character_set_client代表的字符集进行解码,将解码后的字符串再按照character_set_connection代表的字符集进行编码。 - 如果
character_set_connection代表的字符集和具体操作的列使用的字符集一致,则直接进行相应操作,否则的话需要将请求中的字符串从character_set_connection代表的字符集转换为具体操作的列使用的字符集之后再进行操作。 - 将从某个列获取到的字节串从该列使用的字符集转换为
character_set_results代表的字符集后发送到客户端。 - 客户端使用操作系统的字符集解析收到的结果集字节串。
在这个过程中各个系统变量的含义如下:
| 系统变量 | 描述 |
|---|---|
character_set_client |
服务器解码请求时使用的字符集 |
character_set_connection |
服务器处理请求时会把请求字符串从character_set_client转为character_set_connection |
character_set_results |
服务器向客户端返回数据时使用的字符集 |
一般情况下要使用保持这三个变量的值和客户端使用的字符集相同。
show variables like 'datadir';-- 查看mysql数据库和表存放位置
MYSQL8.0参考手册-File-Per-Table 表空间
-- 创建用户只能在本机访问
create user 'itcast'@'localhost' identified by '123456';
-- 创建用户可以远程访问
create user 'heima'@'%' identified by '123456';
-- 修改用户密码
alter user 'heima'@'%' identified with mysql_native_password by '1234';
-- 删除用户
drop user 'heima'@'%';
-- 查询权限
show grants for 'heima'@'%'
-- 授予权限
GRANT ALL ON db1.* TO 'jeffrey'@'localhost';
GRANT 'role1', 'role2' TO 'user1'@'localhost', 'user2'@'localhost';
GRANT SELECT ON world.* TO 'role3';
-- 撤销权限
REVOKE INSERT ON *.* FROM 'jeffrey'@'localhost';
REVOKE 'role1', 'role2' FROM 'user1'@'localhost', 'user2'@'localhost';
REVOKE SELECT ON world.* FROM 'role3';MYSQL是典型的C/S架构,服务端程序使用的时
mysqld



SQL执行流程:SQL语句->查询缓存->解析器->优化器->执行引擎

MYSQL8.0用户手册-SHOW PROFILE Statement
MYSQL8.0用户手册-SHOW PROFILES Statement
select @@session.profiling;-- 0 默认执行过程是关闭的 set profiling=1;-- 开启执行细节 show profiles;-- 查询最近执行的SQL语句 show profile;-- 查看最近一次SQL执行细节 show profile for query 7;-- 查询某个SQL语句的执行细节 show profile cpu,block io for query 7;-- 查看包括cpu、IO阻塞等参数的SQL执行细节
查询缓存往往弊大于利,所以在MYSQL8.0中去掉了,而在MYSQL5.7中,可以编辑
my.cnf开启查询缓存# query_cache_type有三个值(0代表关闭查询缓存OFF,1代表开启ON,2代表DEMAND(当sql语句中有SQL_CACHE关键词才缓存)) query_cache_type=2select SQL_CACHE * from test where ID=5;-- 要去查询缓存确认 select SQL_NO_CACHE * from test where ID=5;-- 不去查询缓存确认show status like '%Qcache%';-- 显示 查询缓存 相关情况
BufferPool就是存储引擎向操作系统申请一段连续的内存空间,是为了减少与磁盘进行IO的时间,缓存的是热点数据。
数据库缓冲池还具有预读的特性,当我们使用了某些数据页的数据,在缓冲池空间足够的情况下,会将该数据页前后的数据页加载到数据库缓冲池。
缓冲池会采用checkpoint检查点机制将更新之后缓存的数据刷盘到磁盘上。
多实例的数据库缓冲池是为了缓解多线程并发压力,当缓冲池大小小于1GB时,设置多实例是无效的。
查询缓存和数据库缓冲池不是一个东西:
- 查询缓存是缓存SQL语句
- 缓冲池缓存的时数据页数据
show variables like 'key_buffer_size';-- 查看MYISAM缓冲池大小
show variables like 'innodb_buffer_pool_size';-- 查看INNODB的缓冲池大小
show variables like 'innodb_buffer_pool_instance';-- 查看缓冲池实例个数[server]
# 配置多实例的数据库缓冲池
innodb_buffer_pool_instances=2
存储引擎(也叫表处理器)决定表和数据在底层的存储方式
show engines;-- 查看数据库支持的存储引擎
show variables like '%storage_engine%';-- 查看当前使用的存储引擎 下图可知:
InnoDB是唯一支持事务、分布式事务(XA)、保存点(部分事务回滚)的存储引擎

MYSQL8.0参考手册-Introduction to InnoDB
优点:
- 外键
- 事务
- 行级锁
缺点:
- 处理效率差一些,会占用更多磁盘空间以保存数据和索引
- 对内存要求高一些
优点:
- 访问速度快,适合对事务完整性没有要求或者以select\insert为主的应用
- count(*)查询效率很高
缺点:
- 太多啦~~
- 优点:
- 仅仅支持select\insert两种操作,适合日志和数据采集(档案)类应用
- 优点:
- 响应速度快,比MyISAM快一个数量级
InnoDB索引底层是B+树索引按照物理实现方式:
- 聚簇索引:并不是一种单独的索引类型,而是一种数据存储方式(所有的用户记录都存储在了叶子节点),也就是索引即数据,数据即索引。不需要显式用Index语句创建,InnoDB存储引擎会自动创建聚簇索引
- 优点:
数据访问更快,聚簇索引将索引和数据保存在同一个B+树中,因此比非聚簇索引快- 对于
主键的排序查找和范围查找速度非常快- 查询显示一定范围数据时,由于数据时紧密相连的,数据库不用从多个数据块中提取数据,所以
节省了大量IO操作- 缺点:
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此对于InnoDB表,一般会定义一个自增的ID列为主键更新主键的代价很高,因为将会导致被更新的行移动。因此对于InnoDB表,一般定义主键不可更新二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据- 限制:
- MYSQL数据库目前只有InnoDB支持聚簇索引,MyISAM并不支持聚簇索引
- 由于数据物理存储排序方式只能有一种,所以每个MYSQL表
只能有一个聚簇索引。一般情况下就是该表的主键- 如果没有定义主键,InnoDB会选择非空的唯一索引代替。如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引
- 为了充分利用聚簇索引的聚簇的特性,InnoDB表的主键列尽量
选用有序的顺序ID,而不建议用无序的ID,比如UUID、MD5、HASH、字符串列作为主键无法保证数据的顺序增长- 二级索引
- 联合索引(可以理解为联合主键聚簇索引)
- 回表的概念:
- 我们根据这个以c2列大小排序的B+树只能确定我们要查找的记录的主键值,索引我们想根据c2列的值找到到完整的用户记录的话,仍然需要到聚簇索引中再查一遍,这个过程称为
回表。也就是根据c2列的值查询一条完整的用户记录需要用到2棵B+树直接把完整用户记录放在非聚簇索引的叶子节点是不靠谱的,因为这会造成巨大的空间冗余



InnoDB的B+树索引的注意事项:
根页面的位置万年不动非聚簇索引的目录页节点记录要唯一,若不唯一,添加主键来保持唯一一个页面最少要存储两条数据
InnoDB、MyISAM、Memory都支持B+树索引
MyISAM使用B+树作为索引结构,叶子节点的data域存放的是数据记录的地址,所以MyISAM索引和数据是分开的
MyISAM中只有非聚簇索引,因为数据和索引是分离的
- MyISAM中的索引方式都是非聚簇的,InnoDB中必然包含一个聚簇索引
- 在InnoDB中,只需要根据主键值进行一次查询就能找到对应的记录,因为InnoDB中索引即数据,而在MyISAM中却需要进行一次回表操作(通过B+数中地址去取数据),意味着MyISAM中建立的索引全部都是二级索引
- MyISAM中索引和数据是分离的,InnoDB中索引即数据
- InnoDB的非聚簇索引data域存储的是主键的值,而MyISAM索引data域记录的是回表的地址
- MyISAM回表是十分快速的,因为拿着地址偏移量直接到文件中取数据;InnoDB是通过获取主键之后再去聚簇索引中招记录。
- InnoDB必须有主键,如果没有显式指定,MYSQL会自动选择一个可以非空且唯一标识的数据记录的列作为主键,如果不存在这种咧,MYSQL会为InnoDB表生成一个隐含字段作为主键;MyISAM不一定有主键,但推荐加主键
就如同字典的目录的代价,每添加或删除一个字都需要目录页发生变化,在索引中就是页分裂。然后空间上就是目录本身也占用字典空间嘛,虽然占用不多。
Hash结构效率高,为什么索引结构要设计成树型?
- Hash索引仅能满足(=)(<>)和IN查询。如果进行范围查询,哈希型的索引,时间复杂度会退化成O(n);而树形的有序特性,依然能够保持O(log2N)的高效率。
即范围查找时树形更有优势Hash索引数据的存储是没有顺序的,在order by的情况下,使用Hash索引还需要对数据进行重新排序。- 对于联合索引,Hash值是将联合索引键合并后一起来计算的,无法对单独的一个键或者几个索引键进行查询
- 对于等值查询,通常Hash索引的效率更高,不过如果索引列的重复值很多,效率就会降低
Redis存储到核心就是Hash表
Memory的默认索引是Hash索引InnoDB本身不支持Hash索引,但是提供
自适应Hash索引,会将热点数据的数据页地址存放到Hash表中。这样让B+树也具备了Hash索引的优点因为同样的磁盘页大小,B+树可以存储更多的节点关键字,所以B+树通常比B树更加矮胖,查询所需要的磁盘IO会更少
R树是高维空间的B树,用于存储地理空间数据
B+树只在最底层保存数据,B树在非叶子结点和叶子结点都保存数据
B+树的高度通常是2~4层,由于根节点常驻内存,所以最多只需1~3次磁盘IO便可查询一次
InfoQ-【Mysql-InnoDB 系列】InnoDB 架构
InnoDB页的默认大小是16KB,不同的DBMS的数据页大小不同
页的结构概述:
页作为磁盘和内存之间交互的基本单位,页与页之间不在物理结构上相连,只需通过双向链表相关联即可。每个数据页中的记录是按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里面的记录生成一个页目录,通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再便利该槽对应分组中的记录即可快速找到指定的记录页的上层结构:
- 区:在InnoDB中,一个区会分配64各连续的页
- 段:是数据库中分配的单位,不同类型的数据库对象以不同的段形式存在,常见的段有
数据段、索引段、回滚段- 表空间:是一个逻辑容器,分为系统表空间、用户表空间、撤销表空间、临时表空间等,数据库由一个或多个表空间组成
页的内部结构:
- 页如果按类型划分的话,常见的有
数据页、系统页、Undo页和事务数据页等InnoDB行格式row_format:
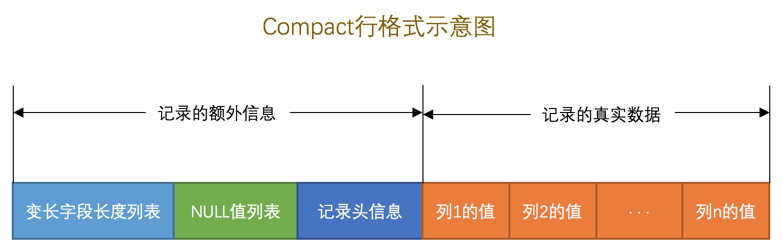
COMPACT行格式
具体组成如图:
Redundant行格式
具体组成如图:
Dynamic和Compressed行格式
这两种行格式类似于
COMPACT行格式,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字符串的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。另外,
Compressed行格式会采用压缩算法对页面进行压缩。一个页一般是
16KB,当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中,这种现象称为行溢出。碎片区:有些页能用于段A,有些页能用于段B,碎片去直属于表空间


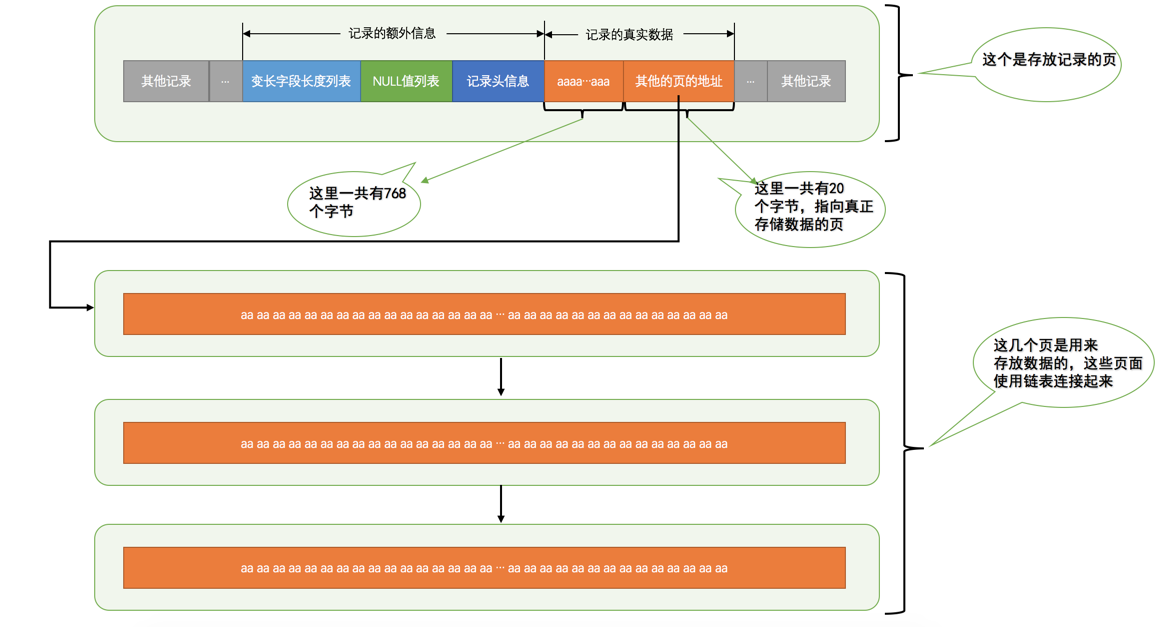
索引的分类:
- 从功能逻辑上分
- 普通索引
- 唯一索引
- 主键索引
- 全文索引
- 从物理实现方式分(一般说这个)
- 聚簇索引
- 非聚簇索引
- 从作用字段个数分
- 单列索引
- 联合索引
最左前缀原则- 从创建方式分
- 隐式创建索引:在声明有主键约束、唯一性约束、外键约束的字段上,会自动添加相关索引
- 显式创建索引
不同存储引擎支持的索引类型不同

-- 通过命令查看索引
show create table book;
show index from book;
MYSQL8.0参考手册-EXPLAIN/DESCRIBE Statement
MYSQL8.0参考手册-EXPLAIN Output Format
MYSQL8.0参考手册-SHOW STATUS Statement
MYSQL8.0参考手册-mysqldumpslow — Summarize Slow Query Log Files
MYSQL8.0参考手册-SHOW WARNINGS Statement
MYSQL8.0源码手册-The Optimizer Trace
The Unofficial MySQL 8.0 Optimizer Guide
InfoQ-sys库常用命令,用于汇总performanceschema
mysql> SHOW STATUS;
+--------------------------+------------+
| Variable_name | Value |
+--------------------------+------------+
| Aborted_clients | 0 |
| Aborted_connects | 0 |
| Bytes_received | 155372598 |
| Bytes_sent | 1176560426 |
| Connections | 30023 |
| Created_tmp_disk_tables | 0 |
| Created_tmp_tables | 8340 |
| Created_tmp_files | 60 |
...
| Open_tables | 1 |
| Open_files | 2 |
| Open_streams | 0 |
| Opened_tables | 44600 |
| Questions | 2026873 |
...
| Table_locks_immediate | 1920382 |
| Table_locks_waited | 0 |
| Threads_cached | 0 |
| Threads_created | 30022 |
| Threads_connected | 1 |
| Threads_running | 1 |
| Uptime | 80380 |
+--------------------------+------------+
-- 比较不同查询开销的依据
mysql> SHOW STATUS like 'last_query_cost';
-- 记录为慢查询SQL最短时间
mysql> SHOW variables like 'long_query_time';
Variable_name |Value |
---------------+---------+
long_query_time|10.000000|
mysql> SHOW variables like 'slow_query_log';
Variable_name |Value|
--------------+-----+
slow_query_log|OFF |
-- 开启慢查询日志
mysql> set global slow_query_log='ON';
-- 设置慢查询SQL最短时间
mysql> set global long_query_time=1;
mysql> set long_query_time=1;
mysql> SHOW variables like 'slow_query_log_file';
Variable_name |Value |
-------------------+-----------------------------------------------------+
slow_query_log_file|/usr/local/mysql/data/dongbinyudeMacBook-Pro-slow.log|
mysql> SHOW global status like '%slow_queries%';
Variable_name|Value|
-------------+-----+
Slow_queries |0 |
-- 可以查看并打开执行成本分析
mysql> SHOW variables like 'profiling';
mysql> set profiling='ON';
-- 打开后可以查看最近的查询执行成本
mysql> show profiles;
mysql> show profile;
mysql> show profile for query query_id;-- 查询冗余索引
select * from sys.schema_redundant_indexes;
-- 查询未使用过的索引
select * from sys.schema_unused_indexes;都有哪些维度可以进行数据库调优?简言之:
- 索引失效、没有充分利用到索引一一索引建立
- 关联查询太多JOIN(设计缺陷或不得已的需求)一一SQL优化
- 服务器调优及各个参数设置(缓冲、线程数等)--调整my.cnf
- 数据过多一一分库分表
关于数据库调优的知识点非常分散。不同的DBMS,不同的公司,不同的职位,不同的项目遇到的问题都不尽相同。这里我们分为三个章节进行细致讲解。 虽然SQL查询优化的技术有很多,但是大方向上完全可以分成
物理查询优化和逻辑查询优化两大块。
- 物理查询优化是通过
索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用。- 逻辑查询优化就是通过
SQL等价变换提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高。
- 全值匹配我最爱,即等值匹配我最爱
- 最佳左前缀法则
- 主键插入顺序依次递增,可以减少性能损耗(页分裂)
- 计算、函数、类型转换(自动或手动)会导致索引失效
- 范围条件右侧的列失效(> < between)
- 不等于(!=或<>)索引失效
is null可以使用索引,is not null不能使用索引。最好在设计数据表时将字段设置为NOT NULL约束,比如可以将int默认值设置为0,字符串默认值设置为""- like以通配符%开头失效。页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎(ES)来解决
- OR前后存在非索引的列,索引失效
- 数据库和表的字符集必须统一
对于内连接来说,查询优化器可以决定谁作为驱动表,谁做为被驱动表;
对于内连接来说,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表;
对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表,即小表驱动大表(准确说是小结果集驱动大结果集,join buffer每一次放的内容越多越好)
对左外连接来说,前面的表不一定是驱动表,因为查询优化器可能会将左外连接转换成内连接MYSQL5.7还用的是BNLJ算法,MYSQL8.0换为了HashJoin
博客园-MySQL-join的实现原理、优化及NLJ和BLJ算法
ServerFault-join_buffer_size >= 4 M is not advised?
可以使用JOIN查询来替代子查询,连接查询不需要建立临时表,速度快尽量不要使用NOT IN或者NOT EXISTS,改造如下图所示

ORDER BY字段上加索引的话,可以避免FileSort排序,效率更高MySQL支持两种排序方式:
Index排序,索引可以保证数据的有序性,不需要再进行排序,效率更高
FileSort排序,则一般在内存中进行排序,占用CPU较多,如果待排结果较大,会产生临时文件IO到磁盘进行排序,效率低
- 使用的算法是
单路排序,比双路排序快,也占用更多的内存
掘金-MySQL 中 Using filesort 问题的优化方法
使用索引的原则和Order by一致
一个索引包含了满足查询结果的数据就叫做覆盖索引
简单来说,在查
索引列+主键以内的字段时,会用到覆盖索引
索引下推是查询优化器的策略,回表前过滤,可以减少回表次数
# 关闭索引下推
set optimizer_switch='index_condition_pushdown=off'A表小就用EXISTS,B表小就用IN
# B表是小表选Exists
select * from A where cc in (select cc from B);
# A表时小表时选in
select * from A where exists (select cc from B where B.cc=A.cc);
Count(*)和Count(1)可以看成效率是相等的
MyISAM的Count是O(1)复杂度
Count(具体字段),要尽量采用二级索引,因为聚簇索引信息多,性能就差些;如果有多个二级索引,会使用key_len小的二级索引扫描;当没有二级索引时,才会采用主键索引来进行统计
MySQL在解析过程中,会通过查询数据字段将*按序转换成所有列明,这会大大耗费资源和时间
无法使用到覆盖索引
如果可以确定结果集只有一条,那么加上limit 1时,找到一条结果就不会继续扫描了,会加快查询速度
如果数据表已经对字段建立了唯一索引,就不需要加上limit 1 了
Commit释放的资源:
- 回滚段上用于回复数据的信息
- 被程序语句获得的锁
- redo/undo log buffer中的空间
- 管理上述3种资源中的内部花费
使用有序UUID
- 全局唯一
- 尽量有序
键的相关概念:
学生信息(学号 身份证号 性别 年龄 身高 体重 宿舍号)和 宿舍信息(宿舍号 楼号)
超键:只要含有“学号”或者“身份证号”两个属性的集合就叫超键,例如R1(学号 性别)、R2(身份证号 身高)、R3(学号 身份证号)等等都可以称为超键!
候选键:不含有多余的属性的超键,比如(学号)、(身份证号)都是候选键,又比如R1中学号这一个属性就可以唯一标识元组了,而有没有性别这一属性对是否唯一标识元组没有任何的影响!
主键:就是用户从很多候选键选出来的一个键就是主键,比如你要求学号是主键,那么身份证号就不可以是主键了!
外键:宿舍号就是学生信息表的外键
范式:
- 第一范式:字段不可再分
- 第二范式:满足数据表里的每一条数据记录都是可唯一标识的,而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分(一个表一个对象)
- 第三范式:要求数据表中的所有非主键字段不能依赖于其他非主键字段
可以适当反范式化
mac没有这个软件耶,算了反正工作用不到
对于
内连接的两个表,驱动表中的记录在被驱动表中找不到匹配的记录,该记录不会加入到最后的结果集,我们上面提到的连接都是所谓的内连接。对于
外连接的两个表,驱动表中的记录即使在被驱动表中没有匹配的记录,也仍然需要加入到结果集。下面这四种写法是等价的:
连接的原理:
- 嵌套循环连接
- 使用索引加快连接速度
- 使用join buffer减少IO次数,实现基于块的嵌套循环连接
MYSQL8.0参考手册-事务隔离级别Transaction Isolation Levels
MYSQL8.0参考手册-事务START TRANSACTION, COMMIT, and ROLLBACK Statements
MYSQL8.0参考手册-保存点SAVEPOINT, ROLLBACK TO SAVEPOINT, and RELEASE SAVEPOINT Statements
MYSQL8.0参考手册-
innodb_flush_log_at_trx_commitMYSQL8.0参考手册-数据备份InnoDB Backup
MYSQL8.0参考手册-崩溃恢复InnoDB Recovery
事务的合理性由锁机制实现
而事务的原子性、一致性和持久性由REDO日志和UNDO日志来保证:
REDO LOG称为 重做日志,记录的是物理级别上页修改操作,比如页号xxx、偏移量yyy写入了zzz数据。用于保证事务的持久性UNDO LOG称为 回滚日志,记录的是逻辑操作日志,比如对某一行数据进行了insert语句,UNDO LOG就记录一条预支相反的DELETE操作。用于回滚行记录到特定版本,用来保证事务的原子性、一致性REDO和UNDO都可以视为一种
恢复操作
锁是计算机协调多个进程或线程并发访问某一资源的机制
MYSQL并发事务访问相同记录:
- 读读情况:不会产生并发问题
- 写写情况:锁机制可以解决,任何一种隔离级别都不允许这种情况的发生
- 读写情况:会产生脏读、不可重复读、幻读的问题,通过事务隔离级别解决
各个数据库厂商对SQL标准的支持不一样,比如MYSQL在
REPEATABLE READ隔离级别上就已经解决了幻读问题
MYSQL并发问题的解决有两种思路:
- 读操作利用
多版本并发控制MVCC,写操作进行加锁
- MVCC:就是生成一个
READVIEW,通过READVIEW找到符合条件的记录版本(历史记录由UNDO日志构建)。查询语句只能读到READVIEW之前已提交事务所做的更改,在生成READVIEW之前未提交的事务过着之后才开启的事务所做的更改是看不到的。而写操作肯定针对的是最新版本的记录,读记录的历史版本和改动记录的最新版本身并不冲突,也就是采用MVCC时,读写操作并不冲突普通的SELECT语句在
READ COMMITED和REPEATABLE READ隔离级别下会使用到MVCC读取记录:
READ COMMITED级别下:一个事务在执行过程中每次执行SELECT操作都会生成一个READVIEW,READVIEW的存在本身就保证了不会出现脏读现象REPEATABLE READ级别下:一个事务在执行过程中只有第一次执行SELECT操作才会生成一个READVIEW,之后的SELECT操作都是复用这个READVIEW,这样就避免了不可重复读和幻读的现象
- 读写操作都加锁
- 有些场景下,比如银行存款的事务中,读操作也需要加锁
一般情况下,我们愿意
采用MVCC来解决读写问题,因为性能更高
读锁可以是共享锁或排他锁
写锁必须是排他锁
SELECT ... LOCK IN SHARE MODE;-- 共享锁 MYSQL5.7写法
select ... for share;-- 共享锁 MYSQL8.0写法
select ... for update;-- 独占锁 MYSQL5.7和8.0写法
select ... for update nowait;-- MYSQL8.0写法 获取不到锁,立即报错返回
select ... for update skip locked;-- MYSQL8.0写法 获取不到锁,返回没有被锁定的数据
- 表锁:开销最小,锁粒度大, 并发性差
- 表级别的S锁、X锁:InnoDB一般不用表锁,而用粒度更小的行锁
意向锁(intention lock):如果我们给某一行加上了排他锁,数据库会自动给更大一级的空间,比如数据页或数据表加上意向锁,告诉其他人这个数据页或者数据表已经有人加上排他行锁了,不能再加表级锁。理解为加锁标记。不需要我们手动设置自增锁(AUTO-INC lock):自增列的表自动加上自增锁元数据锁(MDL lock):当对一个表做增删改查操作时,加MDL读锁;当要对表做结构变更操作时,加MDL写锁。不需要我们手动设置
lock tables mylock read;-- 表级别读锁
show open tables where in_use>0;-- 查看有哪些表被加锁了
unlock tables;
lock tables mylock write;-- 表级别写锁
show open tables where in_use>0;
unlock tables;
SHOW [FULL] PROCESSLIST;-- MySQL 进程列表指示当前由服务器内执行的一组线程执行的操作


- 行锁:锁力度小,并发性好;锁开销大,加锁比较慢,容易出现死锁
记录锁(Record lock):分记录S锁和记录X锁间隙锁(Gap lock):MVCC方案在加锁时,事务在第一次执行读取操作时,那些幻影记录尚不存在,无法给幻影记录加上记录锁,就为区间内加上间隙锁;但是间隙锁可能会造成死锁临键锁(Next key lock):本质是记录锁和间隙锁的合体插入意向锁(Insert intention lock):InnoDB规定事务在等待的时候也需要一个内存结构,插入一条记录时要判断插入位置是不是被别的事务加了gap锁。插入意向锁也是一种间隙锁(Gap锁),插入意向锁之间不会有冲突



页锁:介于行锁和表锁之间
锁空间的大小是优先的,当某个层级的锁数量超过了这个层级的阈值时,就会进行
锁升级,比如InnoDB行锁升级为表锁
- 悲观锁:比如行锁、表锁等,读锁、写锁等,都是在操作之前先上锁。java中
syschronized和ReentrantLock等独占锁都是悲观锁思想的实现。长事务,这样的开销往往无法承受- 乐观锁:不采用数据库自身的锁机制,而是通过程序来实现,在程序上,我们可以采用
版本号机制和CAS机制实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,在java中java.util.concurrent.atomic包下的原子变量类就是使用了乐观锁的一种实现方式:CAS实现
- 乐观锁的版本号机制或时间戳机制:
- 在表中设计一个版本字段CSDN-乐观锁-版本号机制
- 类似GIT、SVN版本控制工具,当我们修改了代码进行提交是,首先会检查当前版本号与服务器上的版本号是否一致,如果一致就可以直接提交,如果不一致就需要更新服务器上最新代码,然后再进行提交
注意:
select ... for update语句执行过程中所有扫描的行都会被锁上,因此MYSQL中用悲观锁必须确定使用了索引,而不是全表扫描,否则会把整个表锁住
一般情况下,新插入一条记录的操作并不加锁,通过一种称为
隐式锁的结构来保护这条新插入的记录在本事务提交前不被别的事务访问
让整个数据库实例处于只读状态,场景是:全库逻辑备份
flush tables with read lock
show status like 'innodb_row_lock';
- MySQL中支持四种隔离级别,隔离级别越高,并发性能开销通常越大——
- Read Uncommitted : 该隔离级别下的事务可以读到其他事务未提交和已提交的操作所改变的数据。
- Read Committed : 该隔离级别下的事务可以读到其他事务已提交的修改,删除,增加操作所改变的数据。
- Repeatable Read : 这是MySQL默认的隔离级别(一般不做修改)。该隔离级别下的事务可以读到启动事务时刻数据库中的数据,并且不会被其他事务所进行的DML操作所影响。
- Seralizable : 该隔离级别隔离程度最高,事务要对某数据库中的指定表进行访问时,会先判断当前表有没有其他事务正在操作,如果有,当前事务就会一直等待,直到没有其他事务操作该表时,才能访问成功,该隔离级别下读取到的数据是其他事务修改后的数据,但是由于最后已经没有其他事务操作要访问的数据,所以不会出现返回的查询结果不一致的情况。
数据库的事务隔离级别用来控制多个并发事务之间相互影响程度。SQL 标准定义了四种隔离级别,从低到高依次是:
- Read Uncommitted (读未提交):
- 这是最低的隔离级别。在该级别下,一个事务可以读取到其他事务尚未提交的数据。
- 会导致严重的并发问题——脏读 (Dirty Read)。即如果一个事务读取了另一个事务未提交的数据,而后者最终回滚,那么前一个事务读取的数据就是无效的“脏”数据。
- 并且,由于没有进行任何锁定或版本控制,Read Uncommitted 隔离级别同样也会发生不可重复读 和 幻读问题。
- Read Committed (读已提交):
- 在该级别下,一个事务只能读取到其他事务已经提交的数据,从而解决了“脏读”问题。
- 然而,在该级别下,仍然可能出现不可重复读 (Non-repeatable Read) 问题。这是指在一个事务内,多次读取同一行数据时,可能会得到不同的结果,因为其他事务在两次读取之间修改并提交了该行数据。
- 同时,Read Committed 隔离级别也会发生幻读 (Phantom Read) 问题。
- Repeatable Read (可重复读):
- 这是 MySQL InnoDB 存储引擎的默认隔离级别。
- 在该级别下,一个事务在整个执行过程中,多次读取同一行数据时,结果始终保持一致。这主要通过 MVCC (多版本并发控制) 机制来实现,事务在开始时会创建一个数据快照,后续的读取操作都基于这个快照。这有效地解决了不可重复读问题。
- 根据 SQL 标准,Repeatable Read 隔离级别是允许幻读的。然而,MySQL 的 InnoDB 存储引擎通过 Next-Key Lock(行锁和间隙锁的组合)机制,在 Repeatable Read 级别下,在一定程度上避免了幻读问题。 当执行范围查询时,InnoDB 会对查询范围内的记录及其之间的间隙加锁,阻止其他事务在该范围内插入新的记录。
- 因此,在 MySQL 中,Repeatable Read 隔离级别基本上可以避免脏读、不可重复读和幻读。
- Serializable (串行化):
- 它是最高的隔离级别。在该级别下,事务是完全隔离的,就像它们串行执行一样。
- Serializable 隔离级别通过对所有读写操作加锁来实现。当一个事务访问某个数据时,会对该数据加锁,阻止其他事务同时访问。
- 在该隔离级别下,不会出现脏读、不可重复读和幻读问题。
- 然而,由于需要进行严格的锁定,Serializable 隔离级别会显著降低数据库的并发性能,因此在实际应用中很少使用,除非对数据一致性有极高的要求。
-
MySQL四种隔离级别的分类,如下表所示:

-
脏读(Dirty Read) 示意图如下:

-
面试官可能的追问1: “你能简要解释一下脏读、不可重复读和幻读这三种并发问题吗?”
- 简答: ① 脏读是指一个事务读取到另一个事务未提交的数据; ② 不可重复读是指在一个事务内,多次读取同一行数据,结果不一致(由于其他事务的修改或删除); ③ 幻读是指在一个事务内,多次执行同一个查询,返回的行数不一致(由于其他事务的插入或删除)。
-
面试官可能的追问2: “MySQL 的 Repeatable Read 隔离级别是如何在一定程度上避免幻读的?”
- 简答: MySQL 的 InnoDB 存储引擎在 Repeatable Read 级别下,通过 Next-Key Lock 机制来解决幻读。Next-Key Lock 是行锁和间隙锁的组合,它不仅锁定查询到的记录,还会锁定记录之间的间隙,从而阻止其他事务在这些间隙中插入新的记录,避免了幻读的发生。
-
面试官可能的追问3: “你提到了 MVCC,它在 Repeatable Read 级别下有什么作用?”
- **简答:**MVCC (多版本并发控制) 是 InnoDB 在 Repeatable Read 级别下实现可重复读的关键机制。它通过保存数据的多个版本,使得事务在读取数据时可以读取到事务开始时的版本,从而保证了在事务执行期间多次读取同一行数据时结果的一致性,解决了不可重复读问题。


MYSQL8.0参考手册-MySQL Server Logs
MYSQL8.0参考手册-Backup and Recovery