From fce4546c67799f27b5f96ce53b2bf9bc20b2b6cb Mon Sep 17 00:00:00 2001
From: =?UTF-8?q?Micha=C5=82=20Olender?=
<92638966+TC-MO@users.noreply.github.com>
Date: Sun, 19 Apr 2026 12:45:49 +0200
Subject: [PATCH] docs: replace external image URLs with local assets in
Academy scraper tutorials
Switch 17 image references from raw.githubusercontent.com to local
./images/ paths across 4 tutorial pages (getting_started, web_scraper,
cheerio_scraper, puppeteer_scraper). Also replace placeholder "$1" alt
text with descriptive alternatives for accessibility.
---
.../tutorials/apify_scrapers/cheerio_scraper.md | 12 ++++++------
.../tutorials/apify_scrapers/getting_started.md | 6 +++---
.../tutorials/apify_scrapers/puppeteer_scraper.md | 10 +++++-----
.../academy/tutorials/apify_scrapers/web_scraper.md | 10 +++++-----
4 files changed, 19 insertions(+), 19 deletions(-)
diff --git a/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md b/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
index 586a835b40..8a0278dc7a 100644
--- a/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/cheerio_scraper.md
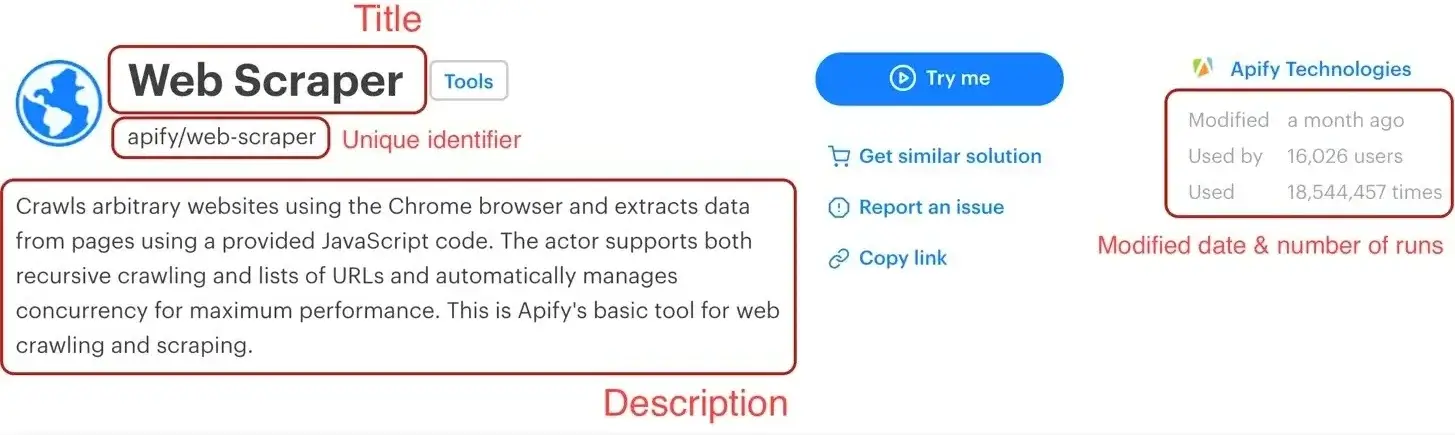
@@ -47,14 +47,14 @@ Before we start, let's do a quick recap of the data we chose to scrape:
5. **Last modification date** - When the Actor was last modified.
6. **Number of runs** - How many times the Actor was run.
-
+
We've already scraped numbers 1 and 2 in the [Getting started with Apify scrapers](/academy/apify-scrapers/getting-started)
tutorial, so let's get to the next one on the list: title.
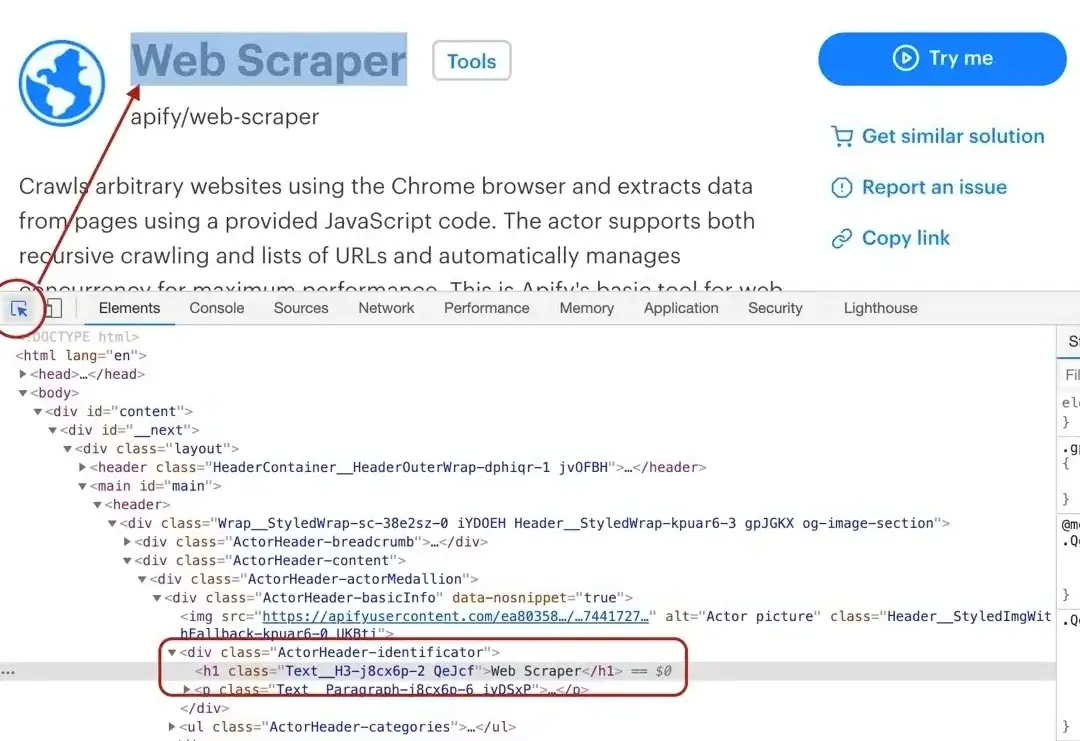
### Title
-
+
By using the element selector tool, we find out that the title is there under an `` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `` tags on the detail page. This should get us thinking.
@@ -84,7 +84,7 @@ async function pageFunction(context) {
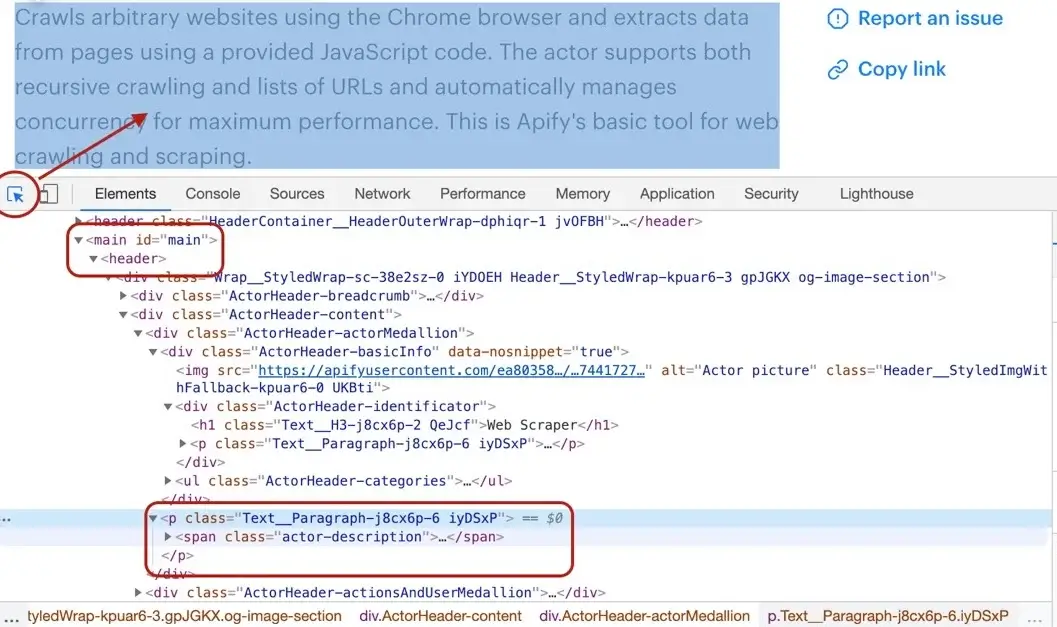
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `
` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `` element too, same as the title. Moreover, the actual description is nested inside a `` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
@@ -275,7 +275,7 @@ the Network tab of the Chrome DevTools.
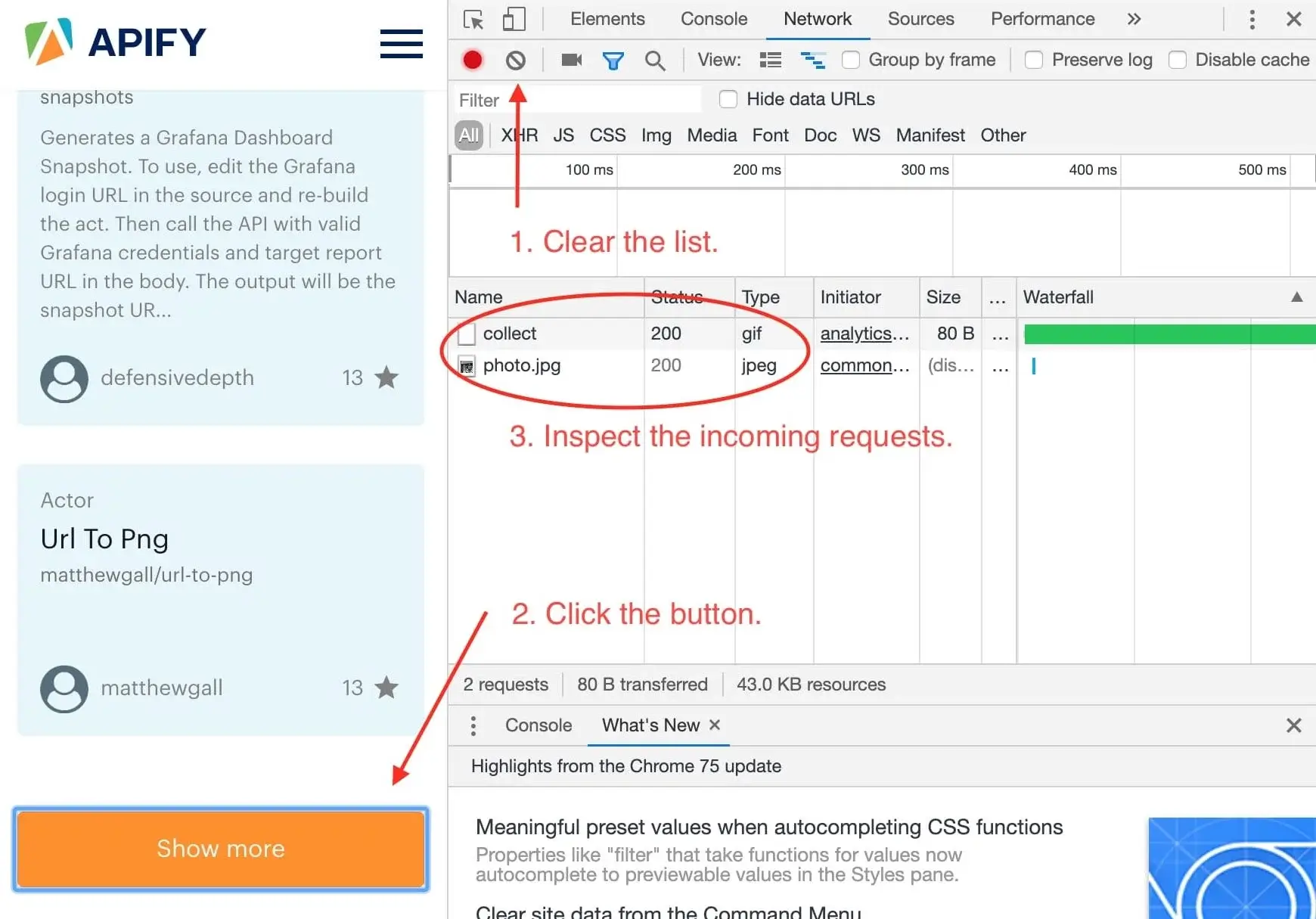
We want to know what happens when we click the **Show more** button, so we open the DevTools **Network** tab and clear it.
Then we click the **Show more** button and wait for incoming requests to appear in the list.
-
+
Now, this is interesting. It seems that we've only received two images after clicking the button and no additional
data. This means that the data about Actors must already be available in the page and the **Show more** button only displays it. This is good news.
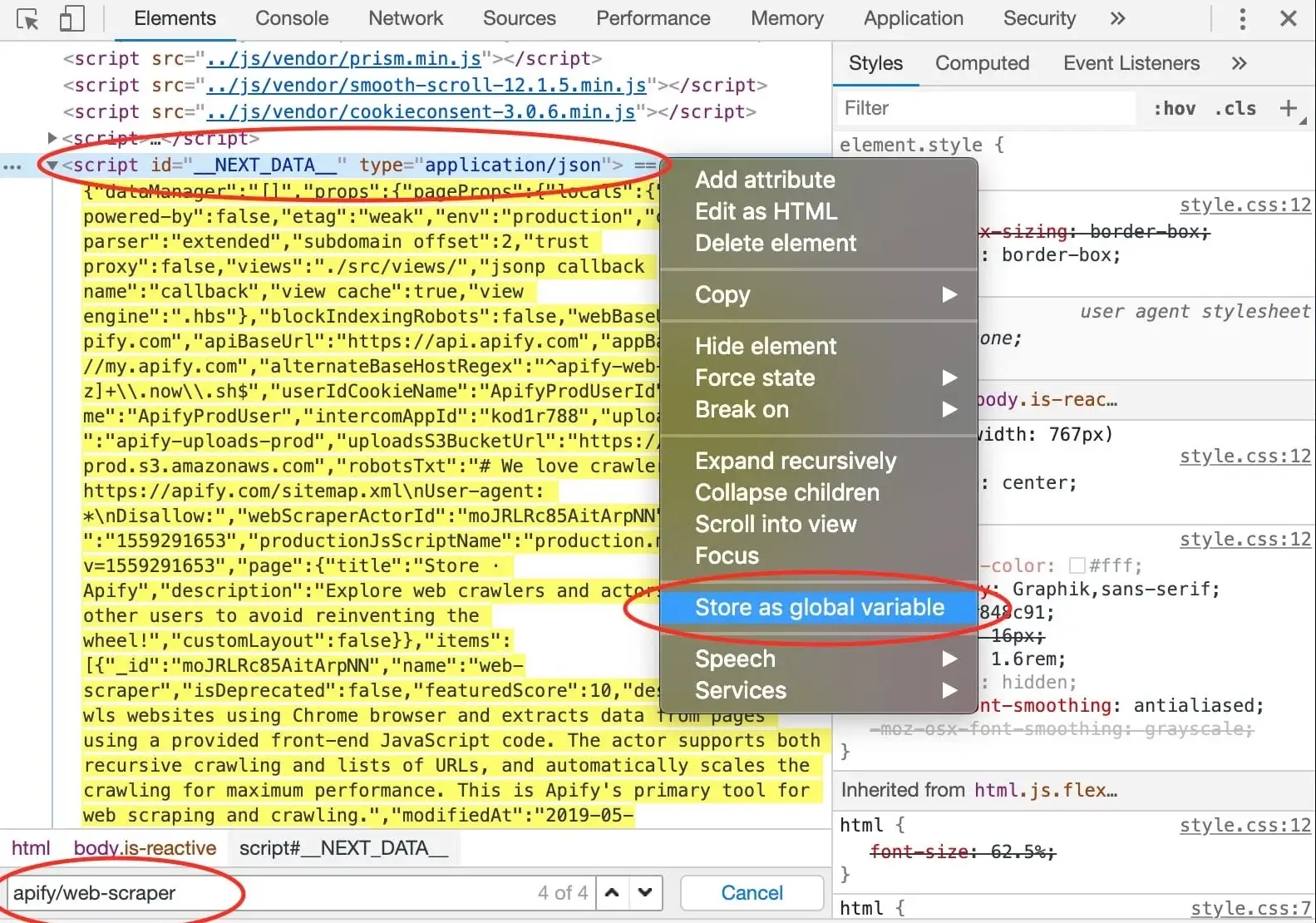
@@ -288,7 +288,7 @@ few hits do not provide any interesting information, but in the end, we find our
with the ID `__NEXT_DATA__` that seems to hold a lot of information about Web Scraper. In DevTools,
you can right click an element and click **Store as global variable** to make this element available in the **Console**.
-
+
A `temp1` variable is now added to your console. We're mostly interested in its contents and we can get that using
the `temp1.textContent` property. You can see that it's a rather large JSON string. How do we know?
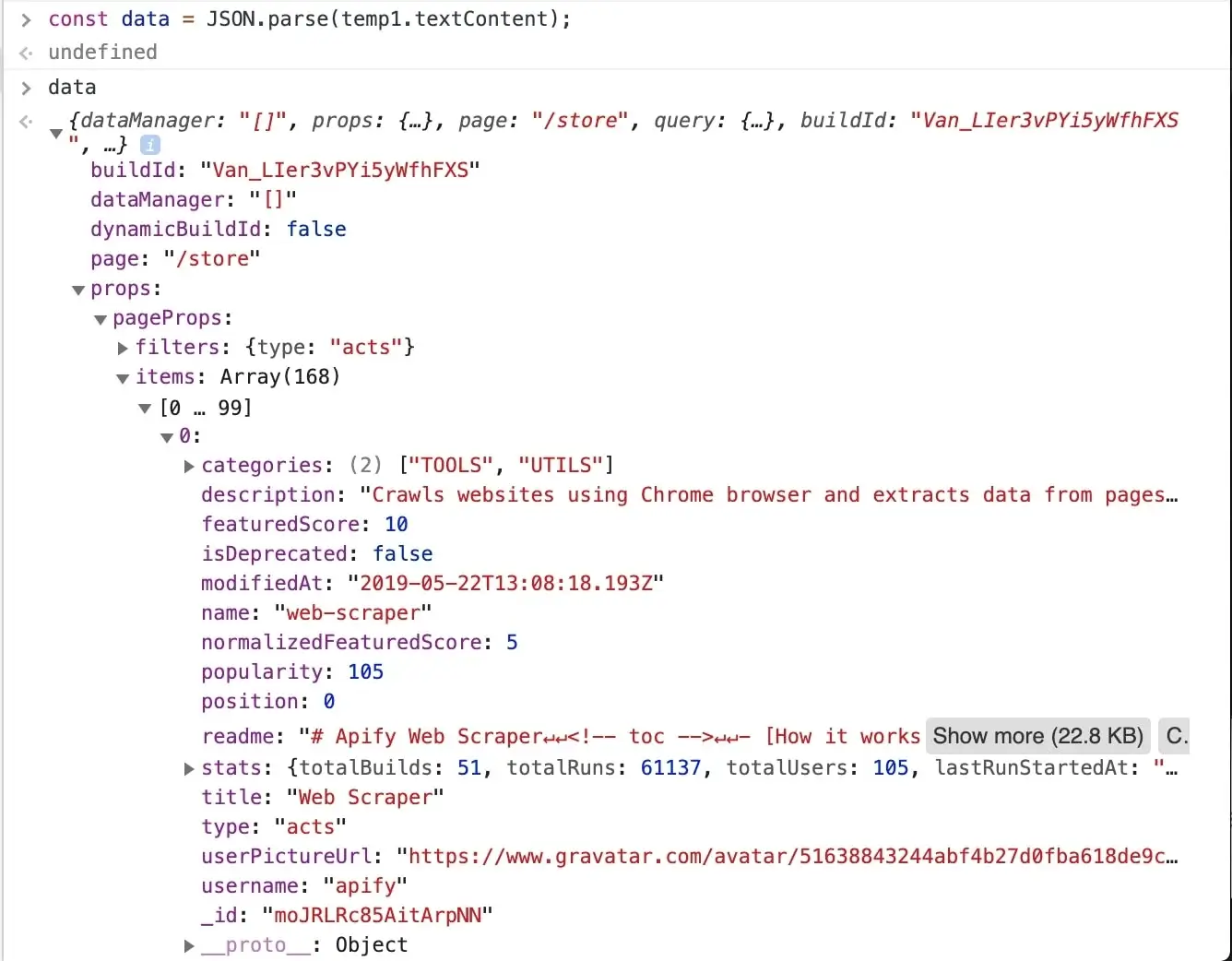
@@ -302,7 +302,7 @@ const data = JSON.parse(temp1.textContent);
After entering the above command into the console, we can inspect the `data` variable and see that all the information
we need is there, in the `data.props.pageProps.items` array. Great!
-
+
> It's obvious that all the information we set to scrape is available in this one data object,
so you might already be wondering, can I make one request to the store to get this JSON
diff --git a/sources/academy/tutorials/apify_scrapers/getting_started.md b/sources/academy/tutorials/apify_scrapers/getting_started.md
index 9b05130eba..1e776fd505 100644
--- a/sources/academy/tutorials/apify_scrapers/getting_started.md
+++ b/sources/academy/tutorials/apify_scrapers/getting_started.md
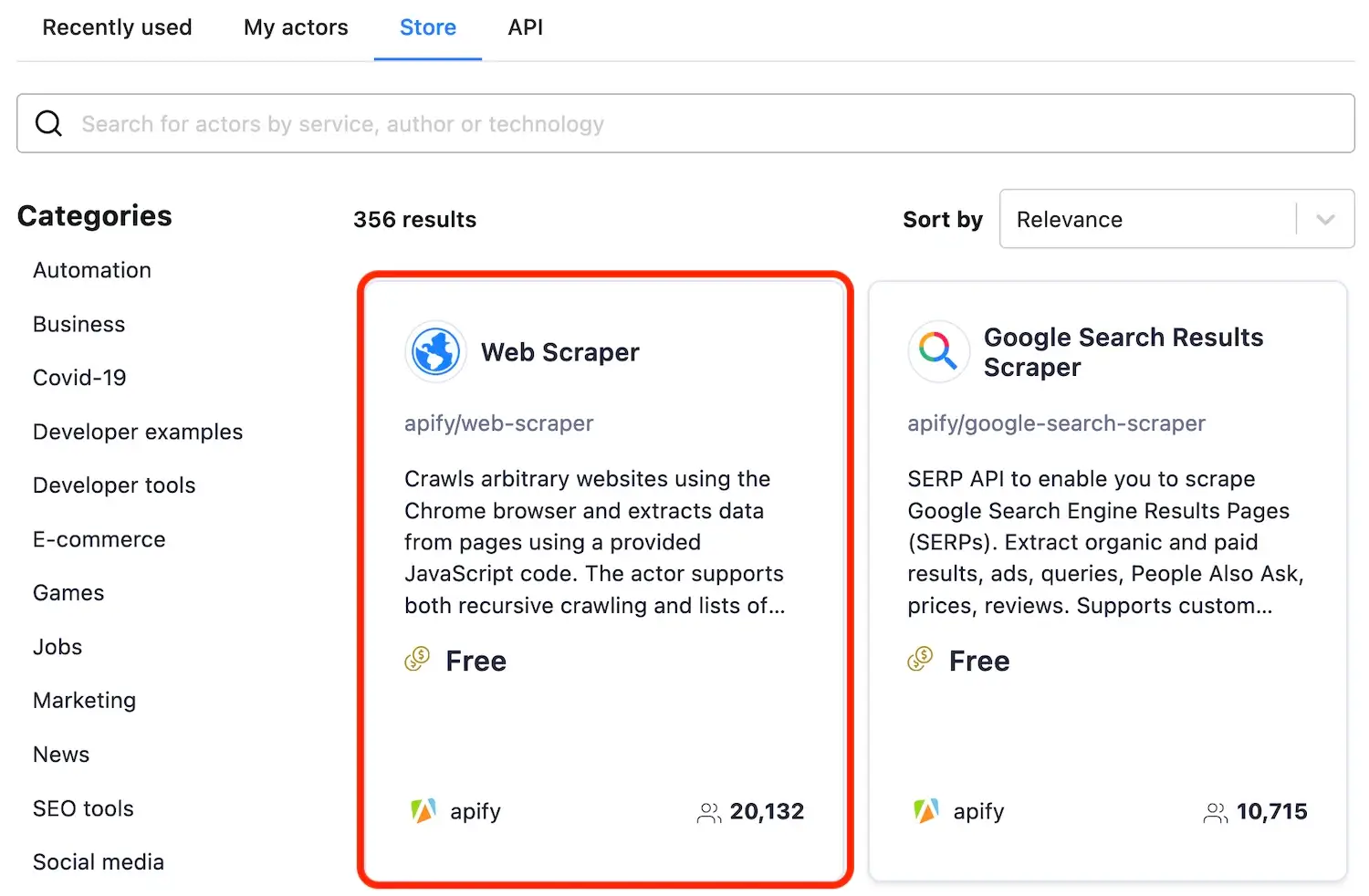
@@ -27,7 +27,7 @@ Depending on how you arrived at this tutorial, you may already have your first t
> This tutorial covers the use of **Web**, **Cheerio**, and **Puppeteer** scrapers, but a lot of the information here can be used with all Actors. For this tutorial, we will select **Web Scraper**.
-
+
### Running a task
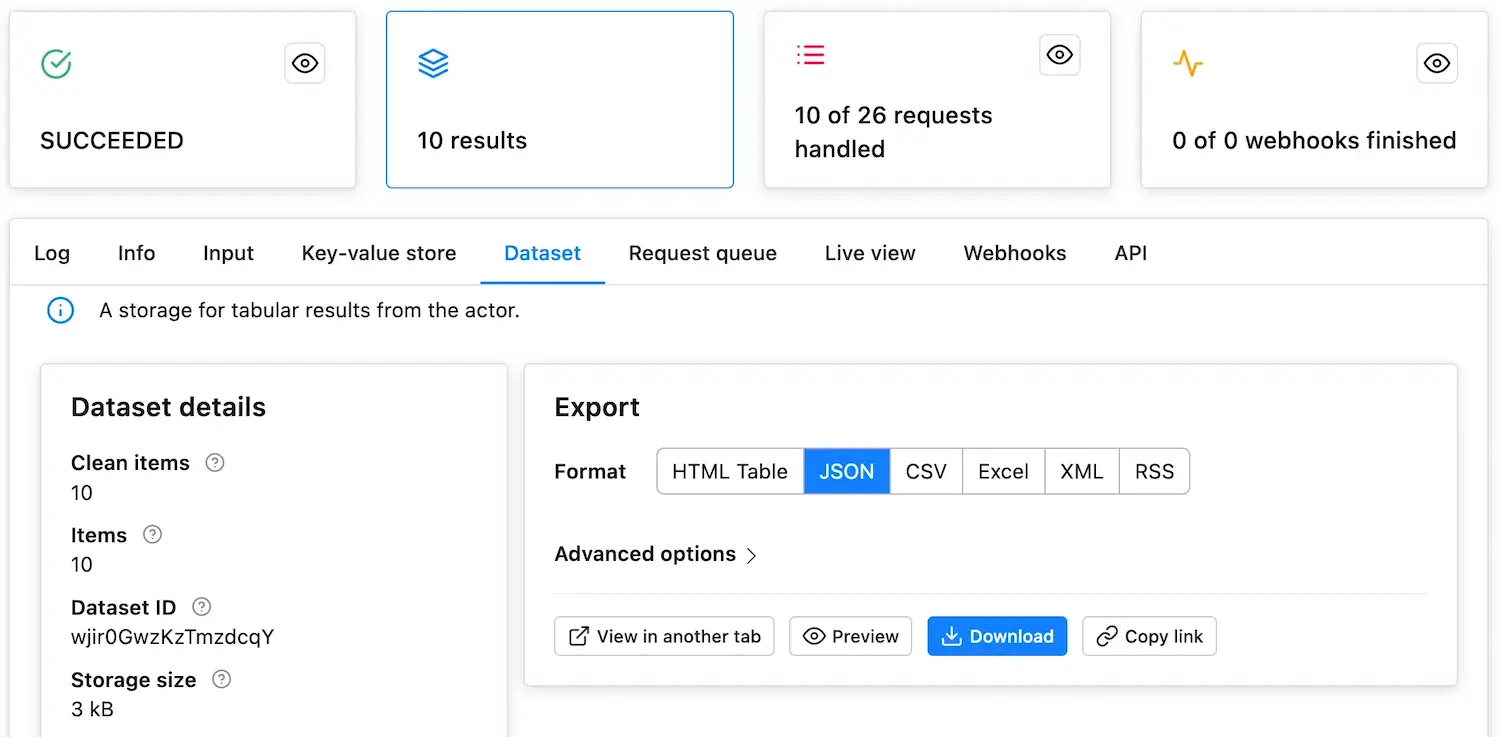
@@ -47,7 +47,7 @@ After clicking **Save & Run**, the window will change to the run detail. Here, y
Now that the run has `SUCCEEDED`, click on the glowing **Results** card to see the scrape's results. This takes you to the **Dataset** tab, where you can display or download the results in various formats. For now, click the **Preview** button. Voila, the scraped data!
-
+
Good job! We've run our first task and got some results. Let's learn how to change the default configuration to scrape something more interesting than the page's ``.
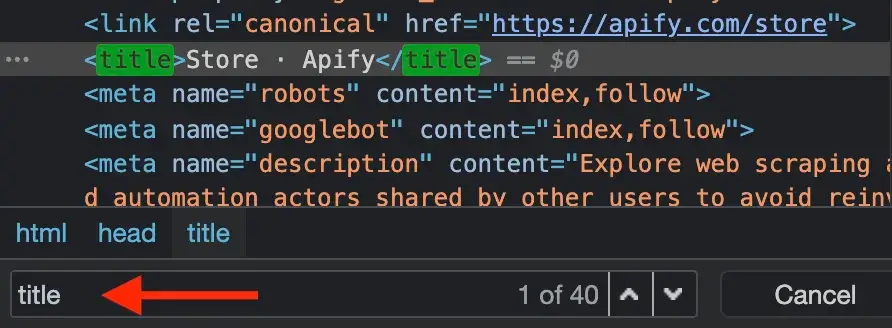
@@ -204,7 +204,7 @@ The DevTools window will pop up and display a lot of, perhaps unfamiliar, inform
You'll see that the Element tab jumps to the first `<title>` element of the current page and that the title is **Store · Apify**. It's always good practice to do your research using the DevTools before writing the `pageFunction` and running your task.
-
+
> For the sake of brevity, we won't go into the details of using the DevTools in this tutorial. If you're just starting out with DevTools, this [Google tutorial](https://developer.chrome.com/docs/devtools/) is a good place to begin.
diff --git a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
index 130713691a..cad4608b97 100644
--- a/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/puppeteer_scraper.md
@@ -62,14 +62,14 @@ Before we start, let's do a quick recap of the data we chose to scrape:
5. **Last modification date** - When the Actor was last modified.
6. **Number of runs** - How many times the Actor was run.
-
+
We've already scraped numbers 1 and 2 in the [Getting started with Apify scrapers](/academy/apify-scrapers/getting-started)
tutorial, so let's get to the next one on the list: title.
### Title
-
+
By using the element selector tool, we find out that the title is there under an `<h1>` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `<h1>` tags on the detail page. This should get us thinking.
@@ -108,7 +108,7 @@ is automatically passed back to the Node.js context, so we receive an actual `st
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `<p>` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `<header>` element too, same as the title. Moreover, the actual description is nested inside a `<span>` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
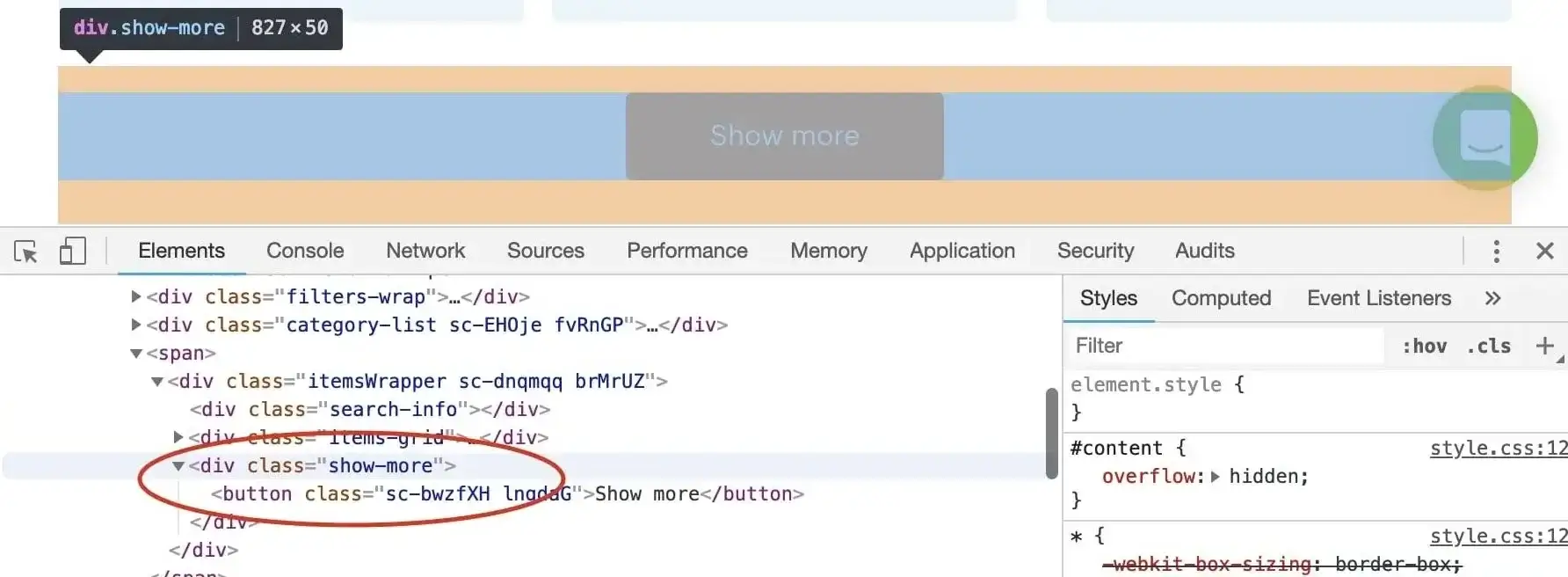
@@ -426,7 +426,7 @@ div.show-more > button
> Don't forget to confirm our assumption in the DevTools finder tool (CTRL/CMD + F).
-
+
Now that we know what to wait for, we plug it into the `waitFor()` function.
@@ -579,7 +579,7 @@ through all the Actors and then scrape all of their data. After it succeeds, ope
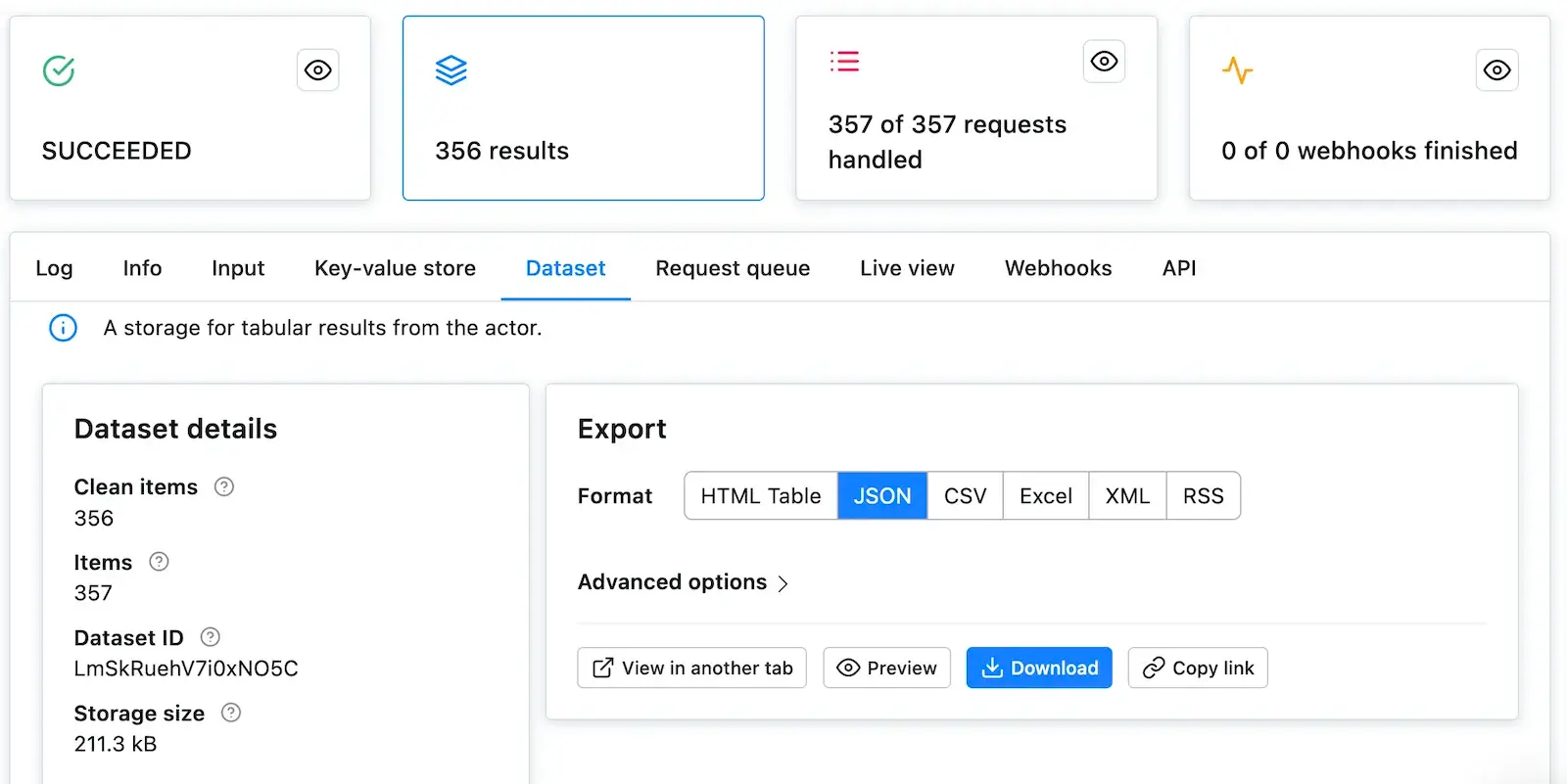
You've successfully scraped Apify Store. And if not, no worries, go through the code examples again,
it's probably just a typo.
-
+
## Downloading the scraped data
diff --git a/sources/academy/tutorials/apify_scrapers/web_scraper.md b/sources/academy/tutorials/apify_scrapers/web_scraper.md
index 3b468e198f..6618d5d4dd 100644
--- a/sources/academy/tutorials/apify_scrapers/web_scraper.md
+++ b/sources/academy/tutorials/apify_scrapers/web_scraper.md
@@ -45,14 +45,14 @@ Before we start, let's do a quick recap of the data we chose to scrape:
5. **Last modification date** - When the Actor was last modified.
6. **Number of runs** - How many times the Actor was run.
-
+
We've already scraped numbers 1 and 2 in the [Getting started with Apify scrapers](/academy/apify-scrapers/getting-started)
tutorial, so let's get to the next one on the list: title.
### Title
-
+
By using the element selector tool, we find out that the title is there under an `<h1>` tag, as titles should be.
Maybe surprisingly, we find that there are actually two `<h1>` tags on the detail page. This should get us thinking.
@@ -83,7 +83,7 @@ async function pageFunction(context) {
Getting the Actor's description is a little more involved, but still pretty straightforward. We cannot search for a `<p>` tag, because there's a lot of them in the page. We need to narrow our search down a little. Using the DevTools we find that the Actor description is nested within
the `<header>` element too, same as the title. Moreover, the actual description is nested inside a `<span>` tag with a class `actor-description`.
-
+
```js
async function pageFunction(context) {
@@ -322,7 +322,7 @@ div.show-more > button
> Don't forget to confirm our assumption in the DevTools finder tool (CTRL/CMD + F).
-
+
Now that we know what to wait for, we plug it into the `waitFor()` function.
@@ -455,7 +455,7 @@ through all the Actors and then scrape all of their data. After it succeeds, ope
You've successfully scraped Apify Store. And if not, no worries, go through the code examples again,
it's probably just a typo.
-
+
## Downloading the scraped data