
English | 简体中文 | 繁體中文 | العربية | Italiano | Українська | Español | Português | Français | Deutsch | 日本語 | 한국어 | עברית | Nederlands | Türkçe | हिंदी | Tiếng Việt | Bahasa Melayu
O QuestDB é um banco de dados de séries temporais open-source que oferece ingestão extremamente rápida e consultas SQL dinâmicas de baixa latência.
O QuestDB oferece um mecanismo de armazenamento multicamadas (WAL → nativo → Parquet em object storage), e o motor principal é implementado em Java zero-GC e C++; o QuestDB Enterprise inclui componentes adicionais em Rust.
Alcançamos alto desempenho através de um modelo de armazenamento orientado a colunas, execução vetorial paralela, instruções SIMD e técnicas de baixa latência. Além disso, o QuestDB é eficiente em hardware, com configuração rápida e eficiência operacional.
Pronto para começar? Vá para a seção Começando.
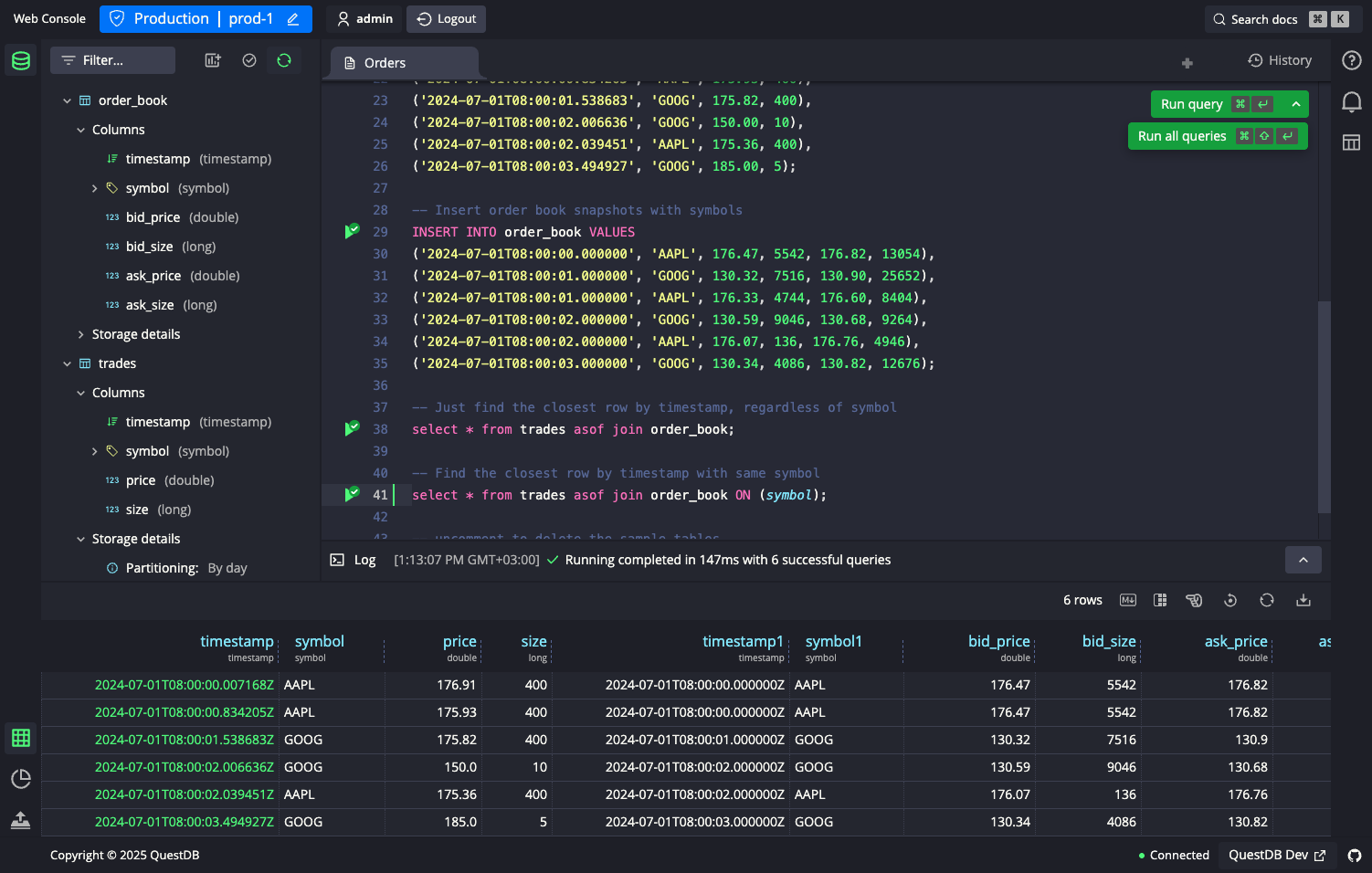
QuestDB Web Console - clique para lançar a demo
Recursos em destaque incluem:
- Ingestão de baixa latência e alto throughput — de eventos únicos a milhões/seg
- SQL de baixa latência com extensões de séries temporais (ASOF JOIN, SAMPLE BY, LATEST ON)
- Execução paralela acelerada por SIMD; executa rapidamente em hardware modesto
- Armazenamento multicamadas: WAL → colunar nativo → Parquet (particionado por tempo e ordenado por tempo)
- Protocolo Postgres (PGwire) e REST API
- Visualizações materializadas e arrays n-dimensionais (incluindo arrays 2D para order books)
- Console web para consultas e gerenciamento de dados
- Apache 2.0 open source e formatos abertos — sem vendor lock-in
- Funções financeiras e análise de order book
O QuestDB se destaca com:
- Dados de mercados financeiros (tick data, trades, order books, OHLC)
- Dados de sensor/telemetria com alta cardinalidade de dados
- Dashboards em tempo real e monitoramento
E por que usar um banco de dados de séries temporais?
Além de desempenho e eficiência, com um banco de dados de séries temporais especializado, você não precisa se preocupar com:
- Dados fora de ordem
- Deduplicação e semântica exactly-once
- Ingestão de streaming contínuo com múltiplas consultas concorrentes
- Dados de streaming (baixa latência)
- Dados voláteis e "bursty"
- Adicionar novas colunas - alterar esquema "on the fly" ao fazer streaming de dados
A demo pública ao vivo é provisionada com a versão mais recente do QuestDB e conjuntos de dados de exemplo:
- Trades: trades de crypto ao vivo com mais de 30M de linhas por mês (exchange OKX)
- FX order book: gráficos ao vivo com pares FX de order book.
- Trips: 10 anos de dados de viagens de táxi de NYC com 1.6 bilhões de linhas
Também temos alguns dashboards de demo públicos em tempo real usando nosso plugin nativo do Grafana:
- Trades de crypto em tempo real: trades executados no OKX de mais de 20 ativos em tempo real
- FX order book: gráficos de depth/imbalance ao vivo para principais pares FX
O QuestDB se sai muito bem em benchmarks de desempenho comparado a alternativas.
Para análises detalhadas sobre internos e desempenho, veja os seguintes posts do blog:
Como sempre, encorajamos você a executar seus próprios benchmarks.

Use Docker para começar rapidamente:
docker run -p 9000:9000 -p 9009:9009 -p 8812:8812 questdb/questdbOu usuários do macOS podem usar o Homebrew:
brew install questdb
brew services start questdbquestdb start
questdb stopAlternativamente, para começar a jornada completa de onboarding, comece com nosso guia de início rápido conciso.
Clientes QuestDB para ingerir dados via InfluxDB Line Protocol:
Interaja com o QuestDB e seus dados através das seguintes interfaces:
- Console Web para editor SQL interativo e importação CSV na porta
9000 - InfluxDB Line Protocol para ingestão de streaming na porta
9000 - PostgreSQL Wire Protocol para consultas programáticas na porta
8812 - REST API para importação CSV e cURL na porta
9000
Ferramentas populares que se integram com o QuestDB incluem:
Do streaming de ingestão à visualização com Grafana, comece com scaffolds de código do nosso repositório quickstart.
Encontre nosso planejamento de capacidade para ajustar o QuestDB para workloads de produção.
Para operação segura em maior escala ou dentro de organizações maiores.
Recursos adicionais incluem:
- Alta disponibilidade e réplica(s) de leitura
- Ingestão multi-primária
- Integração com cold storage
- Controle de acesso baseado em funções
- Criptografia TLS
- Consulta nativa de arquivos Parquet via object storage
- Suporte SLA, monitoramento aprimorado e muito mais
Visite a página Enterprise para mais detalhes e informações de contato.
- Documentação do QuestDB: comece a jornada
- Roadmap do produto: confira nosso plano para próximos lançamentos
- Tutoriais: aprenda o que é possível com QuestDB, passo a passo
- Fórum Discourse da comunidade: participe de discussões técnicas, faça perguntas e conheça outros usuários!
- Slack público: converse com a equipe QuestDB e membros da comunidade
- Issues do GitHub: reporte bugs ou problemas com QuestDB
- Stack Overflow: procure soluções comuns de solução de problemas
Contribuições são bem-vindas!
Valorizamos:
- Código fonte
- Documentação (veja nosso repositório de documentação)
- Relatórios de bug
- Solicitações de recursos ou feedback
Para começar a contribuir:
- Confira issues do GitHub marcados como "Good first issue"
- Para Hacktoberfest, veja issues marcados relevantes
- Leia o guia de contribuição
- Para detalhes sobre construir QuestDB, veja as instruções de construção
- Crie um fork do QuestDB e envie um pull request com suas mudanças propostas
- Ficou empacado? Junte-se ao nosso Slack público para ajuda
✨ Como sinal de nossa gratidão, enviamos swag QuestDB para nossos contribuidores!
Muito obrigado às seguintes pessoas maravilhosas que contribuíram para o QuestDB chave emoji:












































































































Este projeto segue a especificação all-contributors. Contribuições de qualquer tipo são bem-vindas!