forked from cis-ds/course-site
-
Notifications
You must be signed in to change notification settings - Fork 0
Expand file tree
/
Copy pathblock013_rmarkdown.Rmd
More file actions
449 lines (306 loc) · 24.1 KB
/
block013_rmarkdown.Rmd
File metadata and controls
449 lines (306 loc) · 24.1 KB
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
---
title: "R Markdown"
output:
html_document:
toc: true
toc_float: true
---
```{r setup, include = FALSE}
knitr::opts_chunk$set(cache = TRUE)
chunk <- "```"
inline <- function(x = "") paste0("`` `r ", x, "` ``")
```
# Objectives
* Review the importance of reproducibility in scientific research
* Identify the major components of R Markdown documents
* Explain how to use chunk options to customize output
* Demonstrate the value of caching
* Explain how to include in-line R code
* Introduce the different R Markdown document formats
* Practice writing R scripts (`.R`) versus R Markdown documents (`.Rmd`)
```{r packages, cache = FALSE, message = FALSE}
library(tidyverse)
library(rcfss)
set.seed(1234)
```
# Reproducibility in scientific research

**Reproducibility** is "the idea that data analyses, and more generally, scientific claims, are published with their data and software code so that others may verify the findings and build upon them."^[[Coursera: Reproducible Research](https://www.coursera.org/learn/reproducible-research)] Scholars who implement reproducibility in their projects can quickly and easily reproduce the original results and trace back to determine how they were derived. This easily enables verification and replication, and allows the researcher to precisely replicate his or her analysis. This is extremely important when writing a paper, submiting it to a journal, then coming back months later for a revise and resubmit because you won't remember how all the code/analysis works together when completing your revisions.
Reproducibility is also key for communicating findings with other researchers and decision makers; it allows them to verify your results, assess your assumptions, and understand how your answers were formed rather than solely relying on your claims. In the data science framework employed in [R for Data Science](http://r4ds.had.co.nz), reproducibility is infused throughout the entire workflow.
[R Markdown](http://rmarkdown.rstudio.com/) is one approach to ensuring reproducibility by providing a single cohesive authoring framework. It allows you to combine code, output, and analysis into a single document, are easily reproducible, and can be output to many different file formats. R Markdown is just one tool for enabling reproducibility. Another tool is [Git](https://git-scm.com/) for **version control**, which is crucial for collaboration and tracking changes to code and analysis.
### Jupyter Notebooks
In the data science realm, another popular unified authoring framework is the [Jupyter Notebook](http://jupyter.org/). The Jupyter Notebook (originally called *iPython Notebook*) is a web application that incorporates text, code, and output into a single document. Originally created for the Python programming language, Jupyter Notebooks are now multi-language and support over 40 programming languages, including R. You have probably seen or used them before. There is nothing wrong with Jupyter Notebooks, but I prefer R Markdown because it is integrated into RStudio, arguably the best integrated development environment (IDE) for R. Furthermore, as you will see an R Markdown file is a **plain-text file**. This means the content of the file can be read by any text-editor, and is easily tracked by Git. Jupyter Notebooks are stored as JSON documents, a different and more complex file format. JSON is a useful format as we will see when we get to our modules on obtaining data from the web, but they are also much more difficult to track for revisions using Git. For this reason, in this course we will exclusively use R Markdown for reproducible documents.
# R Markdown basics
An R Markdown file is a plain text file that uses the extension `.Rmd`:
```{r echo = FALSE, comment = ""}
cat(htmltools::includeText("extras/gun-deaths.Rmd"))
```
R Markdown documents contain 3 major components:
1. A **YAML header** surrounded by `---`s
1. **Chunks** of R code surounded by ` ``` `
1. Text mixed with simple text formatting using the [Markdown syntax](hw01_edit-README.html)
Code chunks are interspersed with text throughout the document. To complete the document, you "Knit" or "render" the document. Most of you proably knit the document by clicking the "Knit" button in the script editor panel. You can also do this programmatically from the console by running the command `rmarkdown::render("example.Rmd")`.
When you **knit** the document you send your `.Rmd` file to `knitr`, a package for R that executes all the code chunks and creates a second **markdown** document (`.md`). That markdown document is then passed onto [**pandoc**](http://pandoc.org/), a document rendering software program independent from R. Pandoc allows users to convert back and forth between many different document formats such as HTML, $\LaTeX$, Microsoft Word, etc. By splitting the workflow up, you can convert your R Markdown document into a wide range of output formats.

## Text formatting with Markdown
[We have previously practice formatting text using the Markdown syntax.](hw01_edit-README.html) I will not go into it further, but do note that there is a quick reference guide to Markdown built-in to RStudio. To access it, go to **Help** > **Markdown Quick Reference**.
### Exercise
Copy and paste the contents of `gun-deaths.Rmd` (the file demonstrated above) and save it in a local R Markdown document. Check that you can run it, then add text after the frequency polygon that describes its most striking features.
## Code chunks
**Code chunks** are where you store R code that will be executed. You can name a code chunk using the syntax ` ```{r name-here} `. Naming chunks is a good practice to get into for several reasons. First, it makes navigating an R Markdown document using the drop-down code navigator in the bottom-left of the script editor easier since your chunks will have *intuitive* names. Secondly, it generates meaningful file names for any graphs created within the chunk, rather than unhelpful names such as `unnamed-chunk-1.png`. Finally, once you start **caching** your results (more on that below), using consistent names for chunks avoids having to repeat computationally intensive calculations.
### Customizing chunks
Code chunks can be customized to adjust the output of the chunk. Some important and useful options are:
* `eval = FALSE` - prevents code from being evaluated. I use this in my notes for class when I want to show how to write a specific function but don't need to actually use it.
* `include = FALSE` - runs the code but doesn't show the code or results in the final document. This is useful when you have setup code at the beginning of your document (loading packages, adjusting options, etc.) that may generate a lot of messages that are not really necessary to include in the final report.
* `echo = FALSE` - prevents code from showing in the final output, but does show the results of the code. Use this if you are writing a paper or document for someone who cares more about the substantive results and less about the programming used to obtain them.
* `message = FALSE` or `warning = FALSE` - prevents messages or warnings from appearing in the final document.
* `results = 'hide'` - hides printed output.
* `error = TRUE` - causes the document to continue knitting and rendering even if the code generates a fatal error. I use this a lot when I want to [intentionally demonstrate an error in class](block012_debugging.html#fatal_errors). If you're debugging your code, you might want to use this option. However for the final version of your document, you probably do not want to allow errors to pass through unnoticed.
### Caching
Remember the R Markdown workflow?

By default, every time you knit a document R starts completely fresh. None of the previous results are saved. If you have code chunks that run computationally intensive tasks, you might want to store these results. If you use `cache = TRUE`, R will do exactly this. The output of the chunk will be saved to a specially named file on disk. If your `.gitignore` file is setup correctly, this cached file will not be tracked by Git. This is in fact preferable since the cached file could be hundreds of megabytes in size. Now, every time you knit the document the cached results will be used instead of running the code fresh.
#### Dependencies
This could be problematic when chunks rely on the output of previous chunks. Take this example from [R for Data Science](http://r4ds.had.co.nz/r-markdown.html#caching)
`r chunk`{r raw_data}
rawdata <- readr::read_csv("a_very_large_file.csv")
`r chunk`
`r chunk`{r processed_data, cache = TRUE}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
`r chunk`
`processed_data` relies on the `rawdata` file created in the `raw_data` chunk. If you change your code in `raw_data`, `processed_data` will continue to rely on the older cached results. This means even if `rawdata` is altered, the cached results will continue to erroneously be used. To prevent this, use the `dependson` option to declare any chunks the cached chunk relies upon:
`r chunk`{r processed_data, cache = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
`r chunk`
Now if the code in the `raw_data` chunk is changed, `processed_data` will be run and the cache updated.
### Global options
Rather than setting these options for each individual chunk, you can make them the default options for **all chunks** by using `knitr::opts_chunk$set()`. Just include this in a code chunk (typically in the first code chunk in the document). So for example,
```r
knitr::opts_chunk$set(
echo = FALSE
)
```
hides the code by default in all code chunks. To override this new default, you can still declare `echo = TRUE` for individual chunks.
### Inline code
Until now, you have only run code in a specially designated chunk. However you can also run R code **in-line** by using the `r inline()` syntax. For example, look at the text from the example document earlier:
```{r youth, include = FALSE}
youth <- gun_deaths %>%
filter(age <= 65)
```
> We have data about `r inline("nrow(gun_deaths)")` individuals killed by guns. Only `r inline("nrow(gun_deaths) - nrow(youth)")` are older than 65. The distribution of the remainder is shown below:
When you knit the document, the R code is executed:
> We have data about `r nrow(gun_deaths)` individuals killed by guns. Only `r nrow(gun_deaths) - nrow(youth)` are older than 65. The distribution of the remainder is shown below:
### Exercise: practice chunk options
Add a section that explores how gun deaths vary by race.
1. Assume you're writing a report for someone who doesn't know R, and instead of setting `echo = FALSE` on each chunk, set a global option.
1. Enable caching as a global option and render the document. Look at the file structure for the cache. Now render the document again. Does it run faster? Modify some code in one of the chunks? What happens now?
1. Test out some of the other chunk options. Which do you find most useful? In what context would you use them?
## YAML header
**Y**et **A**nother **M**arkup **L**anguage, or **YAML** (rhymes with *camel*) is a standardized format for storing hierarchical data in a human-readable syntax. The YAML header controls how `rmarkdown` renders your `.Rmd` file. A YAML header is a section of `key: value` pairs surrounded by `---` marks.
```
---
title: "Gun deaths"
author: "Benjamin Soltoff"
date: 2017-02-01
output: html_document
---
```
The most important option is `output`, as this determines the final document format. However there are other common options such as providing a `title` and `author` for your document and specifying the `date` of publication.
# Output formats
## HTML document
For your homework assignments, we have used `github_document` to generate a [Markdown document](http://rmarkdown.rstudio.com/markdown_document_format.html). However there are other document formats that are more commonly used.
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output: html_document
---
```
[`output: html_document`](http://rmarkdown.rstudio.com/html_document_format.html) produces an HTML document. The nice feature of this document is that all images are embedded in the HTML file itself, so you can email just the `.html` file to someone and they will be able to open and read it.
### Table of contents
Each output format has various options to customize the appearance of the final document. One option for HTML documents is to add a table of contents through the `toc` option. To add any option for an output format, just add it in a hierarchical format like this:
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
html_document:
toc: true
toc_depth: 2
```
You can explicitly set the number of levels included in the table of contents with `toc_depth` (the default is 3).
### Appearance and style
There are several options that control the visual appearance of HTML documents.
* `theme` specifies the Bootstrap theme to use for the page (themes are drawn from the [Bootswatch](http://bootswatch.com/) theme library). Valid themes include `"default"`, `"cerulean"`, `"journal"`, `"flatly"`, `"readable"`, `"spacelab"`, `"united"`, `"cosmo"`, `"lumen"`, `"paper"`, `"sandstone"`, `"simplex"`, and `"yeti"`.
* `highlight` specifies the syntax highlighting style for code chunks. Supported styles include `"default"`, `"tango"`, `"pygments"`, `"kate"`, `"monochrome"`, `"espresso"`, `"zenburn"`, `"haddock"`, and `"textmate"`.
> [This course site](http://cfss.uchicago.edu) uses the [R Markdown Websites](http://rmarkdown.rstudio.com/rmarkdown_websites.html) format to render multiple `.Rmd` documents in a single website. It uses the `readable` theme and `pygments` highlighting.
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
html_document:
theme: readable
highlight: pygments
---
```
### Code folding
Sometimes when knitting an R Markdown document you want to include your R source code (`echo = TRUE`) but you may want to include it but not make it visible by default. The `code_folding: hide` options allows you to include your R code but hide it. Users can then decide whether or not they want to see specific chunks or all chunks in the document. This strikes a good balance between readability and reproducibility.
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
html_document:
code_folding: hide
---
```
### Keeping Markdown
When `knitr` processes your `.Rmd` document, it creates a Markdown (`.md`) file that is subsequently deleted. If you want to keep a copy of the Markdown file use the `keep_md` option:
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
html_document:
keep_md: true
---
```
### Exercise: test HTML options
Use the `gun-deaths.Rmd` file you saved on your computer and test some of the document options outlined above. There are far more customization options than I outlined above. Read the [help file for HTML documents](http://rmarkdown.rstudio.com/html_document_format.html) to learn about more of the available options.
## PDF document
[`pdf_document`](http://rmarkdown.rstudio.com/pdf_document_format.html) converts the `.Rmd` file to a $\LaTeX$ file which is used to generate a PDF.
```
---
title: "Gun deaths"
date: 2017-02-01
output: pdf_document
---
```
You do need to have a full installation of TeX on your computer to generate PDF output. However the nice thing is that because it uses the $\LaTeX$ rendering engine, you can use raw $\LaTeX$ code in your `.Rmd` file (if you know how to use it).
### Table of contents
Many options for HTML documents also work for PDFs. For instance, you create a table of contents the same way:
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
pdf_document:
toc: true
toc_depth: 2
```
### Syntax highlighting
You cannot customize the `theme` of a `pdf_document` (at least not in the same way as HTML files), but you can still customize the syntax highlighting.
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
pdf_document:
highlight: pygments
---
```
### $\LaTeX$ options
You can also directly control options in the $\LaTeX$ template itself via the YAML options. Note that these options are passed as top-level YAML metadata, not underneath the `output` section:
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output: pdf_document
fontsize: 11pt
geometry: margin=1in
---
```
### Keep intermediate TeX
R Markdown documents are converted first to a `.tex` file, and then use the $\LaTeX$ engine to convert to PDF. To keep the `.tex` file, use the `keep_tex` option:
```
---
title: "Untitled"
author: "Benjamin Soltoff"
date: "February 1, 2017"
output:
pdf_document:
keep_tex: true
---
```
### Exercise: test PDF options
Use the `gun-deaths.Rmd` file you saved on your computer and test some of the PDF document options outlined above. Be sure to first change the output format to `pdf_document`. There are far more customization options than I outlined above. Read the [help file for PDF documents](http://rmarkdown.rstudio.com/pdf_document_format.html) to learn about more of the available options.
## Presentations
You can use R Markdown not only to generate full documents, but also slide presentations. There are four major presentation formats:
* [ioslides](http://rmarkdown.rstudio.com/ioslides_presentation_format.html) - HTML presentation with ioslides
* [reveal.js](http://rmarkdown.rstudio.com/revealjs_presentation_format.html) - HTML presentation with reveal.js
* [Slidy](http://rmarkdown.rstudio.com/slidy_presentation_format.html) - HTML presentation with W3C Slidy
* [Beamer](http://rmarkdown.rstudio.com/beamer_presentation_format.html) - PDF presentation with $\LaTeX$ Beamer
Each as their own strengths and weaknesses. ioslides and Slidy are probably the easiest to use initially, but are more difficult to customize. reveal.js is more complex, but allows for more customization (this is the format I use for my slides in this class). Beamer is the only presentation format that creates a PDF document and is probably a smoother transition for those already used to Beamer.
### Exercise: build a presentation
Choose one of the presentation formats and convert `gun-deaths.Rmd` into a slide presentation. Save this new document as `gun-deaths-slides.Rmd`. Test out some of the associated options for your chosen presentation format.
## Multiple formats
You can even render your document into multiple output formats by supplying a list of formats:
```
output:
html_document:
toc: true
toc_float: true
pdf_document: default
```
If you don't want to change any of the default options for a format, use the `default` option. You cannot specify multiple formats like this:
```
output:
html_document:
toc: true
toc_float: true
pdf_document
```
You **must** assign some value to the second output format, hence the use of `default`.
### Rendering multiple outputs programmatically
When rendering multiple output formats, you cannot just click the "Knit" button. Doing so will only render the first output format listed in the YAML. To render all output formats, you need to programmatically render the document using `rmarkdown::render("my-document.Rmd", output_format = "all")`. Type `?render` in the console to look up the help file for `render()` and see the different arguments the function can accept.
### Exercise: render in multiple formats
Render `gun-deaths.Rmd` as both an HTML document and a PDF document. If you do not have $\LaTeX$ installed on your computer, render `gun-deaths.Rmd` as both an HTML document and a [Word document](http://rmarkdown.rstudio.com/word_document_format.html). And at some point [install $\LaTeX$ on your computer](https://www.latex-project.org/get/) so you can create PDF documents.
# R scripts
So far we've done a lot of our work in R Markdown documents, knitting together code chunks, output, and Markdown text. However we don't have to use R Markdown documents for all our work. In many instances, using a **script** might be preferable.
## What is a script?
A script is a plain-text file with a `.R` file extension. It contains R code. You can add comments using the `#` symbol. For example, `gun-deaths.R` would look something like this:
```{r echo = FALSE, comment = ""}
cat(htmltools::includeText("extras/gun-deaths.R"))
```
You edit scripts in the editor panel in R Studio.
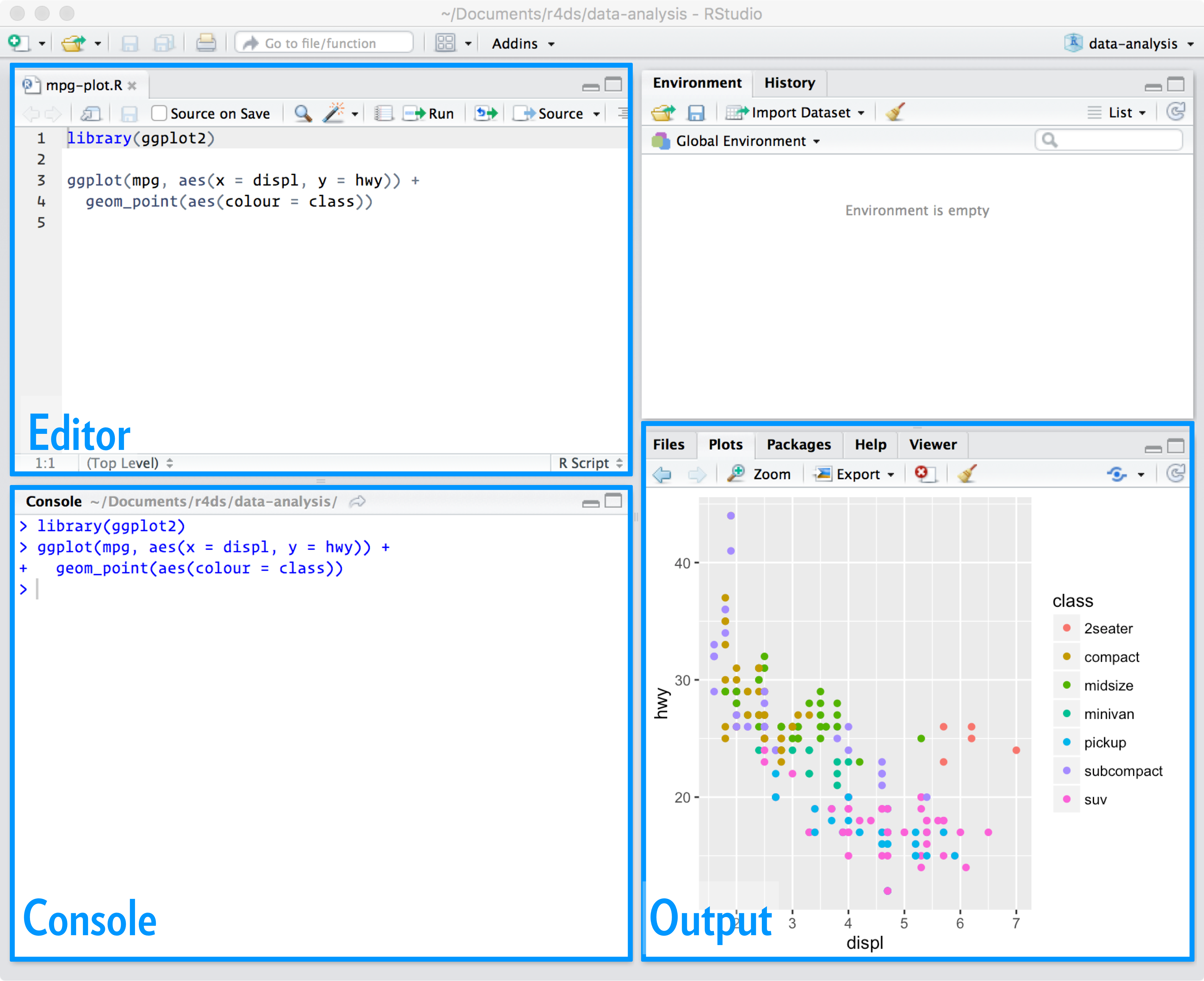
## When to use a script?
[Scripts are much easier to troubleshoot than R Markdown documents](http://r4ds.had.co.nz/r-markdown.html#troubleshooting) because your code is not split across chunks and you can run everything interactively. When you first begin a project, you may find it useful to use scripts initially to build and debug code, then convert it to an R Markdown document once you begin the substantive analysis and writeup. Or you may use a mix of scripts and R Markdown documents depending on the size and complexity of your project. For instance, you could use a **reproducible pipeline** which uses a sequence of R scripts to download, import, and transform your data, then use an R Markdown document to produce a final report.
> Check out [this example](https://github.com/uc-cfss/pipeline-example) for how one could use a pipeline in this fashion.
In this class while the final product is generally submitted as an R Markdown document, **it is fine to do your initial work in an R script.** If you find it easier to write and debug code there, then use that approach. Or if you prefer the [R Markdown lab notebook workflow](http://r4ds.had.co.nz/r-markdown-workflow.html), then use that. By this point you have enough competence in R to decide what works for you and what does not. **Find what works best for you and do that.**
## Running scripts interactively
You can run sections of your script by highlighting the appropriate code and typing Cmd/Ctrl + Enter. You can also run code expression-by-expression by placing your cursor at the appropriate expression in the script and typing Cmd/Ctrl + Enter. To run the entire script at once, type Cmd/Ctrl + Shift + S or press "Run" at the top of the script editor panel.
## Running scripts programmatically
To run a script saved on your computer, use the `source()` function in the console. As in `source("gun-deaths.R")`. You can also include this command in a second script. By doing this you can execute a sequence of related scripts all in order, rather than having to run each one manually in the console. See [`runfile.R`](https://github.com/uc-cfss/pipeline-example/blob/master/runfile.R) from the `pipeline-example` repo to see this in action. Remember that R scripts (`.R`) are executed via the `source()` function, whereas R Markdown files (`.Rmd`) are executed via the `rmarkdown::render()` function.
> Want to create a report from an R script? Just call `rmarkdown::render("gun-deaths.R")` to author an R Markdown document based on the R script. It will never be as fully featured as if you originally wrote it in an R Markdown document, but can sometimes be handy. Read [this overview](http://rmarkdown.rstudio.com/articles_report_from_r_script.html) for more details on this procedure.
## Running scripts via the shell
You can also run scripts directly from the [shell](shell.html) using `Rscript`:
```bash
Rscript gun-deaths.R
```
To render an R Markdown document from the shell, we use the syntax:
```bash
Rscript -e "rmarkdown::render('gun-deaths.Rmd')"
```
This creates a temporary R script which contains the single command `rmarkdown::render('gun-deaths.Rmd')` and executes it via `Rscript`.
## Exercise: execute R scripts
1. Convert your revised `gun-deaths.Rmd` document into an R script called `gun-deaths.R`.
1. Practice running segments of code interactively
1. Run the entire script via the `source()` function
1. Use the shell to run `gun-deaths.R`
# Session Info {.toc-ignore}
```{r child='_sessioninfo.Rmd'}
```